Intent Detection and Entity Extraction from BioMedical Literature
2404.03598
0
0
Abstract
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores intent detection and entity extraction from biomedical literature, which are crucial tasks for understanding and organizing scientific information.
- The researchers leverage large language models and heterogeneous graph neural networks to tackle these challenges, drawing on advances in HGT: Leveraging Heterogeneous Graph Enhanced Large Language Models for Scientific Information Extraction and GEMINI: A Family of Highly Capable Multimodal Models.
- The study evaluates the performance of their approach on several biomedical datasets, demonstrating its effectiveness in extracting relevant concepts and understanding the intent behind scientific text.
Plain English Explanation
Imagine you're a researcher trying to stay on top of the latest developments in a fast-moving field like medicine or biology. With new studies and papers constantly being published, it can be challenging to quickly identify the key ideas and insights. This paper tackles that problem by developing AI models that can automatically detect the intent and extract the important entities (e.g., drug names, diseases, genes) from biomedical literature.
The core idea is to leverage large language models, which are trained on massive amounts of text data and can understand the meaning and context of words, and combine them with heterogeneous graph neural networks, which can model the complex relationships between different concepts. By bringing these two powerful techniques together, the researchers create a system that can "read" scientific papers with human-like comprehension, pinpointing the main goals and extracting the crucial information.
Imagine you're trying to understand the latest research on a new COVID-19 treatment. The AI system could quickly scan the relevant papers, detect that the intent is to evaluate the efficacy of a particular drug, and pull out the key details like the drug name, the patient population studied, and the reported outcomes. This could dramatically streamline the research process and help scientists stay up-to-date on the latest breakthroughs.
Technical Explanation
The paper proposes a novel approach for intent detection and entity extraction from biomedical literature, leveraging the strengths of large language models and heterogeneous graph neural networks.
For intent detection, the researchers fine-tune a pre-trained language model (such as BERT or RoBERTa) on datasets of scientific abstracts annotated with intent labels (e.g., "method", "result", "conclusion"). This allows the model to learn the linguistic patterns and contextual cues that signify different types of intent expressed in the text.
To extract entities, the authors construct a heterogeneous graph representation of the biomedical concepts, where nodes represent entities (e.g., drugs, diseases, genes) and edges capture the relationships between them. They then use a graph neural network, specifically the HGT model, to learn embeddings that capture the semantic and structural information of the entities. These embeddings are used to identify and classify the entities mentioned in the text.
The combined intent detection and entity extraction models are evaluated on several biomedical datasets, including NCBI Disease for disease recognition and BC5CDR for chemical-disease relations. The results demonstrate the effectiveness of the proposed approach, outperforming previous state-of-the-art methods.
Critical Analysis
The paper makes a valuable contribution to the field of biomedical natural language processing by presenting a unified framework for intent detection and entity extraction. The combination of language models and graph neural networks is a promising direction, as it allows the system to capture both the semantic and relational aspects of the domain-specific concepts.
However, the paper does not address some potential limitations of the approach. For example, the performance of the intent detection model may be sensitive to the quality and consistency of the training data, which can be challenging to obtain for specialized domains like biomedicine. Additionally, the graph construction process and the selection of relevant entity types and relationships could have a significant impact on the entity extraction performance, but the paper does not provide a detailed discussion of these design choices.
Furthermore, the paper focuses solely on the technical aspects of the model and does not delve into the broader implications or potential real-world applications of this technology. A more thorough discussion of how this work could benefit researchers, clinicians, or policymakers in the biomedical field would have strengthened the paper's overall impact.
Conclusion
This paper presents a compelling approach to intent detection and entity extraction from biomedical literature, leveraging the power of large language models and heterogeneous graph neural networks. By combining these cutting-edge techniques, the researchers have developed a system that can rapidly understand the goals and extract the key concepts from scientific text, a crucial capability for staying informed in fast-moving fields.
While the paper leaves room for further exploration of the approach's limitations and potential applications, it represents an important step forward in the quest to harness AI for the efficient and effective organization of scientific knowledge. As the volume of biomedical literature continues to grow, tools like this will become increasingly valuable for researchers, clinicians, and policymakers seeking to stay on the forefront of scientific progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024
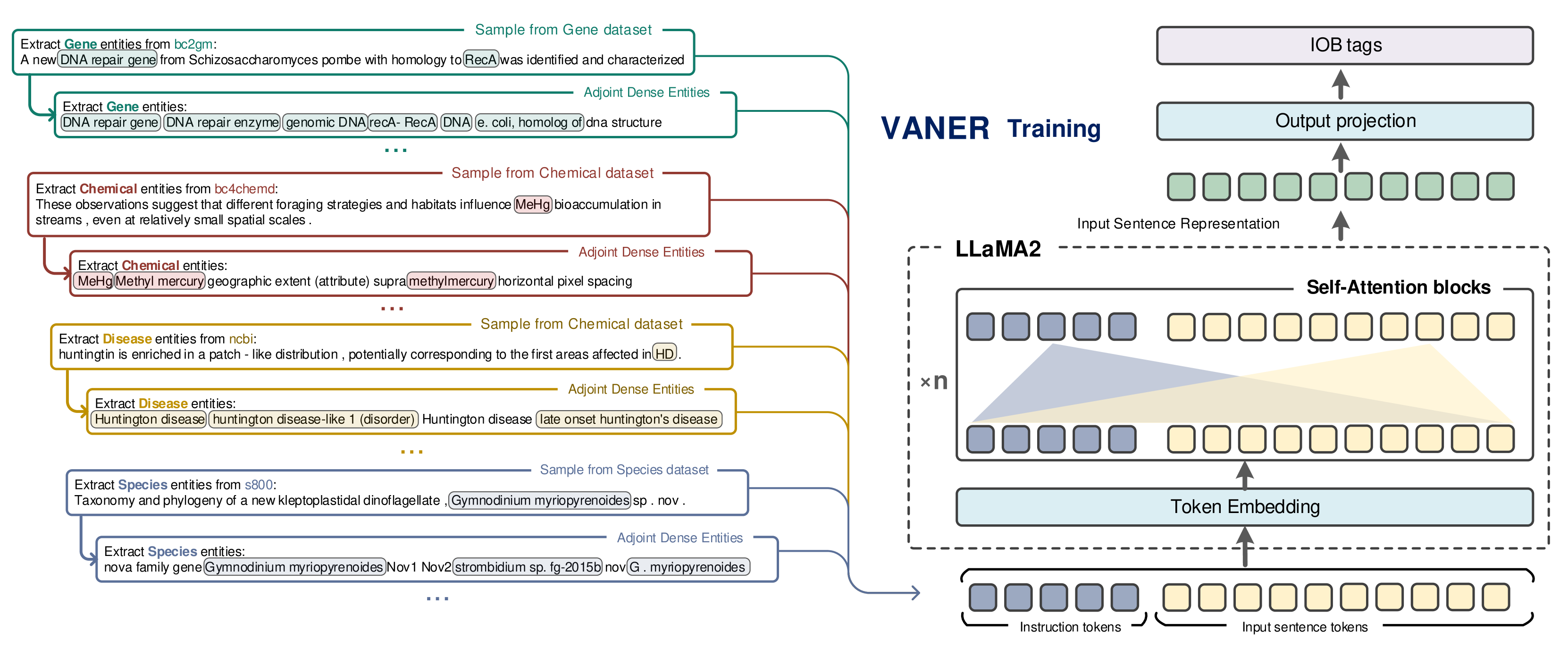
VANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Junyi Biana, Weiqi Zhai, Xiaodi Huang, Jiaxuan Zheng, Shanfeng Zhu
0
0
Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
4/30/2024
How far is Language Model from 100% Few-shot Named Entity Recognition in Medical Domain
Mingchen Li, Rui Zhang
0
0
Recent advancements in language models (LMs) have led to the emergence of powerful models such as Small LMs (e.g., T5) and Large LMs (e.g., GPT-4). These models have demonstrated exceptional capabilities across a wide range of tasks, such as name entity recognition (NER) in the general domain. (We define SLMs as pre-trained models with fewer parameters compared to models like GPT-3/3.5/4, such as T5, BERT, and others.) Nevertheless, their efficacy in the medical section remains uncertain and the performance of medical NER always needs high accuracy because of the particularity of the field. This paper aims to provide a thorough investigation to compare the performance of LMs in medical few-shot NER and answer How far is LMs from 100% Few-shot NER in Medical Domain, and moreover to explore an effective entity recognizer to help improve the NER performance. Based on our extensive experiments conducted on 16 NER models spanning from 2018 to 2023, our findings clearly indicate that LLMs outperform SLMs in few-shot medical NER tasks, given the presence of suitable examples and appropriate logical frameworks. Despite the overall superiority of LLMs in few-shot medical NER tasks, it is important to note that they still encounter some challenges, such as misidentification, wrong template prediction, etc. Building on previous findings, we introduce a simple and effective method called textsc{RT} (Retrieving and Thinking), which serves as retrievers, finding relevant examples, and as thinkers, employing a step-by-step reasoning process. Experimental results show that our proposed textsc{RT} framework significantly outperforms the strong open baselines on the two open medical benchmark datasets
5/7/2024
Automated Text Mining of Experimental Methodologies from Biomedical Literature
Ziqing Guo
0
0
Biomedical literature is a rapidly expanding field of science and technology. Classification of biomedical texts is an essential part of biomedicine research, especially in the field of biology. This work proposes the fine-tuned DistilBERT, a methodology-specific, pre-trained generative classification language model for mining biomedicine texts. The model has proven its effectiveness in linguistic understanding capabilities and has reduced the size of BERT models by 40% but by 60% faster. The main objective of this project is to improve the model and assess the performance of the model compared to the non-fine-tuned model. We used DistilBert as a support model and pre-trained on a corpus of 32,000 abstracts and complete text articles; our results were impressive and surpassed those of traditional literature classification methods by using RNN or LSTM. Our aim is to integrate this highly specialised and specific model into different research industries.
4/23/2024