Improving Text-guided Object Inpainting with Semantic Pre-inpainting

0

Sign in to get full access
Overview
- This paper proposes a new approach to text-guided object inpainting using semantic pre-inpainting.
- The goal is to improve the quality and fidelity of object inpainting compared to existing methods.
- The key idea is to first generate a semantic map of the object to be inpainted, and then use that to guide the inpainting process.
Plain English Explanation
Text-guided object inpainting is a technique that allows you to remove an object from an image and have it automatically filled in based on the surrounding context and a text description of what should be there. For example, if you had an image with a car in it and you wanted to remove the car, you could provide a text description like "a tree should be in that spot" and the system would try to intelligently fill in the missing area with a tree.
The approach proposed in this paper aims to improve the quality of this text-guided object inpainting process. The key idea is to first generate a semantic map of the object to be inpainted. This means creating a detailed understanding of the different elements that make up the object, like its shape, textures, and relationship to the surrounding scene.
The system then uses this semantic information to guide the actual inpainting process, resulting in more coherent and realistic filling of the missing area. Rather than just trying to blend in the new content, the semantic pre-inpainting allows the system to better understand what should be there and generate a more natural result.
Overall, this approach can make text-guided object removal and replacement significantly more effective, allowing users to seamlessly edit images in a way that looks natural and believable.
Technical Explanation
The paper introduces a new framework for text-guided object inpainting that uses semantic pre-inpainting to improve the quality of the results. The key components are:
-
Semantic Encoder: This module takes the input image and the provided text description as input, and generates a detailed semantic map of the object to be inpainted. This captures information about the object's shape, texture, and relationship to the rest of the scene.
-
Inpainting Diffusion Model: This is the core inpainting module that uses a diffusion-based approach to generate the final inpainted image. The key innovation is that it uses the semantic map from the previous step to guide the inpainting process, resulting in more coherent and realistic outputs.
-
Training Procedure: The model is trained end-to-end on a dataset of images with simulated occlusions. The training loss combines an adversarial loss to ensure realism, a perceptual loss to preserve semantic consistency, and a mask loss to accurately predict the inpainted region.
Experiments show that this approach significantly outperforms previous state-of-the-art text-guided inpainting methods, both in terms of visual quality and semantic fidelity. The semantic pre-inpainting is a critical component that allows the system to better understand the context and generate more plausible results.
Critical Analysis
The paper presents a compelling approach to improving text-guided object inpainting, with thorough experimental validation and compelling results. However, there are a few potential limitations and areas for further research:
-
Generalization to Complex Scenes: The current approach focuses on relatively simple scenes with a single prominent object to be inpainted. It's unclear how well it would scale to more complex, cluttered environments with multiple interacting objects.
-
Handling of Occlusions: The paper assumes the object to be inpainted is fully occluded. It's not clear how the approach would handle partial occlusions or situations where the object boundaries are ambiguous.
-
Computational Efficiency: Generating a detailed semantic map and then using that to guide the inpainting diffusion model may be computationally expensive, limiting its real-world applicability. Strategies for improving efficiency could be explored.
-
Qualitative User Evaluation: While the paper provides compelling quantitative results, user studies to assess the perceived realism and usefulness of the inpainted results could provide additional insights.
Overall, this paper presents an innovative and promising approach to text-guided object inpainting that leverages semantic understanding to generate more coherent and realistic results. Further research to address the limitations mentioned could help unlock the full potential of this technique.
Conclusion
This paper introduces a new framework for text-guided object inpainting that uses semantic pre-inpainting to significantly improve the quality and fidelity of the inpainted results. By first generating a detailed semantic map of the object to be removed, the system is able to better understand the context and generate more plausible content to fill the missing area.
The key innovation is the integration of this semantic pre-inpainting step with a diffusion-based inpainting model, allowing the high-level understanding to guide the low-level generation process. Experiments show this approach outperforms previous state-of-the-art methods, opening up new possibilities for seamless image editing and manipulation.
While there are some limitations that could be addressed through future research, this work represents an important step forward in advancing the capabilities of text-guided object inpainting, with potential applications in fields like digital content creation, photography, and even virtual/augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Yifu Chen, Jingwen Chen, Yingwei Pan, Yehao Li, Ting Yao, Zhineng Chen, Tao Mei
Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at url{https://github.com/Nnn-s/CATdiffusion}.
Read more9/14/2024

0
Salient Object-Aware Background Generation using Text-Guided Diffusion Models
Amir Erfan Eshratifar, Joao V. B. Soares, Kapil Thadani, Shaunak Mishra, Mikhail Kuznetsov, Yueh-Ning Ku, Paloma de Juan
Generating background scenes for salient objects plays a crucial role across various domains including creative design and e-commerce, as it enhances the presentation and context of subjects by integrating them into tailored environments. Background generation can be framed as a task of text-conditioned outpainting, where the goal is to extend image content beyond a salient object's boundaries on a blank background. Although popular diffusion models for text-guided inpainting can also be used for outpainting by mask inversion, they are trained to fill in missing parts of an image rather than to place an object into a scene. Consequently, when used for background creation, inpainting models frequently extend the salient object's boundaries and thereby change the object's identity, which is a phenomenon we call object expansion. This paper introduces a model for adapting inpainting diffusion models to the salient object outpainting task using Stable Diffusion and ControlNet architectures. We present a series of qualitative and quantitative results across models and datasets, including a newly proposed metric to measure object expansion that does not require any human labeling. Compared to Stable Diffusion 2.0 Inpainting, our proposed approach reduces object expansion by 3.6x on average with no degradation in standard visual metrics across multiple datasets.
Read more4/17/2024

1
Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model
Lirui Zhao, Tianshuo Yang, Wenqi Shao, Yuxin Zhang, Yu Qiao, Ping Luo, Kaipeng Zhang, Rongrong Ji
This paper addresses an important problem of object addition for images with only text guidance. It is challenging because the new object must be integrated seamlessly into the image with consistent visual context, such as lighting, texture, and spatial location. While existing text-guided image inpainting methods can add objects, they either fail to preserve the background consistency or involve cumbersome human intervention in specifying bounding boxes or user-scribbled masks. To tackle this challenge, we introduce Diffree, a Text-to-Image (T2I) model that facilitates text-guided object addition with only text control. To this end, we curate OABench, an exquisite synthetic dataset by removing objects with advanced image inpainting techniques. OABench comprises 74K real-world tuples of an original image, an inpainted image with the object removed, an object mask, and object descriptions. Trained on OABench using the Stable Diffusion model with an additional mask prediction module, Diffree uniquely predicts the position of the new object and achieves object addition with guidance from only text. Extensive experiments demonstrate that Diffree excels in adding new objects with a high success rate while maintaining background consistency, spatial appropriateness, and object relevance and quality.
Read more7/25/2024
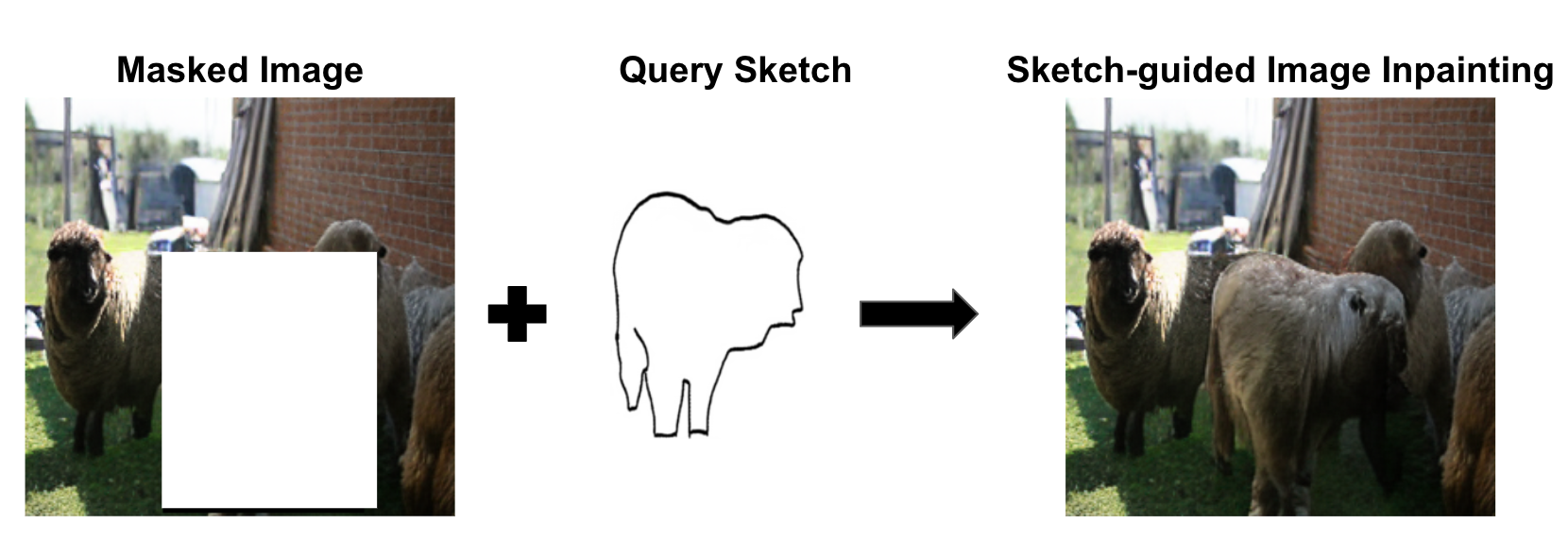
0
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Read more4/19/2024