I/O-efficient iterative matrix inversion with photonic integrated circuits

0
🏅
Sign in to get full access
Overview
- Photonic integrated circuits have the potential to overcome the speed limitations of digital electronics, but face challenges with input/output (IO) bottlenecks.
- The paper introduces a novel "photonic iterative processor" (PIP) that aims to break the IO bottleneck by reusing input data directly in the optical domain.
- The PIP demonstrates advantages for matrix inversion and integral-differential equation solving, with a net inversion time of 1.2 ns.
- The PIP shows potential for at least an order of magnitude improvement in IO efficiency over other photonic and electronic processors for certain tasks, indicating its promise for practical applications.
Plain English Explanation
Photonic integrated circuits are a type of technology that use light instead of electricity to process information. This has the potential to be much faster than traditional digital electronics. However, one of the key challenges has been the bottleneck in getting data in and out of these photonic systems.
This paper introduces a new kind of photonic processor called a "photonic iterative processor" (PIP) that helps overcome this IO bottleneck. The key idea is that the PIP can reuse the input data directly in the optical domain, without having to constantly move it back and forth between optical and electronic components.
The researchers demonstrate that the PIP has notable advantages for tasks like matrix inversion and solving integral-differential equations. For example, they show a PIP can perform matrix inversion in just 1.2 nanoseconds.
Furthermore, the researchers estimate that the PIP could provide at least 10 times more efficient IO performance compared to other state-of-the-art photonic and electronic processors for certain tasks like reservoir training and MIMO precoding. This suggests the PIP technology has huge potential for real-world applications that require fast, efficient matrix-intensive computations.
Technical Explanation
The key innovation of the photonic iterative processor (PIP) is its ability to directly reuse input data in the optical domain, without having to constantly convert between optical and electronic signals. This helps overcome the bottleneck of input/output (IO) bandwidth that has been a major challenge for photonic integrated circuits.
The researchers demonstrate two specific implementations of the PIP concept:
-
A lossless PIP for real-valued matrix inversion and integral-differential equation solving. This system uses optical paths to directly reuse the input data, avoiding the need for electronic-to-optical conversion.
-
A coherent PIP that integrates optical loops on-chip to enable complex-valued computations. This allows the PIP to perform a full matrix inversion in just 1.2 ns.
Through analytical modeling and simulations, the researchers estimate that the IO efficiency of the PIP can be at least an order of magnitude better than both state-of-the-art photonic single-pass processors and leading electronic processors. This advantage is highlighted for tasks like reservoir training and MIMO precoding.
Critical Analysis
The paper provides a compelling proof-of-concept for the PIP architecture and demonstrates its potential advantages over alternative photonic and electronic approaches. However, the research also acknowledges several important caveats and areas for future work:
- The experiments and simulations are limited to relatively small problem sizes, and the scalability of the PIP approach to larger matrices is not fully explored.
- The impact of practical implementation challenges like thermal crosstalk and optical loss on the PIP's performance is not deeply investigated.
- While the IO efficiency advantages are promising, the paper does not provide a full system-level comparison of power consumption, chip area, and other practical considerations compared to other processors.
Further research will be needed to fully understand the strengths, limitations, and tradeoffs of the PIP approach across a wider range of applications and system-level metrics. Nonetheless, this work represents an important step forward in addressing the IO bottleneck for photonic integrated circuits.
Conclusion
The photonic iterative processor (PIP) introduced in this paper offers a novel approach to overcoming the input/output (IO) bottleneck that has hindered the widespread adoption of photonic integrated circuits. By directly reusing input data in the optical domain, the PIP demonstrates significant IO efficiency advantages over both state-of-the-art photonic and electronic processors for certain matrix-intensive applications.
While further research is needed to fully understand the PIP's scalability and practical implementation challenges, this work highlights the immense potential of PIP technology to enable fast, efficient optical processing that could break through the speed limitations of digital electronics. If successfully developed, PIP-based systems could have transformative impacts on a wide range of fields, from machine learning to software-defined networking and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
I/O-efficient iterative matrix inversion with photonic integrated circuits
Minjia Chen, Yizhi Wang, Chunhui Yao, Adrian Wonfor, Shuai Yang, Richard Penty, Qixiang Cheng
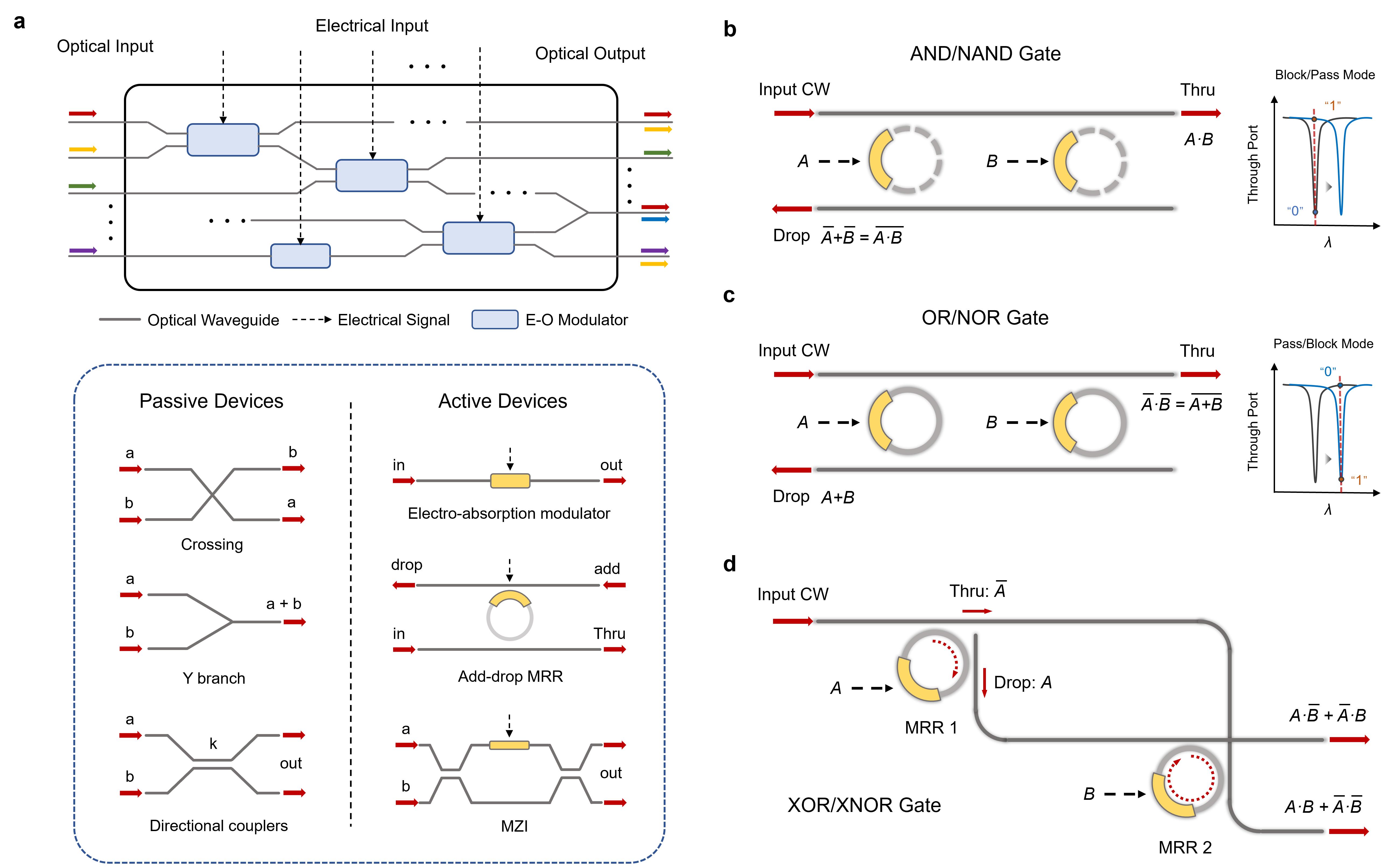
Photonic integrated circuits have been extensively explored for optical processing with the aim of breaking the speed bottleneck of digital electronics. However, the input/output (IO) bottleneck remains one of the key barriers. Here we report a novel photonic iterative processor (PIP) for matrix-inversion-intensive applications. The direct reuse of inputted data in the optical domain unlocks the potential to break the IO bottleneck. We demonstrate notable IO advantages with a lossless PIP for real-valued matrix inversion and integral-differential equation solving, as well as a coherent PIP with optical loops integrated on-chip, enabling complex-valued computation and a net inversion time of 1.2 ns. Furthermore, we estimate at least an order of magnitude enhancement in IO efficiency of a PIP over photonic single-pass processors and the state-of-the-art electronic processors for reservoir training tasks and MIMO precoding tasks, indicating the huge potential of PIP technology in practical applications.
Read more5/24/2024
0
Photonic-Electronic Integrated Circuits for High-Performance Computing and AI Accelerators
Shupeng Ning, Hanqing Zhu, Chenghao Feng, Jiaqi Gu, Zhixing Jiang, Zhoufeng Ying, Jason Midkiff, Sourabh Jain, May H. Hlaing, David Z. Pan, Ray T. Chen
In recent decades, the demand for computational power has surged, particularly with the rapid expansion of artificial intelligence (AI). As we navigate the post-Moore's law era, the limitations of traditional electrical digital computing, including process bottlenecks and power consumption issues, are propelling the search for alternative computing paradigms. Among various emerging technologies, integrated photonics stands out as a promising solution for next-generation high-performance computing, thanks to the inherent advantages of light, such as low latency, high bandwidth, and unique multiplexing techniques. Furthermore, the progress in photonic integrated circuits (PICs), which are equipped with abundant photoelectronic components, positions photonic-electronic integrated circuits as a viable solution for high-performance computing and hardware AI accelerators. In this review, we survey recent advancements in both PIC-based digital and analog computing for AI, exploring the principal benefits and obstacles of implementation. Additionally, we propose a comprehensive analysis of photonic AI from the perspectives of hardware implementation, accelerator architecture, and software-hardware co-design. In the end, acknowledging the existing challenges, we underscore potential strategies for overcoming these issues and offer insights into the future drivers for optical computing.
Read more7/15/2024

0
Programming universal unitary transformations on a general-purpose silicon photonics platform
Jose Roberto Rausell-Campo, Daniel P'erez, L'opez, Jos'e Capmany Francoy
General-purpose programmable photonic processors provide a versatile platform for integrating diverse functionalities on a single chip. Leveraging a two-dimensional hexagonal waveguide mesh of Mach-Zehnder interferometers, these systems have demonstrated significant potential in microwave photonics applications. Additionally, they are a promising platform for creating unitary linear transformations, which are key elements in quantum computing and photonic neural networks. However, a general procedure for implementing these transformations on such systems has not been established yet. This work demonstrates the programming of universal unitary transformations on a general-purpose programmable photonic circuit with a hexagonal topology. We detail the steps to split the light on-chip, demonstrate that an equivalent structure to the Mach-Zehnder interferometer with one internal and one external phase shifter can be built in the hexagonal mesh, and program both the triangular and rectangular architectures for matrix multiplication. We recalibrate the system to account for passive phase deviations. Experimental programming of 3x3 and 4x4 random unitary matrices yields fidelities > 98% and bit precisions over 5 bits. To the best of our knowledge, this is the first time that random unitary matrices are demonstrated on a general-purpose photonic processor and pave the way for the implementation of programmable photonic circuits in optical computing and signal processing systems.
Read more7/4/2024
🤯
0
A symmetric silicon microring resonator optical crossbar array for accelerated inference and training in deep learning
Rui Tang, Shuhei Ohno, Ken Tanizawa, Kazuhiro Ikeda, Makoto Okano, Kasidit Toprasertpong, Shinichi Takagi, Mitsuru Takenaka
Photonic integrated circuits are emerging as a promising platform for accelerating matrix multiplications in deep learning, leveraging the inherent parallel nature of light. Although various schemes have been proposed and demonstrated to realize such photonic matrix accelerators, the in-situ training of artificial neural networks using photonic accelerators remains challenging due to the difficulty of direct on-chip backpropagation on a photonic chip. In this work, we propose a silicon microring resonator (MRR) optical crossbar array with a symmetric structure that allows for simple on-chip backpropagation, potentially enabling the acceleration of both the inference and training phases of deep learning. We demonstrate a $4 times 4$ circuit on a Si-on-insulator (SOI) platform and use it to perform inference tasks of a simple neural network for classifying Iris flowers, achieving a classification accuracy of 93.3%. Subsequently, we train the neural network using simulated on-chip backpropagation and achieve an accuracy of 91.1% in the same inference task after training. Furthermore, we simulate a convolutional neural network (CNN) for handwritten digit recognition, using a $9 times 9$ MRR crossbar array to perform the convolution operations. This work contributes to the realization of compact and energy-efficient photonic accelerators for deep learning.
Read more6/4/2024