Interactive Evolution: A Neural-Symbolic Self-Training Framework For Large Language Models
2406.11736
0
0

Abstract
One of the primary driving forces contributing to the superior performance of Large Language Models (LLMs) is the extensive availability of human-annotated natural language data, which is used for alignment fine-tuning. This inspired researchers to investigate self-training methods to mitigate the extensive reliance on human annotations. However, the current success of self-training has been primarily observed in natural language scenarios, rather than in the increasingly important neural-symbolic scenarios. To this end, we propose an environment-guided neural-symbolic self-training framework named ENVISIONS. It aims to overcome two main challenges: (1) the scarcity of symbolic data, and (2) the limited proficiency of LLMs in processing symbolic language. Extensive evaluations conducted on three distinct domains demonstrate the effectiveness of our approach. Additionally, we have conducted a comprehensive analysis to uncover the factors contributing to ENVISIONS's success, thereby offering valuable insights for future research in this area. Code will be available at url{https://github.com/xufangzhi/ENVISIONS}.
Create account to get full access
Overview
• This paper introduces a novel framework called "Interactive Evolution" that enables large language models (LLMs) to self-train and improve their own capabilities through an iterative process.
• The framework involves the LLM generating candidate outputs, evaluating them using a neural-symbolic reasoning system, and then updating the model based on the feedback to generate better outputs in the next iteration.
• By allowing the LLM to evolve and refine itself, the authors aim to address some of the challenges associated with the current approach of manually fine-tuning LLMs for specific tasks.
Plain English Explanation
The paper presents a new way for large language models (LLMs) to learn and improve on their own, without relying solely on human-curated data and manual fine-tuning. The key idea is to give the LLM the ability to generate candidate outputs, evaluate them using a specialized reasoning system, and then use that feedback to update and refine the model.
This "interactive evolution" approach allows the LLM to iteratively improve its own capabilities, rather than having to wait for researchers to manually fine-tune it for each new task or application. The authors argue that this can help address some of the limitations of the current approach, where LLMs are often trained on a fixed dataset and then struggle to adapt to new, unfamiliar scenarios.
By enabling the LLM to become more self-aware and self-improving, the researchers hope to create a more flexible and capable system that can continue to evolve and expand its knowledge over time, without being as dependent on human intervention.
Technical Explanation
The authors propose an "Interactive Evolution" framework that allows large language models (LLMs) to self-train and improve their own capabilities through an iterative process. The key components of this framework include:
-
Candidate Generation: The LLM generates a set of candidate outputs for a given task or prompt.
-
Neural-Symbolic Reasoning: A specialized reasoning system, built using neural networks and symbolic logic, evaluates the quality and correctness of the candidate outputs.
-
Model Update: Based on the feedback from the reasoning system, the LLM is updated and refined to generate better outputs in the next iteration.
This interactive, self-training approach is in contrast to the traditional fine-tuning approach, where LLMs are manually adjusted by researchers for specific tasks. The authors argue that their framework can help address some of the limitations of the current approach, such as the difficulty in adapting LLMs to new, unfamiliar scenarios.
The authors demonstrate the effectiveness of their framework through various experiments, including language understanding, commonsense reasoning, and multi-task learning tasks. The results suggest that the Interactive Evolution framework can lead to significant improvements in the LLM's performance compared to standard fine-tuning techniques.
Critical Analysis
The Interactive Evolution framework proposed in this paper is a promising step towards creating more autonomous and self-improving large language models. By allowing the LLM to evaluate and refine its own outputs, the authors aim to reduce the reliance on manual fine-tuning and enable the model to adapt more flexibly to new tasks and domains.
However, the paper does not fully address some potential limitations and challenges of this approach. For example, the authors do not discuss the computational and resource requirements of the iterative training process, which could be a significant practical concern for deploying such a framework at scale.
Additionally, the paper does not explore the long-term implications of allowing LLMs to self-train and evolve without direct human oversight. There could be risks related to model drift, unexpected behaviors, or the emergence of undesirable biases or capabilities that the authors do not address in depth.
Further research is needed to understand the broader implications and potential pitfalls of self-training LLMs, as well as to refine the technical details of the Interactive Evolution framework to make it more robust and scalable. Nonetheless, this work represents an important step towards more autonomous and adaptable language models, and it will be interesting to see how the field evolves in response to these ideas.
Conclusion
The "Interactive Evolution" framework presented in this paper offers a novel approach to enabling large language models (LLMs) to self-train and improve their own capabilities over time. By allowing the LLM to generate candidate outputs, evaluate them using a neural-symbolic reasoning system, and then update the model based on the feedback, the authors aim to create a more flexible and autonomous system that can adapt to new tasks and scenarios without heavy reliance on manual fine-tuning.
While the paper demonstrates promising results, it also raises important questions and concerns that will need to be addressed through further research and development. Nonetheless, this work represents a significant step towards more self-aware and self-improving language models, which could have far-reaching implications for the future of AI and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
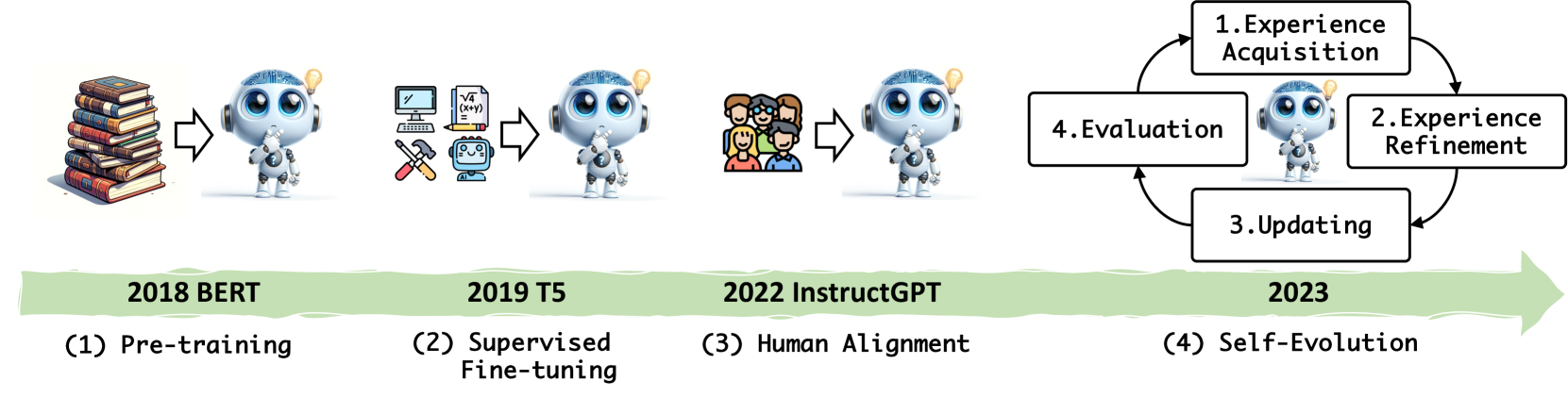
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024
Language Model Evolution: An Iterated Learning Perspective
Yi Ren, Shangmin Guo, Linlu Qiu, Bailin Wang, Danica J. Sutherland
0
0
With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
4/9/2024

Symbolic Learning Enables Self-Evolving Agents
Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, Huajun Chen, Yuchen Eleanor Jiang
0
0
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing language agents, which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in self-evolving agents.
6/27/2024

AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang Liao, Xin Guo, Wei He, Songyang Gao, Lu Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang
0
0
Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.
6/7/2024