Multimodal foundation world models for generalist embodied agents
2406.18043
0
0
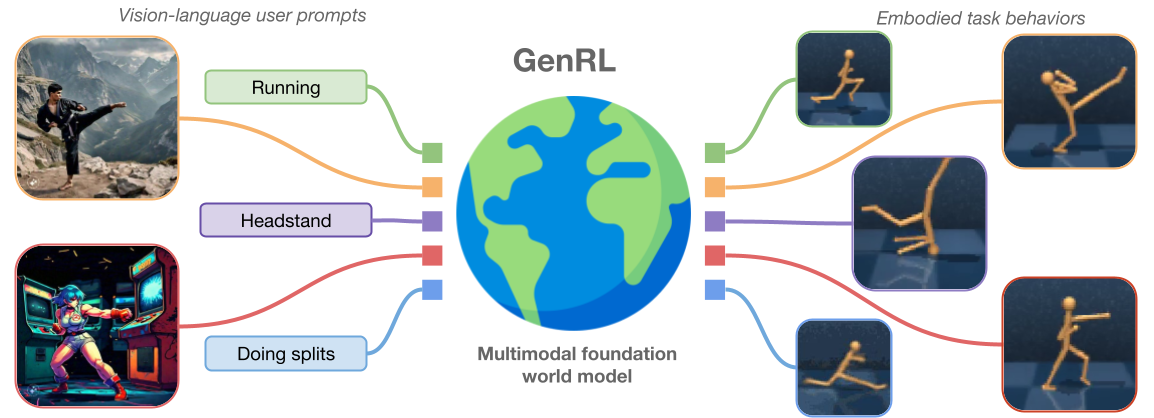
Abstract
Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language can specify tasks in a more natural way. Current foundation vision-language models (VLMs) generally require fine-tuning or other adaptations to be functional, due to the significant domain gap. However, the lack of multimodal data in such domains represents an obstacle toward developing foundation models for embodied applications. In this work, we overcome these problems by presenting multimodal foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL, without any language annotations. The resulting agent learning framework, GenRL, allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain's dynamics, and learns the corresponding behaviors in imagination. As assessed through large-scale multi-task benchmarking, GenRL exhibits strong multi-task generalization performance in several locomotion and manipulation domains. Furthermore, by introducing a data-free RL strategy, it lays the groundwork for foundation model-based RL for generalist embodied agents.
Create account to get full access
Overview
- This paper proposes a multimodal foundation world model for generalist embodied agents, which aims to enable versatile and capable agents that can perform a wide range of tasks in complex 3D environments.
- The model integrates vision, language, and action capabilities, drawing on recent advances in large language models, vision-language models, and interactive agent learning.
- The goal is to create an agent that can understand and interact with the world in human-like ways, using a combination of perceptual, reasoning, and motor skills.
Plain English Explanation
The researchers in this paper are trying to create a new kind of AI agent that can operate in 3D virtual environments and perform a wide variety of tasks, similar to how humans can. They're calling this a "multimodal foundation world model," which means it integrates different types of skills like vision, language, and action.
The key idea is to build on recent breakthroughs in large language models, vision-language models, and interactive agent learning. Large language models as generalizable policies for embodied agents and Interactive agent foundation models have shown promising results in this direction.
The goal is to create an agent that can perceive the world, reason about it using language, and take appropriate actions - just like a human would. This could enable the agent to be a generalist that can handle a diverse range of tasks and environments, rather than being specialized for a narrow set of activities.
Technical Explanation
The paper proposes an architecture that combines several key components:
- Vision-Language Model: This module takes in visual inputs (e.g. images, videos) and learns to associate them with language descriptions, leveraging techniques from Vision-language models that provide promptable representations for reinforcement learning.
- Action Model: This component learns to map language instructions and visual inputs to appropriate actions that can be executed in the 3D environment, building on work in Survey of vision-language-action models for embodied AI.
- World Model: This module maintains an internal representation of the 3D environment, allowing the agent to reason about and plan in the world, similar to the approach in Large language models as generalizable policies for embodied agents.
The authors propose training this multimodal foundation model on large-scale datasets covering a diverse range of visual, linguistic, and interactive experiences. The goal is to create an agent that can flexibly apply its skills to new tasks and environments, rather than being specialized for a narrow set of activities.
Critical Analysis
The authors acknowledge several limitations and challenges in their approach:
- Data Efficiency: Training such a broad and capable model requires vast amounts of diverse data, which may be difficult to acquire and curate.
- Task Generalization: Ensuring that the model can truly generalize to novel tasks and environments, beyond just recombining its learned skills, is an open challenge.
- Safety and Alignment: As the model becomes more capable and versatile, ensuring that it behaves in alignment with human values and intentions will be crucial.
Additionally, the proposed architecture is highly complex, and the authors do not provide a detailed implementation or empirical evaluation. Further research is needed to demonstrate the feasibility and effectiveness of this multimodal foundation world model in practice.
Conclusion
This paper presents an ambitious vision for creating a generalist embodied agent that can perceive, reason about, and interact with the world in human-like ways. By integrating advances in large language models, vision-language models, and interactive agent learning, the authors aim to develop a versatile foundation model that can be applied to a wide range of tasks and environments.
While the technical challenges are significant, the potential benefits of such a capable and flexible agent are substantial. If successful, this line of research could lead to breakthroughs in areas like robotic assistants, intelligent tutoring systems, and general-purpose problem-solving agents that can operate in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
An Embodied Generalist Agent in 3D World
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, Siyuan Huang
0
0
Leveraging massive knowledge from large language models (LLMs), recent machine learning models show notable successes in general-purpose task solving in diverse domains such as computer vision and robotics. However, several significant challenges remain: (i) most of these models rely on 2D images yet exhibit a limited capacity for 3D input; (ii) these models rarely explore the tasks inherently defined in 3D world, e.g., 3D grounding, embodied reasoning and acting. We argue these limitations significantly hinder current models from performing real-world tasks and approaching general intelligence. To this end, we introduce LEO, an embodied multi-modal generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. LEO is trained with a unified task interface, model architecture, and objective in two stages: (i) 3D vision-language (VL) alignment and (ii) 3D vision-language-action (VLA) instruction tuning. We collect large-scale datasets comprising diverse object-level and scene-level tasks, which require considerable understanding of and interaction with the 3D world. Moreover, we meticulously design an LLM-assisted pipeline to produce high-quality 3D VL data. Through extensive experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, navigation and manipulation. Our ablative studies and scaling analyses further provide valuable insights for developing future embodied generalist agents. Code and data are available on project page.
5/10/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024
📈
An Interactive Agent Foundation Model
Zane Durante, Bidipta Sarkar, Ran Gong, Rohan Taori, Yusuke Noda, Paul Tang, Ehsan Adeli, Shrinidhi Kowshika Lakshmikanth, Kevin Schulman, Arnold Milstein, Demetri Terzopoulos, Ade Famoti, Noboru Kuno, Ashley Llorens, Hoi Vo, Katsu Ikeuchi, Li Fei-Fei, Jianfeng Gao, Naoki Wake, Qiuyuan Huang
0
0
The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
6/18/2024