Independently Keypoint Learning for Small Object Semantic Correspondence
2404.02678
0
0

Abstract
Semantic correspondence remains a challenging task for establishing correspondences between a pair of images with the same category or similar scenes due to the large intra-class appearance. In this paper, we introduce a novel problem called 'Small Object Semantic Correspondence (SOSC).' This problem is challenging due to the close proximity of keypoints associated with small objects, which results in the fusion of these respective features. It is difficult to identify the corresponding key points of the fused features, and it is also difficult to be recognized. To address this challenge, we propose the Keypoint Bounding box-centered Cropping (KBC) method, which aims to increase the spatial separation between keypoints of small objects, thereby facilitating independent learning of these keypoints. The KBC method is seamlessly integrated into our proposed inference pipeline and can be easily incorporated into other methodologies, resulting in significant performance enhancements. Additionally, we introduce a novel framework, named KBCNet, which serves as our baseline model. KBCNet comprises a Cross-Scale Feature Alignment (CSFA) module and an efficient 4D convolutional decoder. The CSFA module is designed to align multi-scale features, enriching keypoint representations by integrating fine-grained features and deep semantic features. Meanwhile, the 4D convolutional decoder, based on efficient 4D convolution, ensures efficiency and rapid convergence. To empirically validate the effectiveness of our proposed methodology, extensive experiments are conducted on three widely used benchmarks: PF-PASCAL, PF-WILLOW, and SPair-71k. Our KBC method demonstrates a substantial performance improvement of 7.5% on the SPair-71K dataset, providing compelling evidence of its efficacy.
Create account to get full access
Overview
- This paper proposes a new method for small object semantic correspondence, which is the task of identifying corresponding points between similar objects in different images.
- The key idea is to learn keypoint detectors and descriptors independently, rather than jointly as in previous approaches.
- The authors show this independent learning leads to better performance on small objects compared to joint learning.
- They evaluate the method on several benchmarks and demonstrate improved results over state-of-the-art approaches.
Plain English Explanation
The paper focuses on the problem of identifying matching points between similar objects in different images, even when the objects are small. This is called semantic correspondence, and it's useful for tasks like object recognition, image retrieval, and 3D reconstruction.
Previous methods have tried to learn keypoint detectors and descriptors - the algorithms that identify and describe distinctive points on an object - together in a single model. The authors argue this joint learning approach doesn't work as well for small objects, where the distinctive features are more subtle and harder to capture.
Instead, the researchers propose learning the detector and descriptor models independently. This allows the models to specialize and focus on the different aspects of the task - the detector finds the important keypoints, while the descriptor learns how to uniquely represent them. By separating these components, the method is better able to handle the challenges of small objects.
The authors test their approach on several benchmarks and show it outperforms the current state-of-the-art techniques. This suggests the independent learning strategy is a valuable advance for enabling semantic correspondence, especially for applications involving small objects.
Technical Explanation
The key technical contributions of the paper are:
-
Independent Keypoint Learning: The authors propose learning the keypoint detector and descriptor models separately, rather than jointly as in previous work. This allows the models to specialize and focus on the different aspects of the task.
-
Keypoint Detector: The detector model is based on a convolutional neural network that predicts keypoint heatmaps. It is trained to identify the most distinctive points on the object.
-
Keypoint Descriptor: The descriptor model is also a convolutional network that learns compact feature representations for the detected keypoints. It is trained to make these descriptors discriminative for matching.
-
Training Procedure: The detector and descriptor models are trained sequentially. First the detector is trained on keypoint annotations. Then the descriptor is trained using the detected keypoints, with a contrastive loss to push similar keypoints together and dissimilar ones apart.
-
Benchmarking: The authors evaluate their method on several semantic correspondence datasets, including tasks with small objects. They show consistent improvements over state-of-the-art joint detection and description approaches.
Critical Analysis
The paper makes a convincing case that independent learning of keypoint detectors and descriptors is beneficial for small object correspondence. The results demonstrate clear performance gains over prior joint learning methods across multiple benchmarks.
That said, the paper does not extensively explore the limitations of the proposed approach. For example, it is unclear how the independent learning strategy would scale to larger, more complex objects, or whether there are computation/memory tradeoffs compared to joint learning.
Additionally, the authors do not discuss how robust the method is to factors like occlusion, viewpoint changes, or background clutter - all of which can be challenging for semantic correspondence. Further investigation into the failure modes and generalization capability of the approach would strengthen the analysis.
Overall, this work represents an insightful technical contribution that advances the state-of-the-art in small object correspondence. The principle of specialized detector and descriptor models is compelling and worth further exploration. Examining the approach's limitations and boundary conditions could lead to even more robust and widely applicable solutions.
Conclusion
This paper introduces a new method for learning semantic correspondences, especially for small objects. By separating the keypoint detection and description into independent models, the approach is able to better handle the challenges of subtle features and limited training data for small instances.
The results demonstrate significant performance gains over previous joint learning techniques across multiple benchmarks. This suggests the independent learning strategy is a valuable advancement that could enable more accurate object recognition, image retrieval, and 3D reconstruction, particularly in real-world scenarios involving small or detailed objects.
While the paper does not fully explore the approach's limitations, the core idea of specialized detector and descriptor models is an intriguing concept that merits further research. Investigating the method's robustness and scalability could lead to even more powerful and versatile semantic correspondence solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Self-supervised co-salient object detection via feature correspondence at multiple scales
Souradeep Chakraborty, Dimitris Samaras
0
0
Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).
7/4/2024
👀
Learning Correspondence for Deformable Objects
Priya Sundaresan, Aditya Ganapathi, Harry Zhang, Shivin Devgon
0
0
We investigate the problem of pixelwise correspondence for deformable objects, namely cloth and rope, by comparing both classical and learning-based methods. We choose cloth and rope because they are traditionally some of the most difficult deformable objects to analytically model with their large configuration space, and they are meaningful in the context of robotic tasks like cloth folding, rope knot-tying, T-shirt folding, curtain closing, etc. The correspondence problem is heavily motivated in robotics, with wide-ranging applications including semantic grasping, object tracking, and manipulation policies built on top of correspondences. We present an exhaustive survey of existing classical methods for doing correspondence via feature-matching, including SIFT, SURF, and ORB, and two recently published learning-based methods including TimeCycle and Dense Object Nets. We make three main contributions: (1) a framework for simulating and rendering synthetic images of deformable objects, with qualitative results demonstrating transfer between our simulated and real domains (2) a new learning-based correspondence method extending Dense Object Nets, and (3) a standardized comparison across state-of-the-art correspondence methods. Our proposed method provides a flexible, general formulation for learning temporally and spatially continuous correspondences for nonrigid (and rigid) objects. We report root mean squared error statistics for all methods and find that Dense Object Nets outperforms baseline classical methods for correspondence, and our proposed extension of Dense Object Nets performs similarly.
5/29/2024
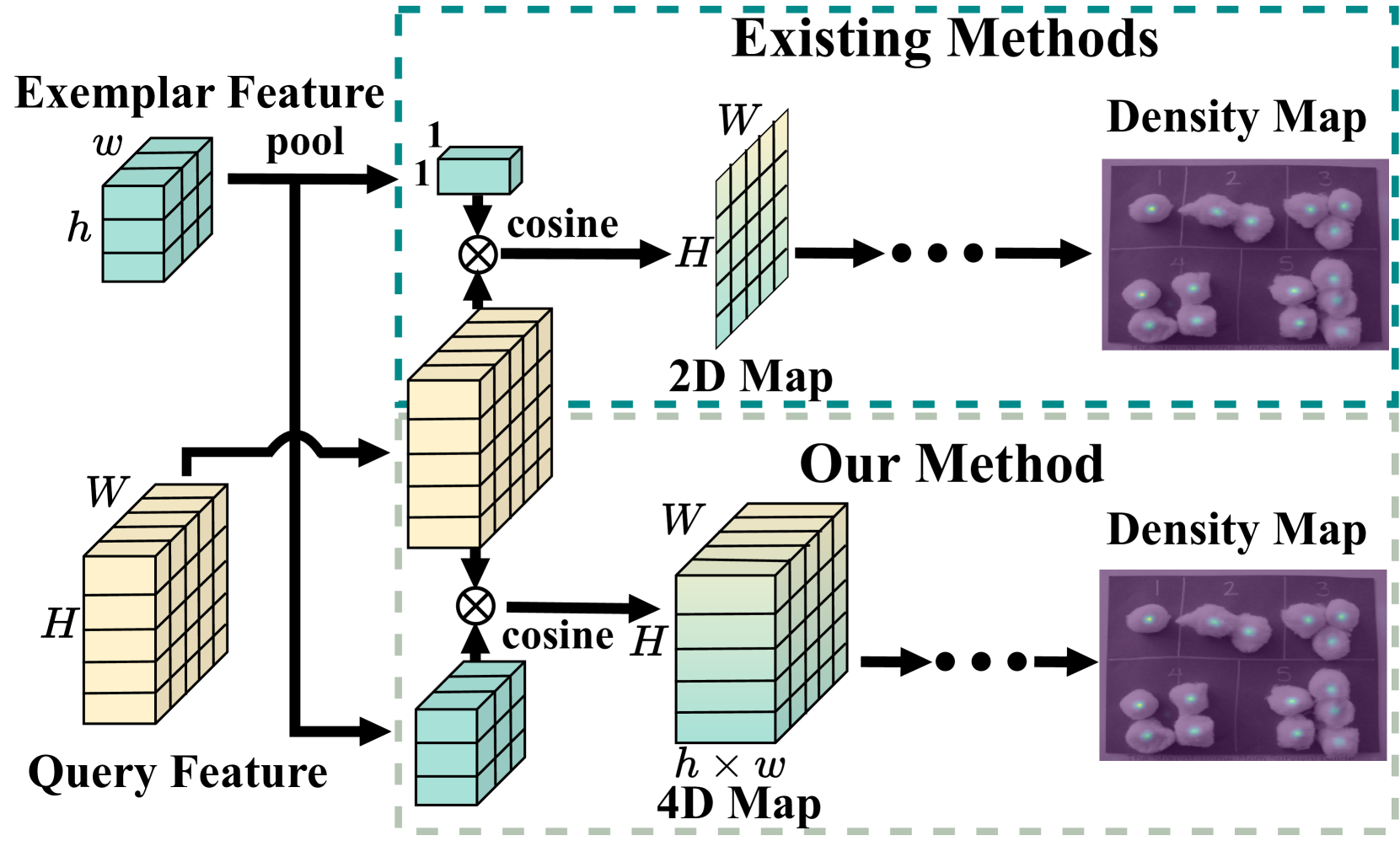
Learning Spatial Similarity Distribution for Few-shot Object Counting
Yuanwu Xu, Feifan Song, Haofeng Zhang
0
0
Few-shot object counting aims to count the number of objects in a query image that belong to the same class as the given exemplar images. Existing methods compute the similarity between the query image and exemplars in the 2D spatial domain and perform regression to obtain the counting number. However, these methods overlook the rich information about the spatial distribution of similarity on the exemplar images, leading to significant impact on matching accuracy. To address this issue, we propose a network learning Spatial Similarity Distribution (SSD) for few-shot object counting, which preserves the spatial structure of exemplar features and calculates a 4D similarity pyramid point-to-point between the query features and exemplar features, capturing the complete distribution information for each point in the 4D similarity space. We propose a Similarity Learning Module (SLM) which applies the efficient center-pivot 4D convolutions on the similarity pyramid to map different similarity distributions to distinct predicted density values, thereby obtaining accurate count. Furthermore, we also introduce a Feature Cross Enhancement (FCE) module that enhances query and exemplar features mutually to improve the accuracy of feature matching. Our approach outperforms state-of-the-art methods on multiple datasets, including FSC-147 and CARPK. Code is available at https://github.com/CBalance/SSD.
5/21/2024

Learning Tracking Representations from Single Point Annotations
Qiangqiang Wu, Antoni B. Chan
0
0
Existing deep trackers are typically trained with largescale video frames with annotated bounding boxes. However, these bounding boxes are expensive and time-consuming to annotate, in particular for large scale datasets. In this paper, we propose to learn tracking representations from single point annotations (i.e., 4.5x faster to annotate than the traditional bounding box) in a weakly supervised manner. Specifically, we propose a soft contrastive learning (SoCL) framework that incorporates target objectness prior into end-to-end contrastive learning. Our SoCL consists of adaptive positive and negative sample generation, which is memory-efficient and effective for learning tracking representations. We apply the learned representation of SoCL to visual tracking and show that our method can 1) achieve better performance than the fully supervised baseline trained with box annotations under the same annotation time cost; 2) achieve comparable performance of the fully supervised baseline by using the same number of training frames and meanwhile reducing annotation time cost by 78% and total fees by 85%; 3) be robust to annotation noise.
4/16/2024