Interpretable Data Fusion for Distributed Learning: A Representative Approach via Gradient Matching

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Interpretable Data Fusion for Distributed Learning" that aims to make distributed learning systems more transparent and understandable.
- The key idea is to use "gradient matching" to fuse the gradients from multiple distributed models, allowing a central model to learn from the distributed models in an interpretable way.
- The authors demonstrate the benefits of this approach through experiments, showing it can improve model performance and interpretability compared to standard distributed learning techniques.
Plain English Explanation
In traditional machine learning, a single model is trained on a large dataset. However, in many real-world scenarios, data may be spread across multiple locations or devices, making it difficult to train a single model effectively. This is where
The challenge with distributed learning is that the process of combining the models can be complex and opaque, making it hard for humans to understand how the final model was developed. This paper introduces a new approach called "Interpretable Data Fusion" that aims to make the distributed learning process more transparent and understandable.
The key innovation is the use of "gradient matching". Gradients are a mathematical concept that describe how a model's predictions change as its internal parameters are adjusted. The idea behind gradient matching is to fuse the gradients from the distributed models in a way that preserves the interpretability of the learning process.
By matching the gradients of the distributed models, the central model can learn from the distributed models in a way that is more easily understood by humans. This can be particularly useful in applications where it's important to explain how a model arrived at its predictions, such as in healthcare or finance.
The authors demonstrate the benefits of this approach through experiments, showing that it can improve model performance and interpretability compared to standard distributed learning techniques. This suggests that interpretable data fusion could be a valuable tool for developing more transparent and trustworthy AI systems.
Technical Explanation
The paper proposes a novel approach called "Interpretable Data Fusion for Distributed Learning" that aims to make distributed learning systems more transparent and understandable. The key innovation is the use of "gradient matching" to fuse the gradients from multiple distributed models.
In traditional distributed learning, a central model is trained by aggregating the model updates (e.g., parameter updates) from the distributed models. However, this process can be complex and opaque, making it difficult for humans to understand how the final model was developed.
To address this, the authors introduce a gradient matching-based data fusion approach. The central idea is to fuse the gradients from the distributed models, rather than just the parameter updates. By matching the gradients, the central model can learn from the distributed models in a way that preserves the interpretability of the learning process.
Specifically, the authors formulate an optimization problem that minimizes the distance between the gradients of the central model and the gradients of the distributed models. This allows the central model to learn in a way that is aligned with the distributed models, while also maintaining interpretability.
The authors evaluate their approach on several benchmark datasets and tasks, including image classification and natural language processing. They show that the proposed Interpretable Data Fusion approach can improve model performance and interpretability compared to standard distributed learning techniques.
For example, the authors demonstrate that their approach can achieve higher classification accuracy on the CIFAR-10 dataset while also providing more interpretable explanations for the model's predictions. This suggests that interpretable data fusion could be a valuable tool for developing more transparent and trustworthy AI systems.
Critical Analysis
The paper presents a novel and promising approach for improving the interpretability of distributed learning systems. The use of gradient matching to fuse the distributed models is a clever idea that has the potential to make the learning process more transparent and understandable.
One potential limitation of the approach is that it may not be applicable to all types of distributed learning scenarios. The authors focus on settings where the distributed models are similar in structure and can be easily aligned through gradient matching. In more heterogeneous settings, where the distributed models have very different architectures or learning objectives, the gradient matching process may be more challenging.
Additionally, the paper does not address the potential computational and communication overhead associated with the gradient matching process. In large-scale distributed learning systems, the need to compute and transmit gradients from the distributed models to the central model could introduce significant computational and bandwidth requirements.
Furthermore, the paper does not explore the robustness of the approach to noisy or adversarial environments, where the distributed models may be unreliable or even malicious. It would be valuable to understand how the Interpretable Data Fusion approach would perform in the presence of such challenges.
Despite these potential limitations, the paper represents an important step forward in the quest for more transparent and trustworthy distributed learning systems. The authors have demonstrated the potential benefits of their approach and have laid the groundwork for further research in this area.
Conclusion
This paper presents a novel approach called "Interpretable Data Fusion for Distributed Learning" that aims to make distributed learning systems more transparent and understandable. The key innovation is the use of "gradient matching" to fuse the gradients from multiple distributed models, allowing a central model to learn from the distributed models in an interpretable way.
The authors demonstrate the benefits of this approach through experiments, showing that it can improve model performance and interpretability compared to standard distributed learning techniques. This suggests that interpretable data fusion could be a valuable tool for developing more transparent and trustworthy AI systems, particularly in domains where model interpretability is critical, such as healthcare and finance.
While the paper does not address all the potential challenges and limitations of the approach, it represents an important step forward in the field of distributed learning. As AI systems become increasingly ubiquitous and influential, the need for more interpretable and accountable machine learning models will only grow. The Interpretable Data Fusion approach described in this paper could be a valuable contribution to this effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpretable Data Fusion for Distributed Learning: A Representative Approach via Gradient Matching
Mengchen Fan, Baocheng Geng, Keren Li, Xueqian Wang, Pramod K. Varshney
This paper introduces a representative-based approach for distributed learning that transforms multiple raw data points into a virtual representation. Unlike traditional distributed learning methods such as Federated Learning, which do not offer human interpretability, our method makes complex machine learning processes accessible and comprehensible. It achieves this by condensing extensive datasets into digestible formats, thus fostering intuitive human-machine interactions. Additionally, this approach maintains privacy and communication efficiency, and it matches the training performance of models using raw data. Simulation results show that our approach is competitive with or outperforms traditional Federated Learning in accuracy and convergence, especially in scenarios with complex models and a higher number of clients. This framework marks a step forward in integrating human intuition with machine intelligence, which potentially enhances human-machine learning interfaces and collaborative efforts.
Read more5/8/2024

0
Personalized Interpretation on Federated Learning: A Virtual Concepts approach
Peng Yan, Guodong Long, Jing Jiang, Michael Blumenstein
Tackling non-IID data is an open challenge in federated learning research. Existing FL methods, including robust FL and personalized FL, are designed to improve model performance without consideration of interpreting non-IID across clients. This paper aims to design a novel FL method to robust and interpret the non-IID data across clients. Specifically, we interpret each client's dataset as a mixture of conceptual vectors that each one represents an interpretable concept to end-users. These conceptual vectors could be pre-defined or refined in a human-in-the-loop process or be learnt via the optimization procedure of the federated learning system. In addition to the interpretability, the clarity of client-specific personalization could also be applied to enhance the robustness of the training process on FL system. The effectiveness of the proposed method have been validated on benchmark datasets.
Read more7/1/2024

0
Federated Impression for Learning with Distributed Heterogeneous Data
Sana Ayromlou, Atrin Arya, Armin Saadat, Purang Abolmaesumi, Xiaoxiao Li
Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.
Read more9/12/2024
0
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
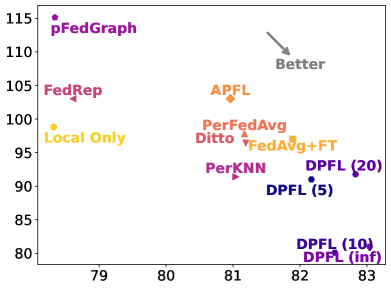
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
Read more6/11/2024