Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features

0
Sign in to get full access
Overview
- This research paper proposes a method for improving multilingual neural machine translation by incorporating semantic and linguistic features.
- The key idea is to leverage additional information beyond just the source and target sentences to enhance the translation performance.
- The authors experiment with various techniques, including incorporating lexical, syntactic, and semantic information into the neural network architecture.
Plain English Explanation
The paper focuses on improving multilingual neural machine translation, which is the process of automatically translating text between multiple languages using deep learning models. The researchers hypothesize that by incorporating additional linguistic and semantic information, they can enhance the translation quality compared to standard neural machine translation approaches.
Specifically, the authors explore ways to inject lexical, syntactic, and semantic knowledge into the neural network architecture. This could include things like the meanings of individual words, the grammatical structure of the sentences, and the overall context and meaning of the text.
The idea is that this extra information can help the model better understand the nuances of language and produce more accurate and natural-sounding translations, especially for challenging language pairs or low-resource scenarios. The authors test their approach on several language translation tasks and compare the results to baseline neural machine translation models.
Technical Explanation
The paper begins by providing background on multilingual neural machine translation and the challenges of incorporating linguistic knowledge into these models. The authors then describe their proposed approach, which involves integrating lexical, syntactic, and semantic features into the neural network architecture.
Specifically, they experiment with techniques like:
- Incorporating word embeddings that capture semantic meanings
- Leveraging syntactic parse trees to model sentence structure
- Using language models to provide contextual information
The authors evaluate their approach on several multilingual translation benchmarks, comparing the performance to standard Transformer-based neural machine translation models. The results show that incorporating the proposed linguistic and semantic features can lead to consistent improvements in translation quality, as measured by metrics like BLEU score.
The paper also discusses some of the limitations of their work, such as the computational overhead of the additional feature extraction and the potential for overfitting on specific language pairs. The authors suggest directions for future research, such as exploring more efficient ways to integrate the linguistic knowledge or applying the techniques to other multilingual language tasks.
Critical Analysis
The paper presents a well-designed and thorough investigation into leveraging linguistic and semantic information to enhance multilingual neural machine translation. The authors make a compelling case for the value of this approach and provide experimental evidence to support their claims.
One potential limitation is the computational complexity introduced by the additional feature extraction and integration steps. While the performance gains are meaningful, the increased model complexity and training time may be a concern for some practical applications. The authors acknowledge this trade-off and suggest exploring more efficient ways to incorporate the linguistic knowledge.
Additionally, the paper focuses on evaluating the approach on standard benchmarks, but it would be interesting to see how it performs in real-world, low-resource translation scenarios. The authors mention this as a direction for future work, which could further demonstrate the practical benefits of their method.
Overall, the research presented in this paper represents a valuable contribution to the field of multilingual natural language processing. The insights and techniques could inspire further work on leveraging linguistic and semantic knowledge to improve various language-related tasks beyond just translation.
Conclusion
This research paper proposes an innovative approach to improving multilingual neural machine translation by incorporating semantic and linguistic features into the neural network architecture. The results demonstrate that leveraging additional information beyond just the source and target sentences can lead to consistent improvements in translation quality.
The authors' work highlights the potential benefits of integrating linguistic knowledge into deep learning models for language tasks. While the increased computational complexity is a consideration, the performance gains suggest that this is a promising direction for further research and development in the field of multilingual natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features
Mengyu Bu, Shuhao Gu, Yang Feng
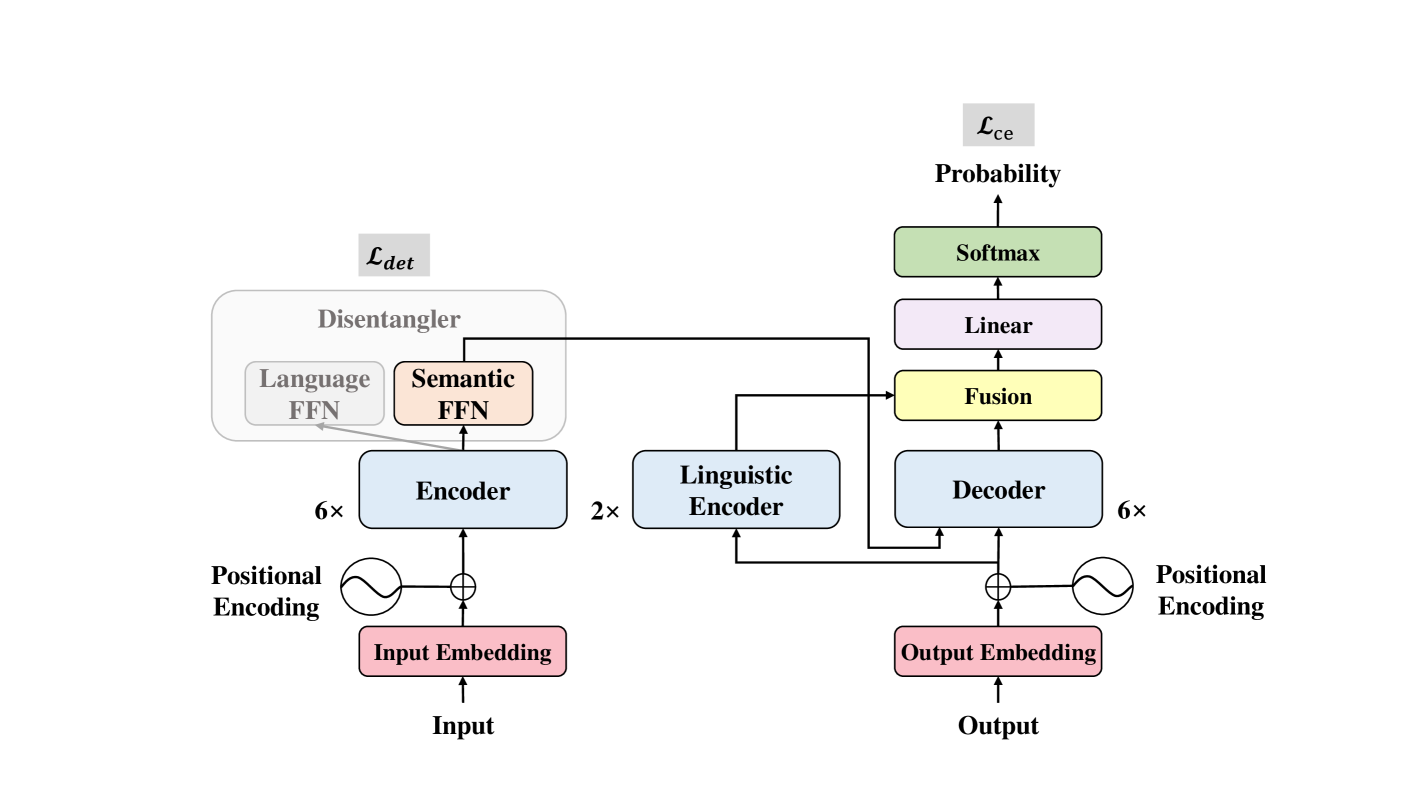
The many-to-many multilingual neural machine translation can be regarded as the process of integrating semantic features from the source sentences and linguistic features from the target sentences. To enhance zero-shot translation, models need to share knowledge across languages, which can be achieved through auxiliary tasks for learning a universal representation or cross-lingual mapping. To this end, we propose to exploit both semantic and linguistic features between multiple languages to enhance multilingual translation. On the encoder side, we introduce a disentangling learning task that aligns encoder representations by disentangling semantic and linguistic features, thus facilitating knowledge transfer while preserving complete information. On the decoder side, we leverage a linguistic encoder to integrate low-level linguistic features to assist in the target language generation. Experimental results on multilingual datasets demonstrate significant improvement in zero-shot translation compared to the baseline system, while maintaining performance in supervised translation. Further analysis validates the effectiveness of our method in leveraging both semantic and linguistic features. The code is available at https://github.com/ictnlp/SemLing-MNMT.
Read more8/6/2024
🤷
0
Incorporating Lexical and Syntactic Knowledge for Unsupervised Cross-Lingual Transfer
Jianyu Zheng, Fengfei Fan, Jianquan Li
Unsupervised cross-lingual transfer involves transferring knowledge between languages without explicit supervision. Although numerous studies have been conducted to improve performance in such tasks by focusing on cross-lingual knowledge, particularly lexical and syntactic knowledge, current approaches are limited as they only incorporate syntactic or lexical information. Since each type of information offers unique advantages and no previous attempts have combined both, we attempt to explore the potential of this approach. In this paper, we present a novel framework called Lexicon-Syntax Enhanced Multilingual BERT that combines both lexical and syntactic knowledge. Specifically, we use Multilingual BERT (mBERT) as the base model and employ two techniques to enhance its learning capabilities. The code-switching technique is used to implicitly teach the model lexical alignment information, while a syntactic-based graph attention network is designed to help the model encode syntactic structure. To integrate both types of knowledge, we input code-switched sequences into both the syntactic module and the mBERT base model simultaneously. Our extensive experimental results demonstrate this framework can consistently outperform all baselines of zero-shot cross-lingual transfer, with the gains of 1.0~3.7 points on text classification, named entity recognition (ner), and semantic parsing tasks. Keywords:cross-lingual transfer, lexicon, syntax, code-switching, graph attention network
Read more4/26/2024

0
Cross-Lingual Transfer Learning for Speech Translation
Rao Ma, Yassir Fathullah, Mengjie Qian, Siyuan Tang, Mark Gales, Kate Knill
There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.
Read more7/2/2024

0
A Data Selection Approach for Enhancing Low Resource Machine Translation Using Cross-Lingual Sentence Representations
Nidhi Kowtal, Tejas Deshpande, Raviraj Joshi
Machine translation in low-resource language pairs faces significant challenges due to the scarcity of parallel corpora and linguistic resources. This study focuses on the case of English-Marathi language pairs, where existing datasets are notably noisy, impeding the performance of machine translation models. To mitigate the impact of data quality issues, we propose a data filtering approach based on cross-lingual sentence representations. Our methodology leverages a multilingual SBERT model to filter out problematic translations in the training data. Specifically, we employ an IndicSBERT similarity model to assess the semantic equivalence between original and translated sentences, allowing us to retain linguistically correct translations while discarding instances with substantial deviations. The results demonstrate a significant improvement in translation quality over the baseline post-filtering with IndicSBERT. This illustrates how cross-lingual sentence representations can reduce errors in machine translation scenarios with limited resources. By integrating multilingual sentence BERT models into the translation pipeline, this research contributes to advancing machine translation techniques in low-resource environments. The proposed method not only addresses the challenges in English-Marathi language pairs but also provides a valuable framework for enhancing translation quality in other low-resource language translation tasks.
Read more9/5/2024