iRAG: An Incremental Retrieval Augmented Generation System for Videos
2404.12309
0
0

Abstract
Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
Create account to get full access
Overview
- The paper presents a novel system called iRAG (Incremental Retrieval Augmented Generation) for generating video content using a large language model (LLM) and retrieval-augmented generation techniques.
- iRAG aims to improve upon existing retrieval-augmented generation (RAG) models by incrementally building and updating the retrieval knowledge base during the generation process.
- The system leverages multimodal data, including video, text, and other relevant information, to provide more comprehensive and context-aware video generation capabilities.
Plain English Explanation
iRAG: An Incremental Retrieval Augmented Generation System for Videos is a new approach to generating video content using artificial intelligence (AI). The researchers developed a system that combines a large language model (a type of AI that can generate human-like text) with a retrieval-based technique.
The key idea behind iRAG is to continuously update the system's knowledge base as it generates the video content. This is different from traditional retrieval-augmented generation (RAG) models, which use a fixed knowledge base. By updating the knowledge base incrementally, iRAG can incorporate more relevant information and provide more comprehensive and context-aware video generation.
The system uses multimodal data, which means it can draw upon various types of information, such as video, text, and other relevant data. This allows iRAG to generate videos that are more accurate, informative, and engaging compared to models that only use a single type of data.
Technical Explanation
iRAG: An Incremental Retrieval Augmented Generation System for Videos is a novel system that combines a large language model (LLM) with a retrieval-augmented generation (RAG) approach to generate video content.
The key innovation of iRAG is its ability to incrementally build and update the retrieval knowledge base during the generation process. This is in contrast to traditional RAG models, which use a fixed knowledge base. By continuously updating the knowledge base, iRAG can incorporate more relevant information and provide more comprehensive and context-aware video generation.
The system leverages multimodal data, including video, text, and other relevant information, to inform the generation process. This multimodal approach allows iRAG to generate videos that are more accurate, informative, and engaging compared to models that only use a single type of data.
The paper describes the architecture and training process of iRAG, as well as the results of experiments that demonstrate the system's performance on various video generation tasks. The researchers also provide insights into the benefits and limitations of their approach, highlighting areas for further research and improvement.
Critical Analysis
The iRAG paper presents a promising approach to video generation using retrieval-augmented generation techniques. The key strength of the system is its ability to continuously update the knowledge base during the generation process, which allows it to incorporate more relevant information and provide more context-aware video content.
However, the paper also acknowledges some limitations and areas for further research. For example, the researchers note that the current implementation of iRAG is computationally intensive and may not be scalable to large-scale video generation tasks. Additionally, the paper does not address potential biases or privacy concerns that may arise from the use of multimodal data in the generation process.
Further research could explore ways to optimize the computational efficiency of the iRAG system, as well as investigate strategies to mitigate potential biases and privacy issues. Additionally, it would be valuable to see how iRAG performs on a more diverse range of video generation tasks and to compare its performance to other state-of-the-art video generation models.
Overall, the iRAG paper presents an interesting and promising approach to video generation that could have significant implications for various applications, such as content creation, education, and entertainment. However, as with any emerging technology, it is important to carefully consider the potential risks and limitations of the system as the research in this area continues to evolve.
Conclusion
The iRAG paper introduces a novel system for generating video content using a large language model and retrieval-augmented generation techniques. The key innovation of iRAG is its ability to incrementally build and update the retrieval knowledge base during the generation process, allowing for more comprehensive and context-aware video generation.
The system's use of multimodal data, including video, text, and other relevant information, is a significant strength, as it enables the generation of more accurate, informative, and engaging video content. While the paper acknowledges some limitations and areas for further research, the overall approach presented in the iRAG paper holds promise for advancing the state of the art in video generation and potentially impacting a wide range of applications.
As the field of artificial intelligence continues to evolve, innovative systems like iRAG will play a crucial role in pushing the boundaries of what is possible in content creation, education, and beyond. The critical analysis and insights provided in this blog post aim to encourage readers to think critically about the research and form their own informed opinions on the potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
Diji Yang, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Jie Yang, Yi Zhang
0
0
Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
5/24/2024
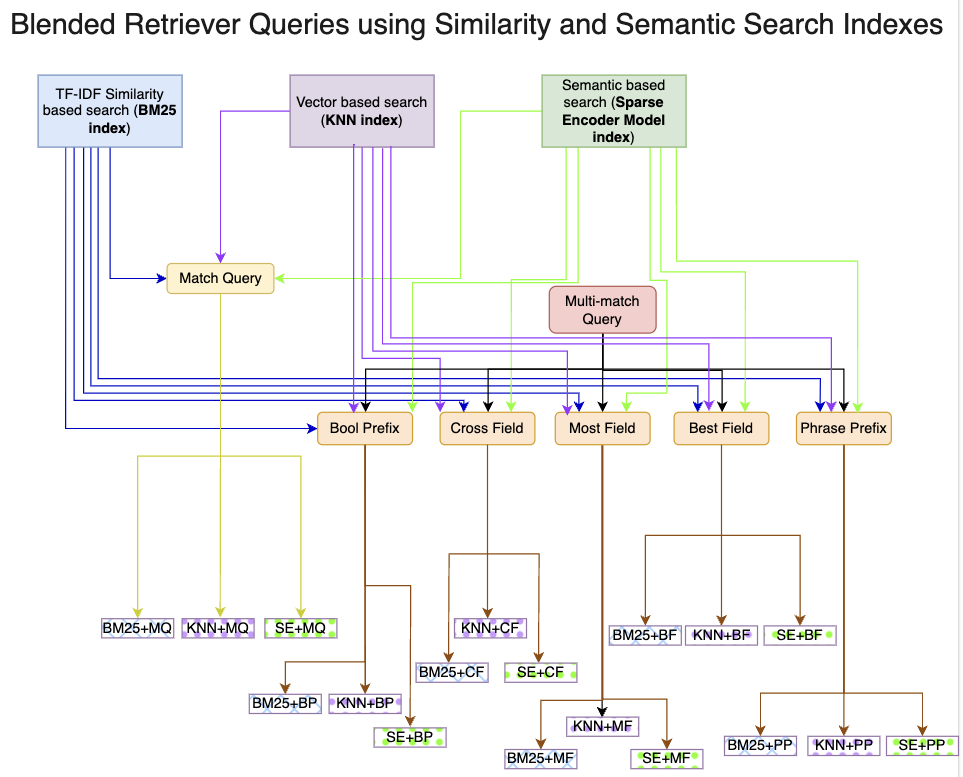
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024

Retrieval-Augmented Generation for AI-Generated Content: A Survey
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, Bin Cui
0
0
Advancements in model algorithms, the growth of foundational models, and access to high-quality datasets have propelled the evolution of Artificial Intelligence Generated Content (AIGC). Despite its notable successes, AIGC still faces hurdles such as updating knowledge, handling long-tail data, mitigating data leakage, and managing high training and inference costs. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances the generation process by retrieving relevant objects from available data stores, leading to higher accuracy and better robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator, distilling the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Github: https://github.com/PKU-DAIR/RAG-Survey.
6/3/2024
🛸
New!Searching for Best Practices in Retrieval-Augmented Generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, Xuanjing Huang
0
0
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a retrieval as generation strategy.
7/2/2024