Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs

0

Sign in to get full access
Overview
- The paper investigates the fundamental reasoning abilities of large language models (LLMs), examining whether they are more adept at inductive or deductive reasoning.
- It proposes a new task to test the models' reasoning capabilities, going beyond standard language tasks.
- The research provides insights into the nature of LLM reasoning and has implications for the development and application of these models.
Plain English Explanation
The paper examines whether large language models (LLMs) are better at inductive reasoning or deductive reasoning. Inductive reasoning involves drawing general conclusions from specific observations, while deductive reasoning starts with general principles and applies them to specific situations.
The researchers designed a new task to test the reasoning abilities of LLMs, going beyond traditional language tasks like question answering or translation. This task requires the models to make logical inferences and draw conclusions, which provides deeper insights into their reasoning capabilities.
The findings from this research offer a better understanding of the fundamental reasoning abilities of LLMs. This knowledge can inform the development of these models and how they are applied in different domains, such as decision-making, problem-solving, and knowledge discovery.
Technical Explanation
The paper proposes a new task, called the "Inductive or Deductive?" (IoD) task, to evaluate the reasoning abilities of LLMs. In this task, the models are presented with a series of statements or premises and must determine whether the correct conclusion is reached through inductive or deductive reasoning.
The researchers designed a range of IoD tasks that cover different types of reasoning, including logical, causal, and analogical reasoning. They then evaluated the performance of several state-of-the-art LLMs, including GPT-3, on these tasks.
The results show that the LLMs generally perform better on deductive reasoning tasks than on inductive reasoning tasks. This suggests that these models may be more adept at applying general rules to specific situations than at deriving general principles from observations.
The paper also discusses the implications of these findings for the development and deployment of LLMs. The authors suggest that LLMs may need to be trained more explicitly on inductive reasoning tasks to improve their capabilities in this area. Additionally, the choice of reasoning approach may need to be considered when applying LLMs to real-world problems.
Critical Analysis
The paper presents a thoughtful and well-designed study to assess the reasoning abilities of LLMs. The researchers have carefully constructed a range of tasks to test different types of reasoning, which provides a more comprehensive evaluation than previous studies.
However, the paper does acknowledge some limitations of the research. The tasks are based on carefully curated datasets, and it's unclear how the models would perform on more open-ended, real-world reasoning problems. Additionally, the study focuses on a limited set of LLMs, and the findings may not generalize to other models or architectures.
It would be interesting to see further research that explores the factors that contribute to the LLMs' performance on inductive and deductive reasoning tasks. For example, the role of training data, model size, and architectural choices could be investigated to gain a deeper understanding of the underlying mechanisms driving the models' reasoning abilities.
Conclusion
This paper provides valuable insights into the fundamental reasoning abilities of large language models. The findings suggest that LLMs may be more adept at deductive reasoning than inductive reasoning, which has important implications for how these models are developed and applied.
The new task proposed in the paper offers a promising approach for evaluating the reasoning capabilities of LLMs, going beyond standard language tasks. By continuing to explore the reasoning abilities of these models, researchers can better understand their strengths, limitations, and potential applications in fields such as decision-making, problem-solving, and knowledge discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Kewei Cheng, Jingfeng Yang, Haoming Jiang, Zhengyang Wang, Binxuan Huang, Ruirui Li, Shiyang Li, Zheng Li, Yifan Gao, Xian Li, Bing Yin, Yizhou Sun
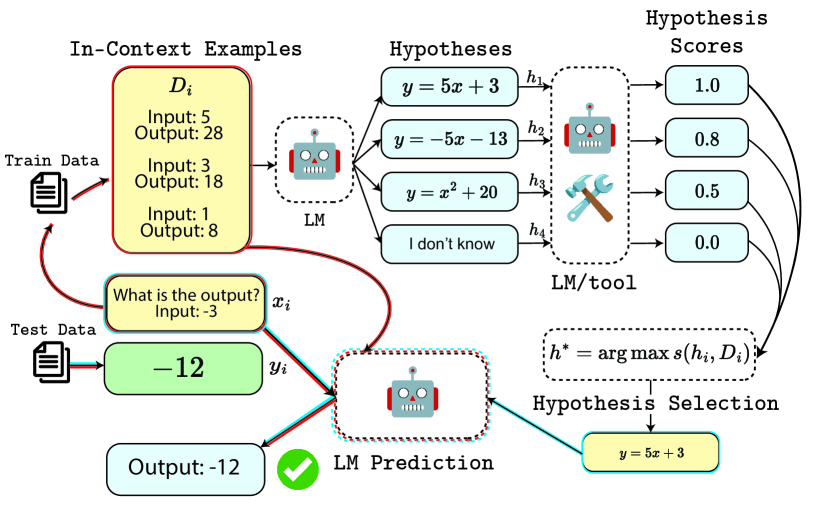
Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Read more8/9/2024
0
An Incomplete Loop: Deductive, Inductive, and Abductive Learning in Large Language Models
Emmy Liu, Graham Neubig, Jacob Andreas
Modern language models (LMs) can learn to perform new tasks in different ways: in instruction following, the target task is described explicitly in natural language; in few-shot prompting, the task is specified implicitly with a small number of examples; in instruction inference, LMs are presented with in-context examples and are then prompted to generate a natural language task description before making predictions. Each of these procedures may be thought of as invoking a different form of reasoning: instruction following involves deductive reasoning, few-shot prompting involves inductive reasoning, and instruction inference involves abductive reasoning. How do these different capabilities relate? Across four LMs (from the gpt and llama families) and two learning problems (involving arithmetic functions and machine translation) we find a strong dissociation between the different types of reasoning: LMs can sometimes learn effectively from few-shot prompts even when they are unable to explain their own prediction rules; conversely, they sometimes infer useful task descriptions while completely failing to learn from human-generated descriptions of the same task. Our results highlight the non-systematic nature of reasoning even in some of today's largest LMs, and underscore the fact that very different learning mechanisms may be invoked by seemingly similar prompting procedures.
Read more8/30/2024
💬
0
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
Read more4/16/2024
1
Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning
Philipp Mondorf, Barbara Plank
Deductive reasoning plays a pivotal role in the formulation of sound and cohesive arguments. It allows individuals to draw conclusions that logically follow, given the truth value of the information provided. Recent progress in the domain of large language models (LLMs) has showcased their capability in executing deductive reasoning tasks. Nonetheless, a significant portion of research primarily assesses the accuracy of LLMs in solving such tasks, often overlooking a deeper analysis of their reasoning behavior. In this study, we draw upon principles from cognitive psychology to examine inferential strategies employed by LLMs, through a detailed evaluation of their responses to propositional logic problems. Our findings indicate that LLMs display reasoning patterns akin to those observed in humans, including strategies like $textit{supposition following}$ or $textit{chain construction}$. Moreover, our research demonstrates that the architecture and scale of the model significantly affect its preferred method of reasoning, with more advanced models tending to adopt strategies more frequently than less sophisticated ones. Importantly, we assert that a model's accuracy, that is the correctness of its final conclusion, does not necessarily reflect the validity of its reasoning process. This distinction underscores the necessity for more nuanced evaluation procedures in the field.
Read more6/4/2024