Automated Text Mining of Experimental Methodologies from Biomedical Literature
2404.13779
0
0
Abstract
Biomedical literature is a rapidly expanding field of science and technology. Classification of biomedical texts is an essential part of biomedicine research, especially in the field of biology. This work proposes the fine-tuned DistilBERT, a methodology-specific, pre-trained generative classification language model for mining biomedicine texts. The model has proven its effectiveness in linguistic understanding capabilities and has reduced the size of BERT models by 40% but by 60% faster. The main objective of this project is to improve the model and assess the performance of the model compared to the non-fine-tuned model. We used DistilBert as a support model and pre-trained on a corpus of 32,000 abstracts and complete text articles; our results were impressive and surpassed those of traditional literature classification methods by using RNN or LSTM. Our aim is to integrate this highly specialised and specific model into different research industries.
Create account to get full access
Overview
- This paper presents an approach for automatically extracting experimental methodologies from biomedical literature using text mining techniques.
- The goal is to develop a system that can identify and extract details about the experimental procedures used in biomedical studies, which can be valuable for researchers, clinicians, and systematic reviewers.
- The authors employ natural language processing and machine learning methods to tackle this challenge, exploring different model architectures and training approaches.
Plain English Explanation
Researchers often publish their findings in scientific papers, describing the experiments they conducted. However, extracting the details of these experimental methods can be a time-consuming and tedious process, especially when sifting through a large body of literature.
The authors of this paper have developed a way to automate this task using artificial intelligence (AI) techniques. They have trained machine learning models to read through biomedical research papers and automatically identify and extract the key details about the experimental procedures used in the studies.
This could be very helpful for researchers, doctors, and others who need to quickly understand the experimental methodologies behind published findings. Instead of having to manually review each paper, they could use this automated system to efficiently gather the relevant information.
The authors explored different AI architectures and training approaches to build the most accurate and robust system possible. Their goal was to create a tool that can reliably extract the experimental details from a wide range of biomedical literature.
Technical Explanation
The authors approach this problem as a text mining task, using natural language processing (NLP) and machine learning techniques. They first assemble a corpus of biomedical research papers and manually annotate a subset of them to identify the key information about experimental methodologies.
They then experiment with different neural network models, including transformer-based architectures like BERT, to automatically extract the annotated information from the full corpus of papers. The models are trained to recognize patterns in the text that correspond to details about experimental procedures, sample preparation, data collection, and analysis methods.
The authors also explore techniques like entity extraction and relation detection to further enhance the granularity and accuracy of the extracted experimental metadata.
Critical Analysis
The paper provides a thorough and thoughtful approach to this important challenge in biomedical text mining. The authors recognize the limitations of manual curation and the need for automated systems to efficiently process the vast and growing body of biomedical literature.
One potential area for improvement could be the handling of ambiguous or context-dependent language used to describe experimental procedures. The authors acknowledge that their models may struggle with nuanced phrasing, and further research into more advanced language understanding techniques could help address this.
Additionally, the authors note that their system currently focuses on extracting the factual details of experimental methodologies, but does not attempt to interpret or evaluate the quality of the described procedures. Incorporating some level of critical analysis or quality assessment into the system could further enhance its usefulness for systematic reviews and meta-analyses.
Overall, this research represents a significant step forward in biomedical text mining, with the potential to greatly streamline the process of synthesizing experimental knowledge across the literature. The authors have laid a strong foundation for future work in this direction.
Conclusion
This paper presents a novel approach for automating the extraction of experimental methodologies from biomedical literature using advanced text mining techniques. The authors develop and evaluate various machine learning models to reliably identify and extract key details about the experimental procedures described in research papers.
The ability to efficiently gather this information has important implications for researchers, clinicians, and systematic reviewers who need to quickly understand the methodologies behind published findings. By automating this process, the authors aim to enhance the discoverability and synthesis of experimental knowledge in the biomedical domain.
While the current system has some limitations, this research represents a significant advancement in the field of biomedical text mining. The authors have demonstrated the feasibility of this approach and laid the groundwork for future improvements and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Intent Detection and Entity Extraction from BioMedical Literature
Ankan Mullick, Mukur Gupta, Pawan Goyal
0
0
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
4/5/2024
Literature Filtering for Systematic Reviews with Transformers
John Hawkins, David Tivey
0
0
Identifying critical research within the growing body of academic work is an essential element of quality research. Systematic review processes, used in evidence-based medicine, formalise this as a procedure that must be followed in a research program. However, it comes with an increasing burden in terms of the time required to identify the important articles of research for a given topic. In this work, we develop a method for building a general-purpose filtering system that matches a research question, posed as a natural language description of the required content, against a candidate set of articles obtained via the application of broad search terms. Our results demonstrate that transformer models, pre-trained on biomedical literature then fine tuned for the specific task, offer a promising solution to this problem. The model can remove large volumes of irrelevant articles for most research questions.
6/3/2024
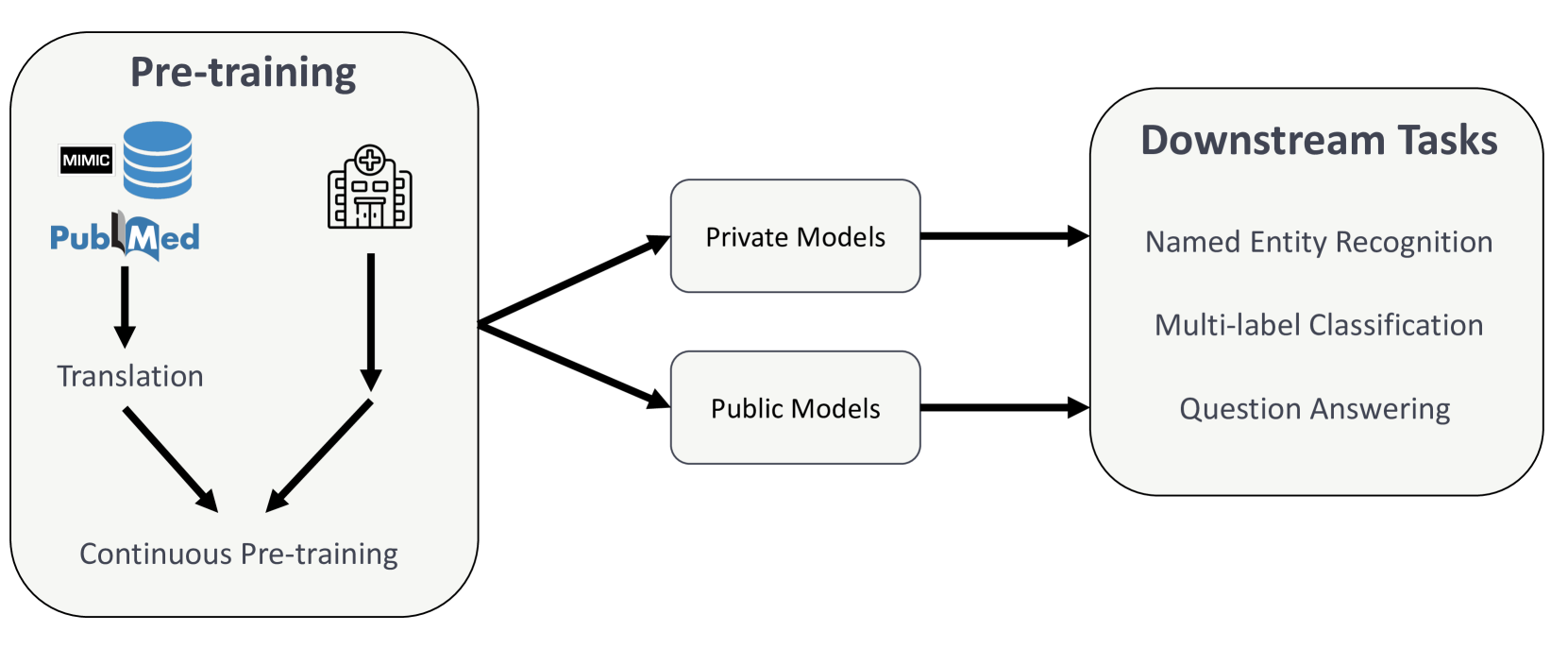
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
0
0
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
5/9/2024
Empowering Interdisciplinary Research with BERT-Based Models: An Approach Through SciBERT-CNN with Topic Modeling
Darya Likhareva, Hamsini Sankaran, Sivakumar Thiyagarajan
0
0
Researchers must stay current in their fields by regularly reviewing academic literature, a task complicated by the daily publication of thousands of papers. Traditional multi-label text classification methods often ignore semantic relationships and fail to address the inherent class imbalances. This paper introduces a novel approach using the SciBERT model and CNNs to systematically categorize academic abstracts from the Elsevier OA CC-BY corpus. We use a multi-segment input strategy that processes abstracts, body text, titles, and keywords obtained via BERT topic modeling through SciBERT. Here, the [CLS] token embeddings capture the contextual representation of each segment, concatenated and processed through a CNN. The CNN uses convolution and pooling to enhance feature extraction and reduce dimensionality, optimizing the data for classification. Additionally, we incorporate class weights based on label frequency to address the class imbalance, significantly improving the classification F1 score and enhancing text classification systems and literature review efficiency.
4/24/2024