Interactive3D: Create What You Want by Interactive 3D Generation
2404.16510
0
1

Abstract
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at url{https://interactive-3d.github.io/}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper introduces a new method for interactive 3D generation, where users can create 3D content and scenes by providing natural language prompts.
• The proposed approach uses a large language model to generate scene descriptions, which are then converted into 3D geometry using a neural network trained on 3D data.
• The system allows users to iteratively refine and modify the generated 3D content through natural language interactions, enabling a more intuitive and flexible 3D creation workflow.
Plain English Explanation
The researchers have developed a new way to create 3D content and scenes using natural language. Instead of having to use complex 3D modeling software, users can simply describe what they want to create in plain words, and the system will generate the corresponding 3D geometry.
For example, a user could say "Create a sunny meadow with flowers and a small pond," and the system would generate a 3D scene matching that description. The user can then refine or modify the scene by providing additional language prompts, such as "Make the pond larger and add some ducks."
This approach aims to make 3D content creation more accessible and intuitive for a wider range of users, as it leverages the power of large language models to bridge the gap between human ideas and 3D digital representations. By allowing users to iteratively refine the 3D content through natural language, the system provides a more fluid and interactive 3D creation experience.
Technical Explanation
The core of the system is a neural network that can convert natural language scene descriptions into 3D geometry. This network is trained on a large dataset of 3D models and their corresponding textual descriptions.
When a user provides a language prompt, the system first uses a large language model to generate a detailed scene description. This description is then fed into the 3D generation network, which outputs a 3D point cloud representing the desired scene.
To enable interactive refinement, the system also includes a mechanism for users to provide additional language prompts that modify the existing 3D content. These prompts are processed and used to update the 3D geometry in real-time, allowing users to iteratively shape the 3D scene to their liking.
The researchers evaluated their system through user studies and found that it significantly improved the speed and ease of 3D content creation compared to traditional 3D modeling tools, particularly for users with little 3D expertise.
Critical Analysis
While the proposed system shows promise in making 3D content creation more accessible, there are some potential limitations and areas for further research:
-
The quality and fidelity of the generated 3D content is still limited compared to what skilled 3D artists can create manually. Further improvements to the 3D generation network may be needed to achieve higher realism and detail.
-
The system's ability to interpret and respond to complex language prompts is currently restricted. Enhancing the language understanding capabilities could lead to more nuanced and expressive 3D generation.
-
Integrating the system with existing 3D modeling workflows and tools could further improve its adoption and usefulness for professional creators. Providing seamless import/export options and compatibility with standard 3D file formats would be valuable.
-
Exploring the use of this technology in educational, creative, and therapeutic contexts could uncover additional applications and user needs to address in future iterations.
Conclusion
This paper presents a novel approach for interactive 3D content creation using natural language prompts. By leveraging the power of large language models and neural networks trained on 3D data, the system allows users to generate and refine 3D scenes in a more intuitive and accessible way than traditional 3D modeling tools.
While the current implementation has some limitations, the underlying concept of bridging the gap between human ideas and 3D digital representations holds significant promise for democratizing 3D content creation and making it more accessible to a wider audience. Further research and development in this area could lead to transformative tools that empower people to bring their imaginative ideas to life in the virtual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
Wenqi Dong, Bangbang Yang, Lin Ma, Xiao Liu, Liyuan Cui, Hujun Bao, Yuewen Ma, Zhaopeng Cui
0
0
As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.
5/15/2024
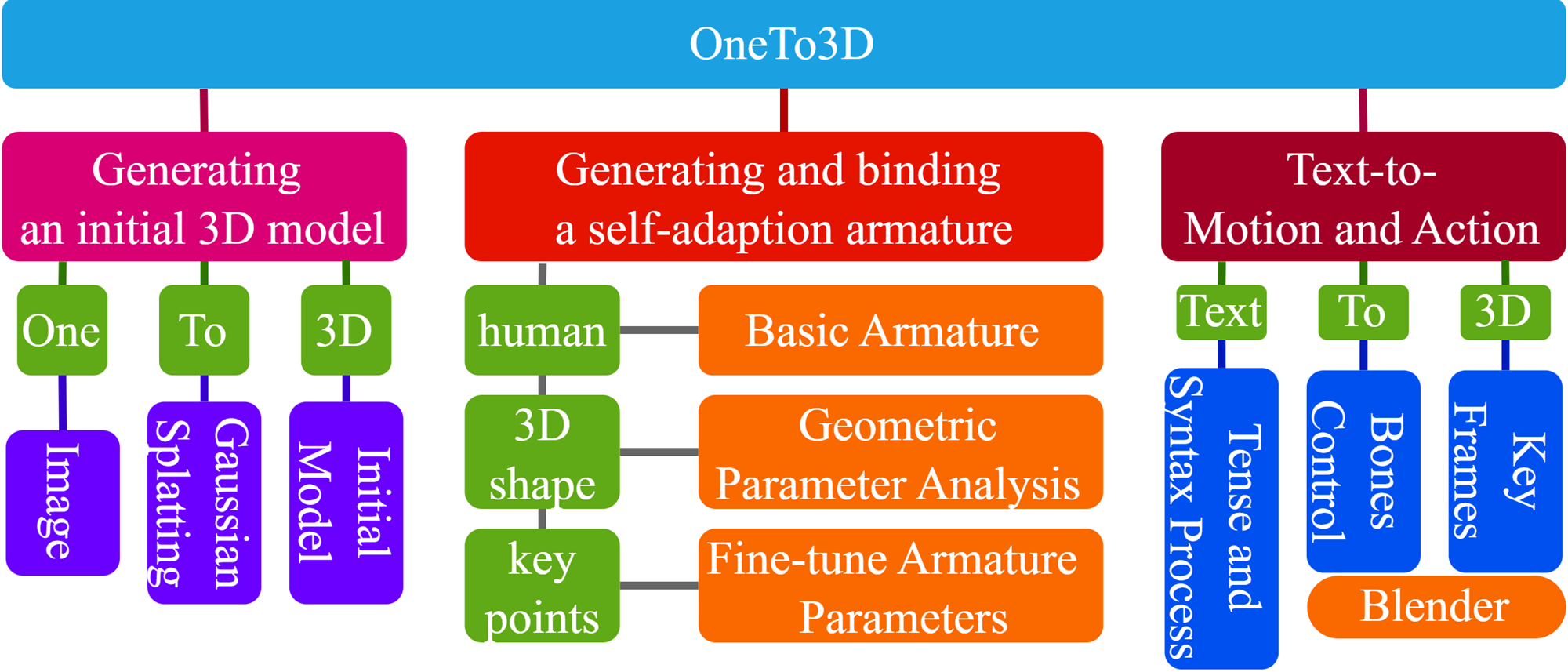
OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
Jinwei Lin
0
0
One image to editable dynamic 3D model and video generation is novel direction and change in the research area of single image to 3D representation or 3D reconstruction of image. Gaussian Splatting has demonstrated its advantages in implicit 3D reconstruction, compared with the original Neural Radiance Fields. As the rapid development of technologies and principles, people tried to used the Stable Diffusion models to generate targeted models with text instructions. However, using the normal implicit machine learning methods is hard to gain the precise motions and actions control, further more, it is difficult to generate a long content and semantic continuous 3D video. To address this issue, we propose the OneTo3D, a method and theory to used one single image to generate the editable 3D model and generate the targeted semantic continuous time-unlimited 3D video. We used a normal basic Gaussian Splatting model to generate the 3D model from a single image, which requires less volume of video memory and computer calculation ability. Subsequently, we designed an automatic generation and self-adaptive binding mechanism for the object armature. Combined with the re-editable motions and actions analyzing and controlling algorithm we proposed, we can achieve a better performance than the SOTA projects in the area of building the 3D model precise motions and actions control, and generating a stable semantic continuous time-unlimited 3D video with the input text instructions. Here we will analyze the detailed implementation methods and theories analyses. Relative comparisons and conclusions will be presented. The project code is open source.
5/13/2024
🌐
Text-to-3D using Gaussian Splatting
Zilong Chen, Feng Wang, Yikai Wang, Huaping Liu
0
0
Automatic text-to-3D generation that combines Score Distillation Sampling (SDS) with the optimization of volume rendering has achieved remarkable progress in synthesizing realistic 3D objects. Yet most existing text-to-3D methods by SDS and volume rendering suffer from inaccurate geometry, e.g., the Janus issue, since it is hard to explicitly integrate 3D priors into implicit 3D representations. Besides, it is usually time-consuming for them to generate elaborate 3D models with rich colors. In response, this paper proposes GSGEN, a novel method that adopts Gaussian Splatting, a recent state-of-the-art representation, to text-to-3D generation. GSGEN aims at generating high-quality 3D objects and addressing existing shortcomings by exploiting the explicit nature of Gaussian Splatting that enables the incorporation of 3D prior. Specifically, our method adopts a progressive optimization strategy, which includes a geometry optimization stage and an appearance refinement stage. In geometry optimization, a coarse representation is established under 3D point cloud diffusion prior along with the ordinary 2D SDS optimization, ensuring a sensible and 3D-consistent rough shape. Subsequently, the obtained Gaussians undergo an iterative appearance refinement to enrich texture details. In this stage, we increase the number of Gaussians by compactness-based densification to enhance continuity and improve fidelity. With these designs, our approach can generate 3D assets with delicate details and accurate geometry. Extensive evaluations demonstrate the effectiveness of our method, especially for capturing high-frequency components. Our code is available at https://github.com/gsgen3d/gsgen
4/3/2024

DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
0
0
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary flat (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
4/11/2024