Injecting Hamiltonian Architectural Bias into Deep Graph Networks for Long-Range Propagation

0
Sign in to get full access
Overview
- The paper introduces a novel deep graph network architecture called "(Port-)Hamiltonian Deep Graph Network" that incorporates Hamiltonian principles to enable long-range propagation of information.
- The proposed model is designed to address the "over-squashing" problem in traditional graph neural networks, where information from distant nodes gets compressed and loses its significance.
- The Hamiltonian architectural bias injects physical principles into the network structure, allowing it to better capture long-range dependencies and global structure in graph-structured data.
Plain English Explanation
The paper presents a new type of deep neural network for analyzing graph-structured data, such as social networks, transportation systems, or molecular structures. Traditional graph neural networks can struggle to capture long-range relationships between distant nodes in a graph, as the information gets "squashed" or compressed as it propagates through the network.
To address this issue, the researchers drew inspiration from Hamiltonian mechanics, a field of physics that describes the evolution of dynamic systems over time. They <a href="https://aimodels.fyi/papers/arxiv/graph-neural-networks-informed-locally-by-thermodynamics">incorporated these Hamiltonian principles</a> into the architecture of their deep graph network, creating a "Port-Hamiltonian Deep Graph Network."
This new model is designed to better preserve the long-range connections and global structure of the input graph as the information flows through the network. By emulating the physical principles that govern the dynamics of real-world systems, the network can more effectively capture the complex relationships between distant nodes.
This advancement could lead to improved performance on tasks like <a href="https://aimodels.fyi/papers/arxiv/differentiable-cluster-graph-neural-network">graph classification</a>, <a href="https://aimodels.fyi/papers/arxiv/tackling-graph-oversquashing-by-global-local-non">node prediction</a>, and <a href="https://aimodels.fyi/papers/arxiv/learning-coarse-grained-dynamics-graph">graph generation</a>, where understanding the global structure of the data is crucial.
Technical Explanation
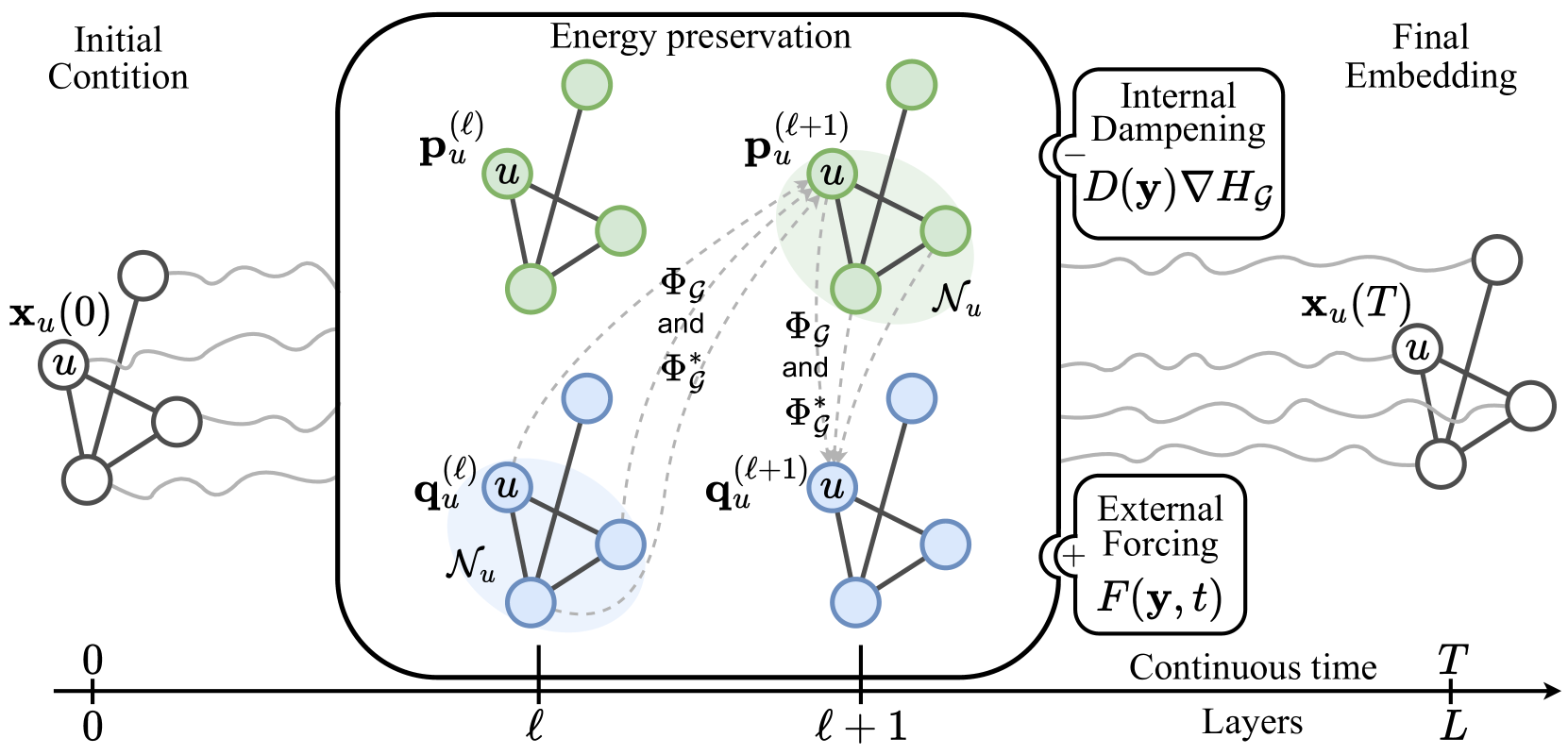
The authors propose a novel deep graph network architecture called "(Port-)Hamiltonian Deep Graph Network" that injects Hamiltonian principles into the network structure to enable more effective long-range propagation of information.
The key innovation is the use of a <a href="https://aimodels.fyi/papers/arxiv/lagrangian-neural-networks-reversible-dissipative-evolution">Hamiltonian-inspired layer</a>, which replaces the standard message-passing operations in traditional graph neural networks. This Hamiltonian layer models the dynamics of the graph as a Hamiltonian system, capturing the underlying physical principles that govern the evolution of the system over time.
The Hamiltonian architecture introduces a number of desirable properties, such as:
- Preservation of long-range dependencies: The Hamiltonian layer can better maintain the global structure of the graph as information propagates through the network, avoiding the "over-squashing" problem.
- Reversibility: The network's dynamics are reversible, allowing for more efficient and stable training.
- Interpretability: The Hamiltonian formulation provides a physical interpretation of the network's internal representations and computations.
The authors evaluate the (Port-)Hamiltonian Deep Graph Network on a range of graph learning tasks, including node classification, graph classification, and graph generation. The results demonstrate significant performance improvements compared to traditional graph neural network architectures, particularly on tasks that require capturing long-range dependencies in the data.
Critical Analysis
The (Port-)Hamiltonian Deep Graph Network represents a promising approach to addressing the limitations of existing graph neural networks, but the paper also acknowledges several caveats and areas for future research.
One potential limitation is the computational complexity of the Hamiltonian layer, which may be more resource-intensive than standard graph neural network layers. The authors suggest that further optimizations or approximations may be necessary to make the model more scalable to larger graphs.
Additionally, the paper does not provide a comprehensive analysis of the model's robustness to different types of graph structures or noise in the data. It would be valuable to investigate the model's performance on a wider range of graph topologies and real-world datasets to better understand its broader applicability.
Furthermore, while the Hamiltonian formulation provides an appealing physical interpretation of the network's internal representations, the paper does not explore how this interpretation could be leveraged to gain deeper insights into the learned representations or to guide the network's architecture and training further.
Overall, the (Port-)Hamiltonian Deep Graph Network represents an exciting step forward in the development of more powerful and principled graph neural network architectures. Continued research in this direction, addressing the identified limitations and exploring additional applications, could lead to significant advancements in our ability to understand and model complex graph-structured data.
Conclusion
The paper introduces the (Port-)Hamiltonian Deep Graph Network, a novel deep graph network architecture that incorporates Hamiltonian principles to enable more effective long-range propagation of information in graph-structured data. By emulating the underlying physical dynamics of the system, the proposed model can better capture global structure and maintain long-range dependencies, addressing the limitations of traditional graph neural networks.
The results demonstrate significant performance improvements on a range of graph learning tasks, suggesting that the Hamiltonian architectural bias is a promising approach for developing more powerful and interpretable graph neural network models. While the paper highlights some caveats and areas for future research, the (Port-)Hamiltonian Deep Graph Network represents an important contribution to the field of graph representation learning, with the potential to drive further advancements in our understanding and modeling of complex real-world systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Injecting Hamiltonian Architectural Bias into Deep Graph Networks for Long-Range Propagation
Simon Heilig, Alessio Gravina, Alessandro Trenta, Claudio Gallicchio, Davide Bacciu
The dynamics of information diffusion within graphs is a critical open issue that heavily influences graph representation learning, especially when considering long-range propagation. This calls for principled approaches that control and regulate the degree of propagation and dissipation of information throughout the neural flow. Motivated by this, we introduce (port-)Hamiltonian Deep Graph Networks, a novel framework that models neural information flow in graphs by building on the laws of conservation of Hamiltonian dynamical systems. We reconcile under a single theoretical and practical framework both non-dissipative long-range propagation and non-conservative behaviors, introducing tools from mechanical systems to gauge the equilibrium between the two components. Our approach can be applied to general message-passing architectures, and it provides theoretical guarantees on information conservation in time. Empirical results prove the effectiveness of our port-Hamiltonian scheme in pushing simple graph convolutional architectures to state-of-the-art performance in long-range benchmarks.
Read more5/28/2024

0
Long Range Propagation on Continuous-Time Dynamic Graphs
Alessio Gravina, Giulio Lovisotto, Claudio Gallicchio, Davide Bacciu, Claas Grohnfeldt
Learning Continuous-Time Dynamic Graphs (C-TDGs) requires accurately modeling spatio-temporal information on streams of irregularly sampled events. While many methods have been proposed recently, we find that most message passing-, recurrent- or self-attention-based methods perform poorly on long-range tasks. These tasks require correlating information that occurred far away from the current event, either spatially (higher-order node information) or along the time dimension (events occurred in the past). To address long-range dependencies, we introduce Continuous-Time Graph Anti-Symmetric Network (CTAN). Grounded within the ordinary differential equations framework, our method is designed for efficient propagation of information. In this paper, we show how CTAN's (i) long-range modeling capabilities are substantiated by theoretical findings and how (ii) its empirical performance on synthetic long-range benchmarks and real-world benchmarks is superior to other methods. Our results motivate CTAN's ability to propagate long-range information in C-TDGs as well as the inclusion of long-range tasks as part of temporal graph models evaluation.
Read more6/6/2024

0
Dirac--Bianconi Graph Neural Networks -- Enabling Non-Diffusive Long-Range Graph Predictions
Christian Nauck, Rohan Gorantla, Michael Lindner, Konstantin Schurholt, Antonia S. J. S. Mey, Frank Hellmann
The geometry of a graph is encoded in dynamical processes on the graph. Many graph neural network (GNN) architectures are inspired by such dynamical systems, typically based on the graph Laplacian. Here, we introduce Dirac--Bianconi GNNs (DBGNNs), which are based on the topological Dirac equation recently proposed by Bianconi. Based on the graph Laplacian, we demonstrate that DBGNNs explore the geometry of the graph in a fundamentally different way than conventional message passing neural networks (MPNNs). While regular MPNNs propagate features diffusively, analogous to the heat equation, DBGNNs allow for coherent long-range propagation. Experimental results showcase the superior performance of DBGNNs over existing conventional MPNNs for long-range predictions of power grid stability and peptide properties. This study highlights the effectiveness of DBGNNs in capturing intricate graph dynamics, providing notable advancements in GNN architectures.
Read more7/18/2024

0
Differentiable Cluster Graph Neural Network
Yanfei Dong, Mohammed Haroon Dupty, Lambert Deng, Zhuanghua Liu, Yong Liang Goh, Wee Sun Lee
Graph Neural Networks often struggle with long-range information propagation and in the presence of heterophilous neighborhoods. We address both challenges with a unified framework that incorporates a clustering inductive bias into the message passing mechanism, using additional cluster-nodes. Central to our approach is the formulation of an optimal transport based implicit clustering objective function. However, the algorithm for solving the implicit objective function needs to be differentiable to enable end-to-end learning of the GNN. To facilitate this, we adopt an entropy regularized objective function and propose an iterative optimization process, alternating between solving for the cluster assignments and updating the node/cluster-node embeddings. Notably, our derived closed-form optimization steps are themselves simple yet elegant message passing steps operating seamlessly on a bipartite graph of nodes and cluster-nodes. Our clustering-based approach can effectively capture both local and global information, demonstrated by extensive experiments on both heterophilous and homophilous datasets.
Read more5/28/2024