Learning Tracking Representations from Single Point Annotations

0
Sign in to get full access
Overview
- The paper presents a method for learning tracking representations from single point annotations, which can be used to track objects in videos.
- The approach involves training a neural network model to predict the position of an object in future frames given only a single point annotation in the initial frame.
- The authors demonstrate that this method can achieve state-of-the-art performance on a variety of video object tracking benchmarks.
Plain English Explanation
The researchers have developed a new way to track objects in videos using a machine learning model. Typically, object tracking requires annotating the full object boundaries in each frame of a video, which is a time-consuming and labor-intensive process. This paper presents a method that only requires a single point annotation – just clicking on the object in the first frame.
The model then learns to use this single point to predict where the object will be in future frames, allowing it to track the object throughout the video. This is a much more efficient approach compared to annotating the full object in every frame. The authors show that their model can achieve [object Object], demonstrating the effectiveness of this single-point tracking approach.
The key insight is that the model can learn a "tracking representation" from just a single point, which encodes information about the object's appearance, motion, and context that allows it to be localized in subsequent frames. This tracking representation is more efficient and generalizable than traditional approaches that require full object annotations.
Technical Explanation
The paper introduces a novel framework for [object Object]. The core idea is to train a neural network model to predict the future position of an object in a video given only a single point annotation in the initial frame.
The model architecture consists of several key components:
- Feature Encoder: This module takes the video frame and the single point annotation as input and produces a high-dimensional feature representation.
- Tracking Head: This sub-network uses the feature representation to predict the future location of the object in subsequent frames.
- Tracking Loss: The model is trained end-to-end using a custom tracking loss function that penalizes deviations between the predicted and ground truth object positions.
By only requiring a single point per object, this approach is much more efficient than traditional tracking methods that need full object annotations for each frame. The authors show that the learned tracking representations are robust and generalize well to new videos, achieving state-of-the-art results on several object tracking benchmarks.
Critical Analysis
The paper presents a compelling approach for object tracking that significantly reduces the annotation burden compared to previous methods. However, there are a few potential limitations and areas for further research:
-
Handling Occlusions: The paper does not explicitly address how the model handles cases where the object becomes occluded or goes off-screen. Additional mechanisms may be needed to robustly track objects in these challenging scenarios.
-
Real-time Performance: While the method achieves high accuracy, the computational complexity of the model is not discussed. Deploying this approach in real-time applications may require further optimizations to ensure efficient inference.
-
Generalization to Novel Objects: The experiments focus on a relatively limited set of object categories. It would be valuable to explore how well the single-point tracking approach generalizes to a broader range of object types, including those not seen during training.
-
User Interaction: The paper does not explore the potential for incorporating user feedback or corrections into the tracking process. Allowing users to refine the predictions could further improve the tracking performance and user experience.
Despite these potential areas for improvement, the core idea of [object Object] is a promising direction that could significantly streamline the video annotation process and enable new applications.
Conclusion
This paper presents a novel approach for object tracking in videos that requires only a single point annotation per object, rather than the full object boundaries needed by traditional methods. The authors demonstrate that their model can learn robust tracking representations from these sparse annotations, achieving state-of-the-art results on several benchmarks.
The key innovation is the ability to predict the future location of an object given just a single point, which greatly reduces the annotation effort required. This has the potential to enable more efficient and scalable video annotation for a variety of applications, such as video analysis, autonomous systems, and medical imaging. While there are some areas for further refinement, this work represents an important step forward in the field of object tracking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Tracking Representations from Single Point Annotations
Qiangqiang Wu, Antoni B. Chan
Existing deep trackers are typically trained with largescale video frames with annotated bounding boxes. However, these bounding boxes are expensive and time-consuming to annotate, in particular for large scale datasets. In this paper, we propose to learn tracking representations from single point annotations (i.e., 4.5x faster to annotate than the traditional bounding box) in a weakly supervised manner. Specifically, we propose a soft contrastive learning (SoCL) framework that incorporates target objectness prior into end-to-end contrastive learning. Our SoCL consists of adaptive positive and negative sample generation, which is memory-efficient and effective for learning tracking representations. We apply the learned representation of SoCL to visual tracking and show that our method can 1) achieve better performance than the fully supervised baseline trained with box annotations under the same annotation time cost; 2) achieve comparable performance of the fully supervised baseline by using the same number of training frames and meanwhile reducing annotation time cost by 78% and total fees by 85%; 3) be robust to annotation noise.
Read more4/16/2024

0
On-the-Fly Point Annotation for Fast Medical Video Labeling
Meyer Adrien, Mazellier Jean-Paul, Jeremy Dana, Nicolas Padoy
Purpose: In medical research, deep learning models rely on high-quality annotated data, a process often laborious and timeconsuming. This is particularly true for detection tasks where bounding box annotations are required. The need to adjust two corners makes the process inherently frame-by-frame. Given the scarcity of experts' time, efficient annotation methods suitable for clinicians are needed. Methods: We propose an on-the-fly method for live video annotation to enhance the annotation efficiency. In this approach, a continuous single-point annotation is maintained by keeping the cursor on the object in a live video, mitigating the need for tedious pausing and repetitive navigation inherent in traditional annotation methods. This novel annotation paradigm inherits the point annotation's ability to generate pseudo-labels using a point-to-box teacher model. We empirically evaluate this approach by developing a dataset and comparing on-the-fly annotation time against traditional annotation method. Results: Using our method, annotation speed was 3.2x faster than the traditional annotation technique. We achieved a mean improvement of 6.51 +- 0.98 AP@50 over conventional method at equivalent annotation budgets on the developed dataset. Conclusion: Without bells and whistles, our approach offers a significant speed-up in annotation tasks. It can be easily implemented on any annotation platform to accelerate the integration of deep learning in video-based medical research.
Read more4/23/2024
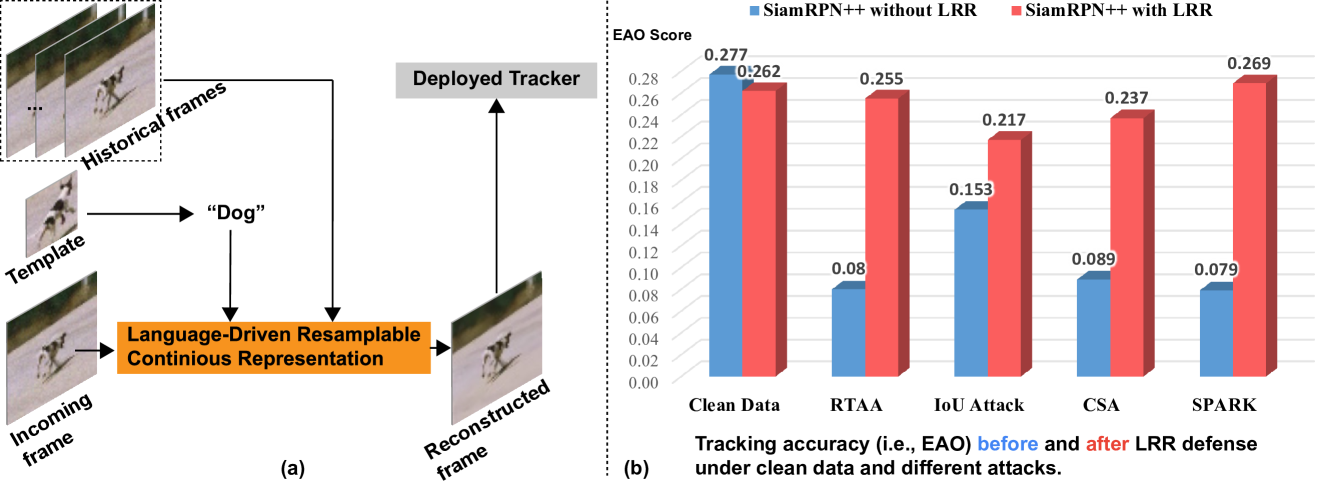
0
LRR: Language-Driven Resamplable Continuous Representation against Adversarial Tracking Attacks
Jianlang Chen, Xuhong Ren, Qing Guo, Felix Juefei-Xu, Di Lin, Wei Feng, Lei Ma, Jianjun Zhao
Visual object tracking plays a critical role in visual-based autonomous systems, as it aims to estimate the position and size of the object of interest within a live video. Despite significant progress made in this field, state-of-the-art (SOTA) trackers often fail when faced with adversarial perturbations in the incoming frames. This can lead to significant robustness and security issues when these trackers are deployed in the real world. To achieve high accuracy on both clean and adversarial data, we propose building a spatial-temporal continuous representation using the semantic text guidance of the object of interest. This novel continuous representation enables us to reconstruct incoming frames to maintain semantic and appearance consistency with the object of interest and its clean counterparts. As a result, our proposed method successfully defends against different SOTA adversarial tracking attacks while maintaining high accuracy on clean data. In particular, our method significantly increases tracking accuracy under adversarial attacks with around 90% relative improvement on UAV123, which is even higher than the accuracy on clean data.
Read more4/10/2024

0
Just a Hint: Point-Supervised Camouflaged Object Detection
Huafeng Chen, Dian Shao, Guangqian Guo, Shan Gao
Camouflaged Object Detection (COD) demands models to expeditiously and accurately distinguish objects which conceal themselves seamlessly in the environment. Owing to the subtle differences and ambiguous boundaries, COD is not only a remarkably challenging task for models but also for human annotators, requiring huge efforts to provide pixel-wise annotations. To alleviate the heavy annotation burden, we propose to fulfill this task with the help of only one point supervision. Specifically, by swiftly clicking on each object, we first adaptively expand the original point-based annotation to a reasonable hint area. Then, to avoid partial localization around discriminative parts, we propose an attention regulator to scatter model attention to the whole object through partially masking labeled regions. Moreover, to solve the unstable feature representation of camouflaged objects under only point-based annotation, we perform unsupervised contrastive learning based on differently augmented image pairs (e.g. changing color or doing translation). On three mainstream COD benchmarks, experimental results show that our model outperforms several weakly-supervised methods by a large margin across various metrics.
Read more8/21/2024