Improving Robustness to Model Inversion Attacks via Sparse Coding Architectures

0
Sign in to get full access
Overview
- Explores using sparse coding architectures (SCAs) to improve the robustness of machine learning models against model inversion attacks
- Model inversion attacks aim to reconstruct training data from a model's parameters, posing a privacy risk
- SCAs, which use sparse representations, can make it harder for attackers to recover the original training data
Plain English Explanation
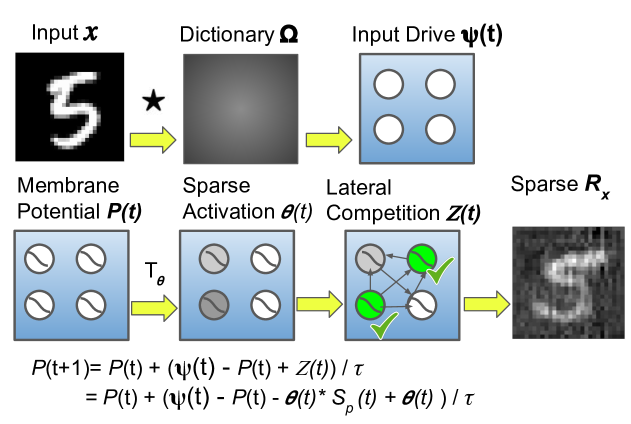
Sparse coding architectures (SCAs) are a type of machine learning model that use sparse representations - meaning they only activate a small number of their internal components at a time. This can help make these models more robust against adversarial attacks that aim to reconstruct the original training data, which is a privacy risk known as a model inversion attack.
The key idea is that the sparse representations in SCAs make it harder for attackers to "invert" the model and recover the original training data. Instead of having a dense set of interconnected components that could be analyzed to extract the training data, SCAs only activate a small subset of their components at a time. This makes it much more difficult for attackers to piece together the original data.
Technical Explanation
This paper investigates using sparse coding architectures (SCAs) as a defense against model inversion attacks. Model inversion attacks aim to reconstruct the training data used to build a machine learning model by analyzing the model's parameters. This poses a significant privacy risk, as the training data may contain sensitive information about individuals.
The researchers hypothesized that the sparse representations used in SCAs could make them more robust to these types of attacks. To test this, they designed experiments to evaluate the performance of SCAs compared to dense, fully-connected neural networks when subjected to model inversion attacks.
Their results showed that SCAs were indeed more resistant to model inversion attacks than the dense neural networks. The sparse activations in SCAs made it much harder for attackers to recover the original training data, even when the attacker had full access to the model's parameters.
The researchers also explored different SCA designs and found that certain architectural choices, such as the use of overcomplete dictionaries, further enhanced the models' robustness to inversion attacks.
Critical Analysis
The paper provides a compelling case for using sparse coding architectures as a defense against model inversion attacks. By leveraging the inherent properties of sparse representations, the researchers demonstrate a practical approach to improving the privacy-preserving capabilities of machine learning models.
However, the study does not explore the potential drawbacks or limitations of this approach. For example, it's unclear how the use of SCAs may impact the model's overall performance or training efficiency compared to dense neural networks. Additionally, the paper does not consider the possibility of attackers developing more sophisticated inversion techniques that could potentially overcome the defenses provided by SCAs.
Further research is needed to fully understand the trade-offs and long-term viability of this approach. Exploring the performance implications, as well as the robustness of SCAs against more advanced attack methods, would help provide a more comprehensive evaluation of this defense strategy.
Conclusion
This paper presents a promising approach to enhancing the privacy-preserving properties of machine learning models by using sparse coding architectures. The sparse representations in SCAs make it significantly harder for attackers to recover the original training data through model inversion attacks, a critical privacy concern in the field of AI.
While the results are encouraging, further research is needed to fully understand the practical implications and potential limitations of this defense strategy. Nonetheless, this work highlights the importance of considering privacy and security aspects in the design of machine learning systems, and the potential of architectural choices, such as sparse coding, to address these challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Robustness to Model Inversion Attacks via Sparse Coding Architectures
Sayanton V. Dibbo, Adam Breuer, Juston Moore, Michael Teti
Recent model inversion attack algorithms permit adversaries to reconstruct a neural network's private and potentially sensitive training data by repeatedly querying the network. In this work, we develop a novel network architecture that leverages sparse-coding layers to obtain superior robustness to this class of attacks. Three decades of computer science research has studied sparse coding in the context of image denoising, object recognition, and adversarial misclassification settings, but to the best of our knowledge, its connection to state-of-the-art privacy vulnerabilities remains unstudied. In this work, we hypothesize that sparse coding architectures suggest an advantageous means to defend against model inversion attacks because they allow us to control the amount of irrelevant private information encoded by a network in a manner that is known to have little effect on classification accuracy. Specifically, compared to networks trained with a variety of state-of-the-art defenses, our sparse-coding architectures maintain comparable or higher classification accuracy while degrading state-of-the-art training data reconstructions by factors of 1.1 to 18.3 across a variety of reconstruction quality metrics (PSNR, SSIM, FID). This performance advantage holds across 5 datasets ranging from CelebA faces to medical images and CIFAR-10, and across various state-of-the-art SGD-based and GAN-based inversion attacks, including Plug-&-Play attacks. We provide a cluster-ready PyTorch codebase to promote research and standardize defense evaluations.
Read more8/27/2024

0
BrainLeaks: On the Privacy-Preserving Properties of Neuromorphic Architectures against Model Inversion Attacks
Hamed Poursiami, Ihsen Alouani, Maryam Parsa
With the mainstream integration of machine learning into security-sensitive domains such as healthcare and finance, concerns about data privacy have intensified. Conventional artificial neural networks (ANNs) have been found vulnerable to several attacks that can leak sensitive data. Particularly, model inversion (MI) attacks enable the reconstruction of data samples that have been used to train the model. Neuromorphic architectures have emerged as a paradigm shift in neural computing, enabling asynchronous and energy-efficient computation. However, little to no existing work has investigated the privacy of neuromorphic architectures against model inversion. Our study is motivated by the intuition that the non-differentiable aspect of spiking neural networks (SNNs) might result in inherent privacy-preserving properties, especially against gradient-based attacks. To investigate this hypothesis, we propose a thorough exploration of SNNs' privacy-preserving capabilities. Specifically, we develop novel inversion attack strategies that are comprehensively designed to target SNNs, offering a comparative analysis with their conventional ANN counterparts. Our experiments, conducted on diverse event-based and static datasets, demonstrate the effectiveness of the proposed attack strategies and therefore questions the assumption of inherent privacy-preserving in neuromorphic architectures.
Read more5/8/2024
🧠
0
Sparsity in neural networks can improve their privacy
Antoine Gonon (OCKHAM, ARIC), L'eon Zheng (OCKHAM), Cl'ement Lalanne (OCKHAM), Quoc-Tung Le (OCKHAM), Guillaume Lauga (OCKHAM), Can Pouliquen (OCKHAM)
This article measures how sparsity can make neural networks more robust to membership inference attacks. The obtained empirical results show that sparsity improves the privacy of the network, while preserving comparable performances on the task at hand. This empirical study completes and extends existing literature.
Read more6/12/2024

0
Enhancing Adversarial Robustness in SNNs with Sparse Gradients
Yujia Liu, Tong Bu, Jianhao Ding, Zecheng Hao, Tiejun Huang, Zhaofei Yu
Spiking Neural Networks (SNNs) have attracted great attention for their energy-efficient operations and biologically inspired structures, offering potential advantages over Artificial Neural Networks (ANNs) in terms of energy efficiency and interpretability. Nonetheless, similar to ANNs, the robustness of SNNs remains a challenge, especially when facing adversarial attacks. Existing techniques, whether adapted from ANNs or specifically designed for SNNs, exhibit limitations in training SNNs or defending against strong attacks. In this paper, we propose a novel approach to enhance the robustness of SNNs through gradient sparsity regularization. We observe that SNNs exhibit greater resilience to random perturbations compared to adversarial perturbations, even at larger scales. Motivated by this, we aim to narrow the gap between SNNs under adversarial and random perturbations, thereby improving their overall robustness. To achieve this, we theoretically prove that this performance gap is upper bounded by the gradient sparsity of the probability associated with the true label concerning the input image, laying the groundwork for a practical strategy to train robust SNNs by regularizing the gradient sparsity. We validate the effectiveness of our approach through extensive experiments on both image-based and event-based datasets. The results demonstrate notable improvements in the robustness of SNNs. Our work highlights the importance of gradient sparsity in SNNs and its role in enhancing robustness.
Read more6/3/2024