Improving Online Source-free Domain Adaptation for Object Detection by Unsupervised Data Acquisition

0
🔎
Sign in to get full access
Overview
- Object detection in autonomous vehicles is challenging due to deployment in diverse and unfamiliar environments.
- Online Source-Free Domain Adaptation (O-SFDA) can adapt models using unlabeled data from the target domain.
- However, not all captured frames contain useful information for adaptation, especially with redundant data and class imbalance.
Plain English Explanation
Self-driving cars use object detection models to identify things like pedestrians, other vehicles, and obstacles. But these models can struggle when the car is driven in new environments that are different from the data the model was trained on. Online Source-Free Domain Adaptation (O-SFDA) is a technique that can help adapt the model by using unlabeled data collected by the car as it drives.
However, not all of the data collected by the car is equally useful for adapting the model. There may be a lot of redundant or irrelevant frames, and the distribution of objects in the data may not match the real world. This paper introduces a new approach to prioritize the most informative frames for the adaptation process. By focusing on the most useful data, the adapted object detection model can perform better in the new environment.
Technical Explanation
This paper proposes a novel method to enhance O-SFDA for improving adaptive object detection. The key idea is to prioritize the most informative unlabeled frames from the target domain for inclusion in the online training process.
The authors first analyze the characteristics of the unlabeled target data, identifying issues like redundancy and class imbalance that can hinder effective adaptation. They then design an unsupervised data acquisition strategy to select the most valuable frames. This involves calculating uncertainty scores for each frame and using them to determine which frames to use for updating the object detection model.
Experiments on a real-world dataset show that this approach outperforms existing state-of-the-art O-SFDA techniques. By intelligently selecting the most informative data, the adapted object detector is able to perform better in the new environment compared to using all the unlabeled data indiscriminately.
Critical Analysis
The paper identifies an important practical challenge in deploying adaptive object detection systems - not all of the unlabeled data collected in the field is equally useful for model adaptation. The authors' approach of prioritizing the most informative frames is a clever way to address this issue.
However, the paper does not provide a deep analysis of the potential limitations or failure modes of their method. For example, it's not clear how robust the frame selection process is to different types of data distribution shifts or noise in the unlabeled target data. Additional research may be needed to better understand the boundary conditions and failure cases of this approach.
Furthermore, the real-world dataset used for evaluation, while valuable, may not fully capture the diversity of environments and conditions that autonomous vehicles could encounter in practice. Broader testing across a wider range of scenarios would help validate the broader applicability of this technique.
Overall, this paper presents a promising step forward in enabling more effective domain adaptation for object detection in autonomous vehicles. But further research is needed to fully understand the strengths and limitations of this approach.
Conclusion
This paper introduces a novel method to enhance online source-free domain adaptation for object detection in autonomous vehicles. By prioritizing the most informative unlabeled frames from the target domain, the approach is able to outperform existing state-of-the-art techniques.
This work highlights the importance of selective data acquisition for effective model adaptation, especially in the presence of redundant or imbalanced data. The insights from this research could help drive further advancements in adaptive object detection, enabling self-driving cars to perform reliably in diverse and unfamiliar environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Improving Online Source-free Domain Adaptation for Object Detection by Unsupervised Data Acquisition
Xiangyu Shi, Yanyuan Qiao, Qi Wu, Lingqiao Liu, Feras Dayoub
Effective object detection in autonomous vehicles is challenged by deployment in diverse and unfamiliar environments. Online Source-Free Domain Adaptation (O-SFDA) offers model adaptation using a stream of unlabeled data from a target domain in an online manner. However, not all captured frames contain information beneficial for adaptation, especially in the presence of redundant data and class imbalance issues. This paper introduces a novel approach to enhance O-SFDA for adaptive object detection through unsupervised data acquisition. Our methodology prioritizes the most informative unlabeled frames for inclusion in the online training process. Empirical evaluation on a real-world dataset reveals that our method outperforms existing state-of-the-art O-SFDA techniques, demonstrating the viability of unsupervised data acquisition for improving the adaptive object detector.
Read more9/2/2024
0
Simplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
Yan Hao, Florent Forest, Olga Fink
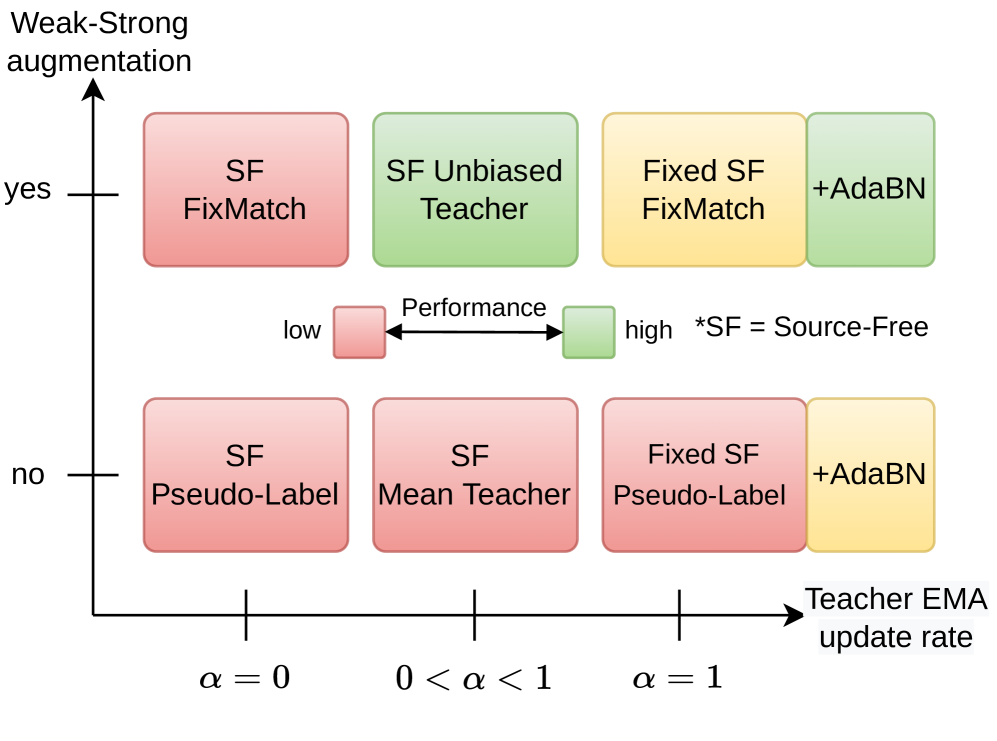
This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7% AP50 on Cityscapes$rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.
Read more7/11/2024
🔎
0
Source-free Domain Adaptation for Video Object Detection Under Adverse Image Conditions
Xingguang Zhang, Chih-Hsien Chou
When deploying pre-trained video object detectors in real-world scenarios, the domain gap between training and testing data caused by adverse image conditions often leads to performance degradation. Addressing this issue becomes particularly challenging when only the pre-trained model and degraded videos are available. Although various source-free domain adaptation (SFDA) methods have been proposed for single-frame object detectors, SFDA for video object detection (VOD) remains unexplored. Moreover, most unsupervised domain adaptation works for object detection rely on two-stage detectors, while SFDA for one-stage detectors, which are more vulnerable to fine-tuning, is not well addressed in the literature. In this paper, we propose Spatial-Temporal Alternate Refinement with Mean Teacher (STAR-MT), a simple yet effective SFDA method for VOD. Specifically, we aim to improve the performance of the one-stage VOD method, YOLOV, under adverse image conditions, including noise, air turbulence, and haze. Extensive experiments on the ImageNetVOD dataset and its degraded versions demonstrate that our method consistently improves video object detection performance in challenging imaging conditions, showcasing its potential for real-world applications.
Read more4/24/2024
👀
0
Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
Wenyu Zhang, Li Shen, Chuan-Sheng Foo
Source-free domain adaptation (SFDA) aims to adapt a source model trained on a fully-labeled source domain to a related but unlabeled target domain. While the source model is a key avenue for acquiring target pseudolabels, the generated pseudolabels may exhibit source bias. In the conventional SFDA pipeline, a large data (e.g. ImageNet) pre-trained feature extractor is used to initialize the source model at the start of source training, and subsequently discarded. Despite having diverse features important for generalization, the pre-trained feature extractor can overfit to the source data distribution during source training and forget relevant target domain knowledge. Rather than discarding this valuable knowledge, we introduce an integrated framework to incorporate pre-trained networks into the target adaptation process. The proposed framework is flexible and allows us to plug modern pre-trained networks into the adaptation process to leverage their stronger representation learning capabilities. For adaptation, we propose the Co-learn algorithm to improve target pseudolabel quality collaboratively through the source model and a pre-trained feature extractor. Building on the recent success of the vision-language model CLIP in zero-shot image recognition, we present an extension Co-learn++ to further incorporate CLIP's zero-shot classification decisions. We evaluate on 4 benchmark datasets and include more challenging scenarios such as open-set, partial-set and open-partial SFDA. Experimental results demonstrate that our proposed strategy improves adaptation performance and can be successfully integrated with existing SFDA methods.
Read more8/22/2024