An Interactive Agent Foundation Model
2402.05929
2
0
📈
Abstract
The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Create account to get full access
Overview
- Transition from static, task-specific AI models to dynamic, agent-based systems capable of diverse applications
- Proposal of an Interactive Agent Foundation Model using a novel multi-task agent training paradigm
- Unification of pre-training strategies like visual masked auto-encoders, language modeling, and next-action prediction
- Demonstration of performance across Robotics, Gaming AI, and Healthcare domains
Plain English Explanation
The development of artificial intelligence (AI) systems is moving away from creating rigid, single-purpose models towards more flexible, adaptable agent-based systems. Researchers have proposed an Interactive Agent Foundation Model that uses a new training approach to enable AI agents to perform well across a wide range of tasks and domains.
This training paradigm combines various pre-training techniques, including methods for analyzing visual data, modeling language, and predicting future actions. By unifying these diverse strategies, the researchers have created a versatile AI framework that can be applied to different areas like robotics, gaming, and healthcare.
The strength of this approach lies in its ability to leverage a variety of data sources, from robotic movement sequences to gameplay recordings and textual information, enabling effective multimodal and multi-task learning. This allows the AI agents to generate meaningful and relevant outputs in each of the tested domains, showcasing the potential for developing generalist, action-taking, and multimodal AI systems.
Technical Explanation
The researchers propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm. This paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction.
The researchers demonstrate the performance of their framework across three separate domains: Robotics, Gaming AI, and Healthcare. In the Robotics domain, the model is trained on sequences of robotic movements and can generate meaningful actions. In the Gaming AI domain, the model is trained on gameplay data and can produce contextually relevant outputs. In the Healthcare domain, the model is trained on textual information and can generate appropriate responses.
The key strength of the researchers' approach is its ability to leverage a variety of data sources, including robotics sequences, gameplay data, large-scale video datasets, and textual information, for effective multimodal and multi-task learning. This allows the Interactive Agent Foundation Model to demonstrate its versatility and adaptability across different domains.
Critical Analysis
The researchers acknowledge that their work is a promising step towards developing generalist, action-taking, and multimodal AI systems, but they do not address potential limitations or areas for further research. For example, the paper does not discuss the scalability of the training paradigm or the computational resources required to train such a model.
Additionally, the researchers do not provide a detailed analysis of the model's performance compared to other state-of-the-art approaches in the respective domains. A more thorough comparative evaluation would help to contextualize the significance of the Interactive Agent Foundation Model and its [contributions to the field of foundation models.
Conclusion
The presented research proposes an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm. This approach demonstrates the potential for developing versatile, adaptable AI agents capable of performing well across a wide range of applications, from robotics and gaming to healthcare. The key strength of the researchers' work lies in its ability to leverage diverse data sources for effective multimodal and multi-task learning, paving the way for more generalist, action-taking, and multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
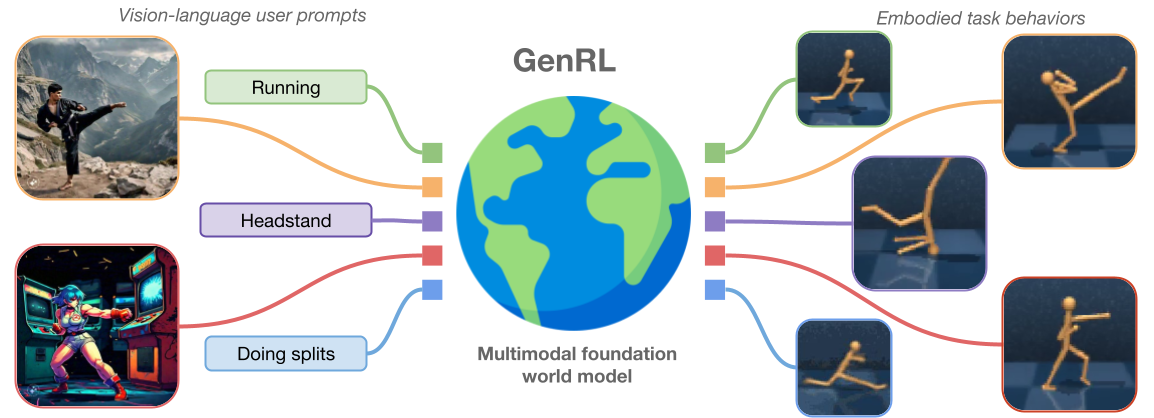
Multimodal foundation world models for generalist embodied agents
Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
0
0
Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language can specify tasks in a more natural way. Current foundation vision-language models (VLMs) generally require fine-tuning or other adaptations to be functional, due to the significant domain gap. However, the lack of multimodal data in such domains represents an obstacle toward developing foundation models for embodied applications. In this work, we overcome these problems by presenting multimodal foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL, without any language annotations. The resulting agent learning framework, GenRL, allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain's dynamics, and learns the corresponding behaviors in imagination. As assessed through large-scale multi-task benchmarking, GenRL exhibits strong multi-task generalization performance in several locomotion and manipulation domains. Furthermore, by introducing a data-free RL strategy, it lays the groundwork for foundation model-based RL for generalist embodied agents.
6/27/2024
📈
Towards Responsible Generative AI: A Reference Architecture for Designing Foundation Model based Agents
Qinghua Lu, Liming Zhu, Xiwei Xu, Zhenchang Xing, Stefan Harrer, Jon Whittle
0
0
Foundation models, such as large language models (LLMs), have been widely recognised as transformative AI technologies due to their capabilities to understand and generate content, including plans with reasoning capabilities. Foundation model based agents derive their autonomy from the capabilities of foundation models, which enable them to autonomously break down a given goal into a set of manageable tasks and orchestrate task execution to meet the goal. Despite the huge efforts put into building foundation model based agents, the architecture design of the agents has not yet been systematically explored. Also, while there are significant benefits of using agents for planning and execution, there are serious considerations regarding responsible AI related software quality attributes, such as security and accountability. Therefore, this paper presents a pattern-oriented reference architecture that serves as guidance when designing foundation model based agents. We evaluate the completeness and utility of the proposed reference architecture by mapping it to the architecture of two real-world agents.
4/4/2024

Position: Foundation Agents as the Paradigm Shift for Decision Making
Xiaoqian Liu, Xingzhou Lou, Jianbin Jiao, Junge Zhang
0
0
Decision making demands intricate interplay between perception, memory, and reasoning to discern optimal policies. Conventional approaches to decision making face challenges related to low sample efficiency and poor generalization. In contrast, foundation models in language and vision have showcased rapid adaptation to diverse new tasks. Therefore, we advocate for the construction of foundation agents as a transformative shift in the learning paradigm of agents. This proposal is underpinned by the formulation of foundation agents with their fundamental characteristics and challenges motivated by the success of large language models (LLMs). Moreover, we specify the roadmap of foundation agents from large interactive data collection or generation, to self-supervised pretraining and adaptation, and knowledge and value alignment with LLMs. Lastly, we pinpoint critical research questions derived from the formulation and delineate trends for foundation agents supported by real-world use cases, addressing both technical and theoretical aspects to propel the field towards a more comprehensive and impactful future.
5/30/2024
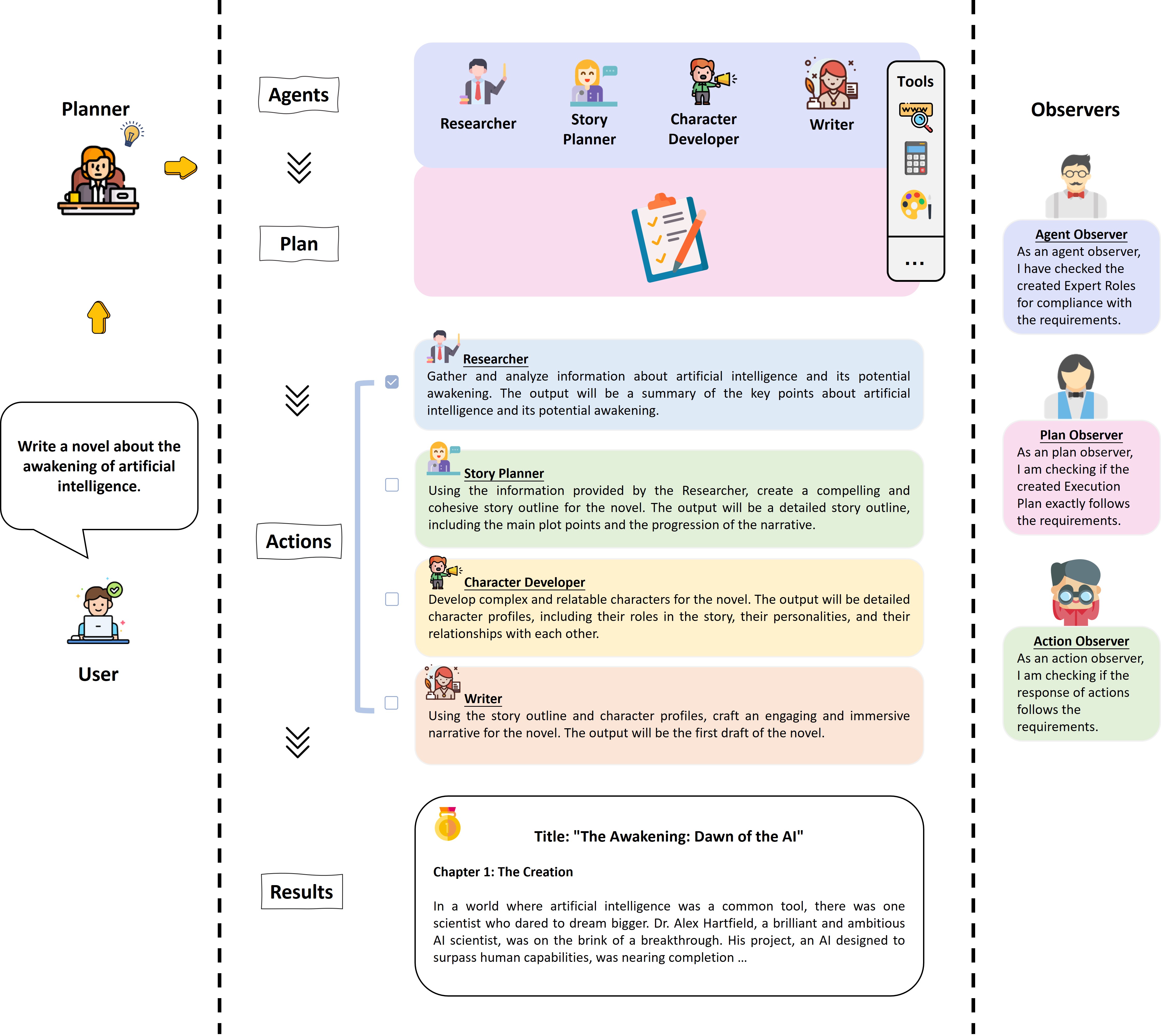
AutoAgents: A Framework for Automatic Agent Generation
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Borje F. Karlsson, Jie Fu, Yemin Shi
0
0
Large language models (LLMs) have enabled remarkable advances in automated task-solving with multi-agent systems. However, most existing LLM-based multi-agent approaches rely on predefined agents to handle simple tasks, limiting the adaptability of multi-agent collaboration to different scenarios. Therefore, we introduce AutoAgents, an innovative framework that adaptively generates and coordinates multiple specialized agents to build an AI team according to different tasks. Specifically, AutoAgents couples the relationship between tasks and roles by dynamically generating multiple required agents based on task content and planning solutions for the current task based on the generated expert agents. Multiple specialized agents collaborate with each other to efficiently accomplish tasks. Concurrently, an observer role is incorporated into the framework to reflect on the designated plans and agents' responses and improve upon them. Our experiments on various benchmarks demonstrate that AutoAgents generates more coherent and accurate solutions than the existing multi-agent methods. This underscores the significance of assigning different roles to different tasks and of team cooperation, offering new perspectives for tackling complex tasks. The repository of this project is available at https://github.com/Link-AGI/AutoAgents.
5/1/2024