IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
2405.13021
0
0
🛸
Abstract
Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
Create account to get full access
Overview
- Retrieval-Augmented Generation (RAG) models can enhance the outputs of Large Language Models (LLMs) using external knowledge, but they have limitations in flexibility, interpretability, and end-to-end optimization.
- The paper proposes a novel approach called IM-RAG that integrates Information Retrieval (IR) systems with LLMs to support multi-round RAG through learning Inner Monologues (IM).
- IM-RAG uses the LLM as the core Reasoner to propose queries, collect information, and provide final answers, with a Refiner to bridge the gap between the Reasoner and IR modules.
- The entire IM process is optimized using Reinforcement Learning and Supervised Fine-Tuning, and the approach achieves state-of-the-art performance on the HotPotQA benchmark.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, but they sometimes struggle with accuracy and can produce "hallucinations" – information that seems plausible but is not factually correct. To address this, researchers have developed Retrieval-Augmented Generation (RAG) models that can pull in external information from databases or the internet to ground the LLM's outputs in real-world knowledge.
However, current RAG models have some limitations. They can be inflexible in the types of information retrieval (IR) systems they can use, and it can be hard to understand how they make decisions during the multi-step process of retrieving information and generating responses.
To overcome these challenges, the researchers in this paper propose a new approach called IM-RAG. The key innovation is that IM-RAG models the human "inner monologue" – the internal voice we all have that narrates our thoughts. The LLM acts as the "Reasoner" that drives this inner monologue, deciding when to ask for more information from the IR system and when to provide a final answer.
IM-RAG also includes a "Refiner" module that helps bridge the gap between the Reasoner and the IR system, even if they have different capabilities. The whole process is optimized using a combination of reinforcement learning (to encourage the system to make progress) and supervised fine-tuning (to ensure accurate final answers).
The researchers tested IM-RAG on a popular question-answering benchmark called HotPotQA, where the system has to retrieve relevant information and reason over multiple steps to answer complex questions. IM-RAG achieved state-of-the-art results on this task, demonstrating its effectiveness at combining LLMs and IR systems in a flexible and interpretable way.
Technical Explanation
The paper proposes a novel Retrieval-Augmented Generation (RAG) approach called IM-RAG that integrates Information Retrieval (IR) systems with Large Language Models (LLMs) to support multi-round RAG through learning Inner Monologues (IM).
In IM-RAG, the LLM serves as the core Reasoner model, responsible for either proposing queries to collect more information via the Retriever or providing a final answer based on the conversational context. This is done through an IM process that mimics the human inner voice narrating one's thoughts.
To bridge the gap between the Reasoner and the IR modules, which may have varying capabilities, IM-RAG introduces a Refiner that improves the outputs from the Retriever. This allows for more effective multi-round communication between the components.
The entire IM process is optimized using Reinforcement Learning (RL), where a Progress Tracker is incorporated to provide mid-step rewards. The final answer prediction is further optimized via Supervised Fine-Tuning (SFT).
The researchers evaluated IM-RAG on the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that IM-RAG achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules and strong interpretability through the learned inner monologues.
Critical Analysis
The paper presents a compelling approach to addressing some of the key limitations of existing Retrieval-Augmented Generation (RAG) systems that integrate information retrieval (IR) with large language models (LLMs).
One potential area for further research is exploring how IM-RAG could be extended to handle more open-ended, multi-turn conversations, beyond the focused question-answering task used in the HotPotQA benchmark. The inner monologue approach may provide valuable insights for building more natural and interpretable dialogue systems.
Additionally, while the paper demonstrates strong performance on HotPotQA, it would be valuable to evaluate IM-RAG on a wider range of tasks and datasets to further validate its effectiveness and generalizability. Comparisons to other recent RAG-based approaches could also provide additional context.
Finally, the paper does not extensively discuss potential ethical considerations around the use of IM-RAG, such as concerns around bias, fairness, and transparency in AI-powered information retrieval and question-answering systems. These are important factors to consider as the technology matures and is deployed in real-world applications, such as medical consultation tools.
Overall, the IM-RAG approach represents an interesting and promising step forward in the integration of information retrieval and large language models, with the potential to enable more flexible, interpretable, and reliable AI systems.
Conclusion
The paper introduces a novel Retrieval-Augmented Generation (RAG) approach called IM-RAG that integrates information retrieval (IR) systems with large language models (LLMs) to support multi-round reasoning through learning inner monologues (IM).
IM-RAG uses the LLM as a core Reasoner to propose queries, collect information, and provide final answers, with a Refiner to bridge the gap between the Reasoner and IR modules. The entire process is optimized using Reinforcement Learning and Supervised Fine-Tuning, enabling IM-RAG to achieve state-of-the-art performance on the HotPotQA benchmark for retrieval-based, multi-step question-answering.
The IM-RAG approach represents an important step forward in the integration of IR and LLMs, addressing key limitations of existing RAG systems and providing a more flexible, interpretable, and reliable way to leverage external knowledge. As the technology continues to evolve, further research is needed to explore its broader applications and address important ethical considerations around the use of such AI-powered information retrieval and question-answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

iRAG: An Incremental Retrieval Augmented Generation System for Videos
Md Adnan Arefeen, Biplob Debnath, Md Yusuf Sarwar Uddin, Srimat Chakradhar
0
0
Retrieval augmented generation (RAG) systems combine the strengths of language generation and information retrieval to power many real-world applications like chatbots. Use of RAG for combined understanding of multimodal data such as text, images and videos is appealing but two critical limitations exist: one-time, upfront capture of all content in large multimodal data as text descriptions entails high processing times, and not all information in the rich multimodal data is typically in the text descriptions. Since the user queries are not known apriori, developing a system for multimodal to text conversion and interactive querying of multimodal data is challenging. To address these limitations, we propose iRAG, which augments RAG with a novel incremental workflow to enable interactive querying of large corpus of multimodal data. Unlike traditional RAG, iRAG quickly indexes large repositories of multimodal data, and in the incremental workflow, it uses the index to opportunistically extract more details from select portions of the multimodal data to retrieve context relevant to an interactive user query. Such an incremental workflow avoids long multimodal to text conversion times, overcomes information loss issues by doing on-demand query-specific extraction of details in multimodal data, and ensures high quality of responses to interactive user queries that are often not known apriori. To the best of our knowledge, iRAG is the first system to augment RAG with an incremental workflow to support efficient interactive querying of large, real-world multimodal data. Experimental results on real-world long videos demonstrate 23x to 25x faster video to text ingestion, while ensuring that quality of responses to interactive user queries is comparable to responses from a traditional RAG where all video data is converted to text upfront before any querying.
4/19/2024
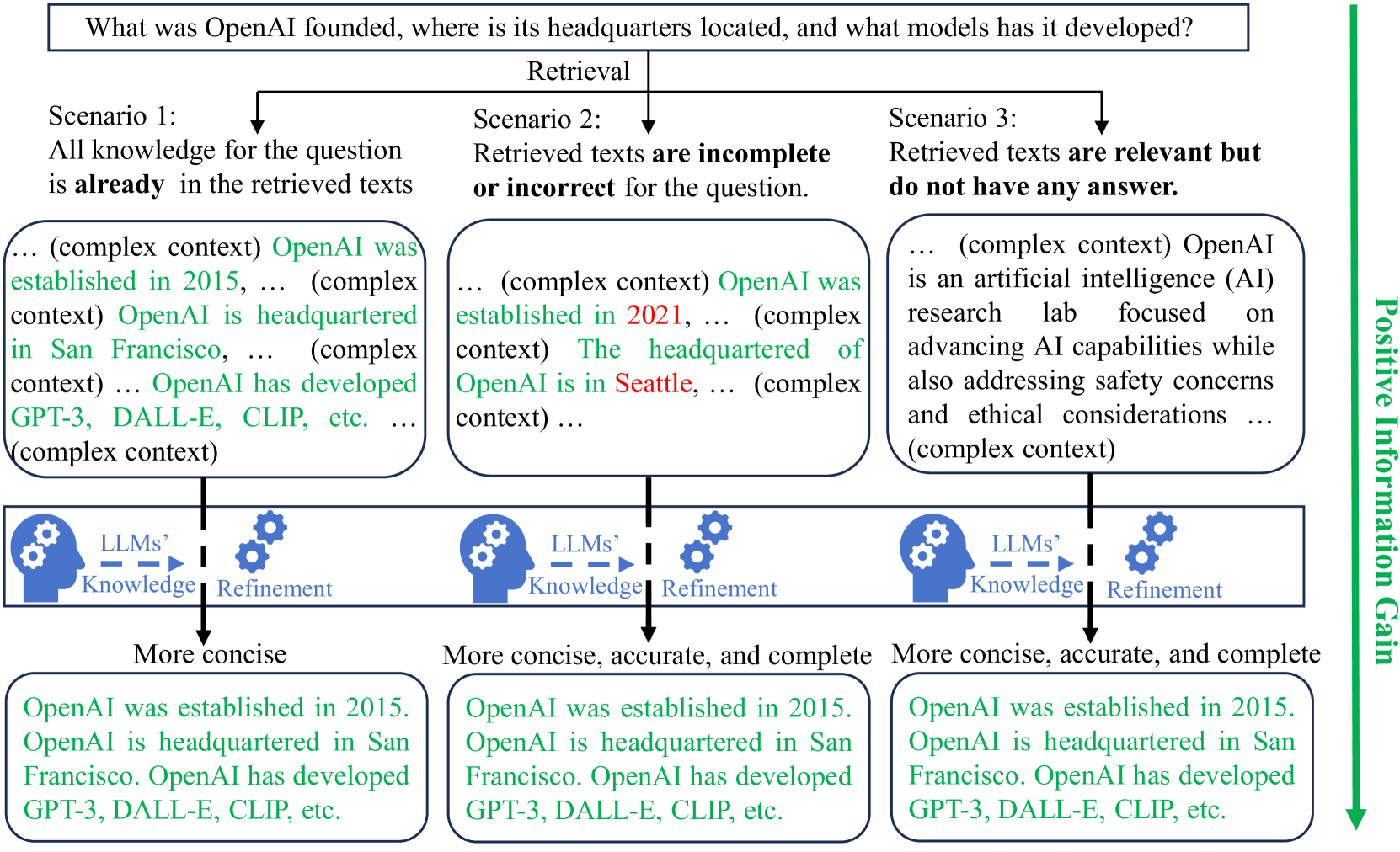
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
0
0
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
6/13/2024

M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions
Zheng Wang, Shu Xian Teo, Jieer Ouyang, Yongjun Xu, Wei Shi
0
0
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant memories from an external database. However, existing RAG methods typically organize all memories in a whole database, potentially limiting focus on crucial memories and introducing noise. In this paper, we introduce a multiple partition paradigm for RAG (called M-RAG), where each database partition serves as a basic unit for RAG execution. Based on this paradigm, we propose a novel framework that leverages LLMs with Multi-Agent Reinforcement Learning to optimize different language generation tasks explicitly. Through comprehensive experiments conducted on seven datasets, spanning three language generation tasks and involving three distinct language model architectures, we confirm that M-RAG consistently outperforms various baseline methods, achieving improvements of 11%, 8%, and 12% for text summarization, machine translation, and dialogue generation, respectively.
5/28/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024