INSTA-YOLO: Real-Time Instance Segmentation

0
🎲
Sign in to get full access
Overview
- Instance segmentation is a computer vision task that aims to identify different objects in a scene, even if they belong to the same class.
- It is a two-stage process: first, objects are detected, then semantic segmentation is performed within the detected bounding boxes.
- This process can be computationally expensive, especially for the segmentation step.
- Some applications, like LiDAR point clouds and aerial object detection, also require predicting oriented bounding boxes, adding further complexity.
Plain English Explanation
Instance segmentation is a way for computers to look at a scene and identify different objects, even if they are the same type of thing. For example, if there are several cars in an image, instance segmentation would give each car its own unique ID.
This is useful in situations where objects might be partially blocked from view, or where you need to keep track of individual objects. However, the standard way of doing instance segmentation is a two-step process that can be slow and resource-intensive.
First, the computer has to detect where the objects are in the image. Then, it has to do a more detailed analysis to figure out the exact shape and boundaries of each object. This extra step of "segmentation" can be computationally expensive, especially for complex scenes or 3D data like LiDAR point clouds.
Technical Explanation
The researchers propose a new model called Insta-YOLO that combines object detection and instance segmentation into a single, end-to-end deep learning network. This is inspired by the YOLO (You Only Look Once) object detection model, but with some key modifications.
Instead of using the standard bounding box regression loss, Insta-YOLO uses a polynomial regression loss in the localization head. This allows the model to predict the instance segmentation contours directly from the polynomial coefficients, skipping the expensive upsampling step required in traditional two-stage pipelines.
Additionally, this polynomial representation makes Insta-YOLO well-suited for predicting oriented bounding boxes, which are important for applications like aerial object detection.
The researchers evaluate Insta-YOLO on three datasets: Carnva, Cityscapes, and Airbus. They show that Insta-YOLO achieves competitive accuracy in terms of mean average precision (mAP) while being around 2x faster than previous methods on a GTX-1080 GPU.
Critical Analysis
The paper presents a novel and interesting approach to instance segmentation that addresses some of the limitations of traditional two-stage pipelines. By combining detection and segmentation into a single end-to-end model, Insta-YOLO is able to achieve significant speed improvements without sacrificing too much accuracy.
However, the paper does not discuss any potential limitations or caveats of the Insta-YOLO approach. It would be helpful to know how the model performs on more complex or challenging datasets, or how it compares to other recently proposed one-stage instance segmentation methods, such as YOLACT or MEDYOLOv2.
Additionally, the paper does not provide much insight into the underlying reasons why the polynomial regression loss and oriented bounding box representation work well for this task. A more detailed analysis of the model's inner workings and design choices would help readers better understand the strengths and limitations of the approach.
Conclusion
The Insta-YOLO model presented in this paper represents an interesting advance in the field of instance segmentation. By combining detection and segmentation into a single end-to-end network, the researchers have developed a fast and accurate solution that is particularly well-suited for applications requiring oriented bounding boxes, such as LiDAR-based perception or aerial imagery analysis.
While the paper does not explore the model's limitations in depth, the promising results suggest that Insta-YOLO could be a valuable tool for real-world computer vision tasks that demand both efficiency and precision. Further research into the model's generalization capabilities and comparisons to other state-of-the-art methods would help solidify its position in the instance segmentation landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
INSTA-YOLO: Real-Time Instance Segmentation
Eslam Mohamed, Abdelrahman Shaker, Ahmad El-Sallab, Mayada Hadhoud
Instance segmentation has gained recently huge attention in various computer vision applications. It aims at providing different IDs to different object of the scene, even if they belong to the same class. This is useful in various scenarios, especially in occlusions. Instance segmentation is usually performed as a two-stage pipeline. First, an object is detected, then semantic segmentation within the detected box area. This process involves costly up-sampling, especially for the segmentation part. Moreover, for some applications, such as LiDAR point clouds and aerial object detection, it is often required to predict oriented boxes, which add extra complexity to the two-stage pipeline. In this paper, we propose Insta-YOLO, a novel one-stage end-to-end deep learning model for real-time instance segmentation. The proposed model is inspired by the YOLO one-shot object detector, with the box regression loss is replaced with polynomial regression in the localization head. This modification enables us to skip the segmentation up-sampling decoder altogether and produces the instance segmentation contour from the polynomial output coefficients. In addition, this architecture is a natural fit for oriented objects. We evaluate our model on three datasets, namely, Carnva, Cityscapes and Airbus. The results show our model achieves competitive accuracy in terms of mAP with significant improvement in speed by 2x on GTX-1080 GPU.
Read more9/4/2024
0
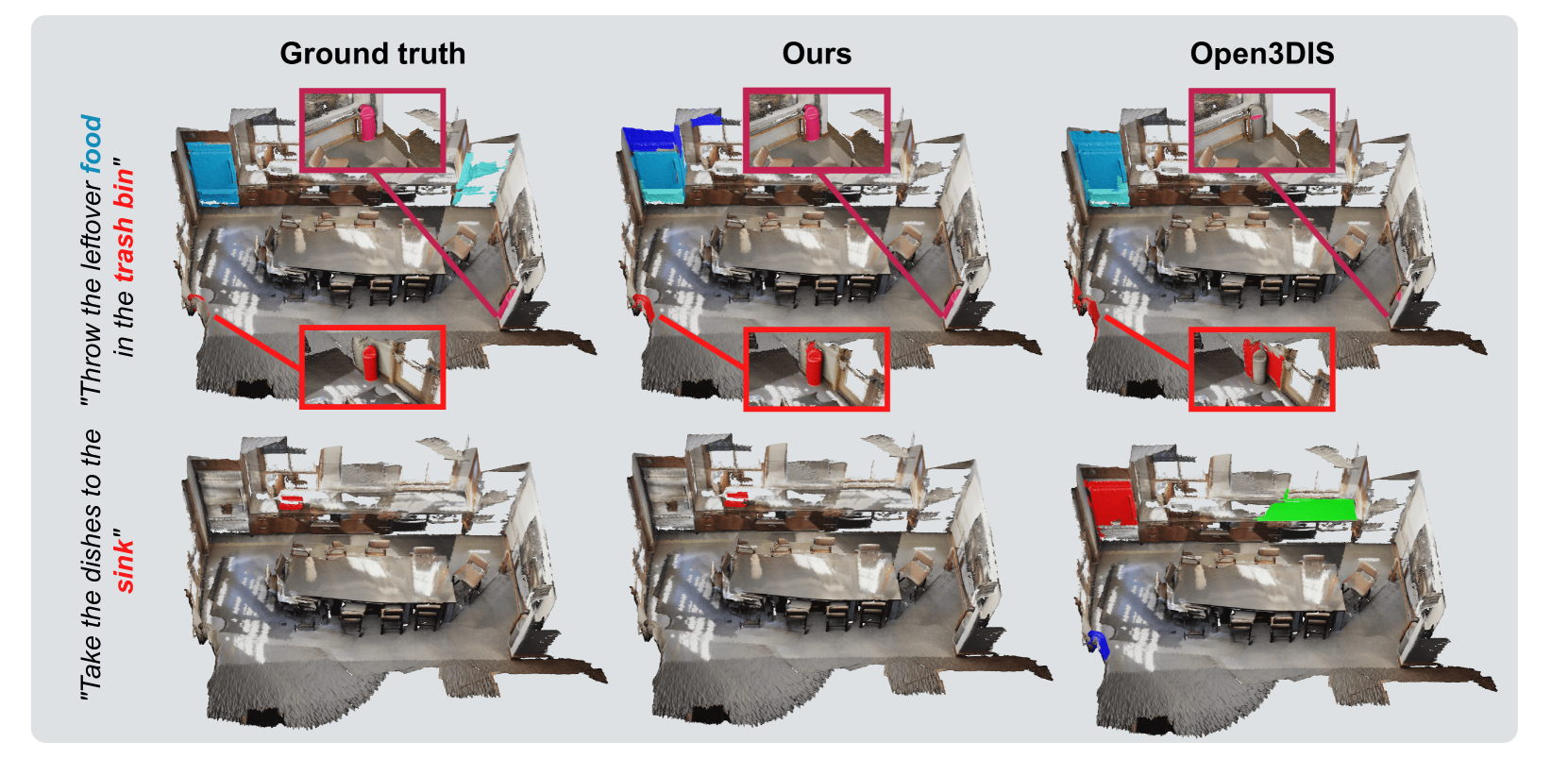
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $sim$16$times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.
Read more6/21/2024

0
You Only Look at Once for Real-time and Generic Multi-Task
Jiayuan Wang, Q. M. Jonathan Wu, Ning Zhang
High precision, lightweight, and real-time responsiveness are three essential requirements for implementing autonomous driving. In this study, we incorporate A-YOLOM, an adaptive, real-time, and lightweight multi-task model designed to concurrently address object detection, drivable area segmentation, and lane line segmentation tasks. Specifically, we develop an end-to-end multi-task model with a unified and streamlined segmentation structure. We introduce a learnable parameter that adaptively concatenates features between necks and backbone in segmentation tasks, using the same loss function for all segmentation tasks. This eliminates the need for customizations and enhances the model's generalization capabilities. We also introduce a segmentation head composed only of a series of convolutional layers, which reduces the number of parameters and inference time. We achieve competitive results on the BDD100k dataset, particularly in visualization outcomes. The performance results show a mAP50 of 81.1% for object detection, a mIoU of 91.0% for drivable area segmentation, and an IoU of 28.8% for lane line segmentation. Additionally, we introduce real-world scenarios to evaluate our model's performance in a real scene, which significantly outperforms competitors. This demonstrates that our model not only exhibits competitive performance but is also more flexible and faster than existing multi-task models. The source codes and pre-trained models are released at https://github.com/JiayuanWang-JW/YOLOv8-multi-task
Read more4/26/2024
🔎
1
YOLOv10: Real-Time End-to-End Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
Read more5/24/2024