IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models

0
Sign in to get full access
Overview
• This paper introduces IrokoBench, a new benchmark for evaluating large language models on African languages.
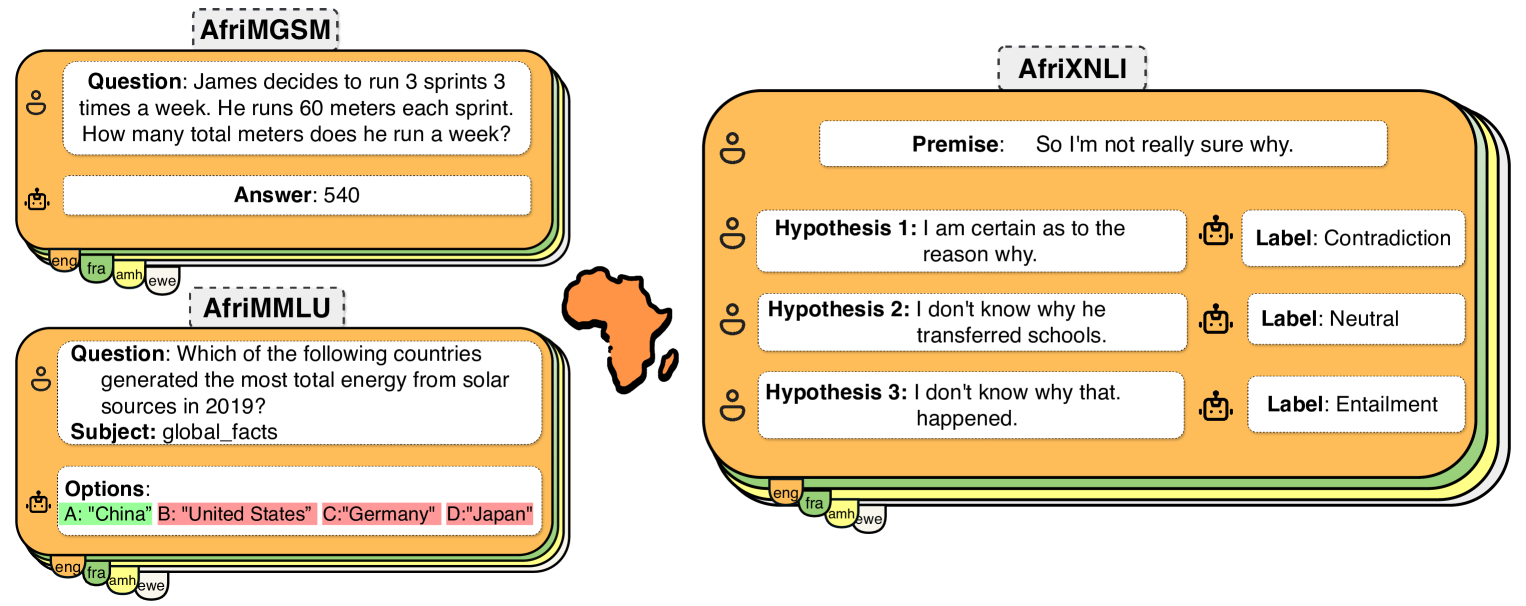
• The benchmark includes tasks such as text classification, named entity recognition, and question answering across 10 diverse African languages.
• The authors evaluate several state-of-the-art language models on IrokoBench and find that while these models perform well on high-resource languages, they struggle on the African languages in the benchmark.
Plain English Explanation
IrokoBench is a new tool that researchers can use to test how well large language models, such as GPT-3 or BERT, perform on African languages. Large language models are AI systems that can understand and generate human-like text, and they've become very powerful in recent years. However, most of these models have been trained primarily on data from high-resource languages like English, so it's unclear how well they work for lower-resource languages, including many African languages.
The IrokoBench benchmark includes a variety of language tasks, such as classifying the topic of a piece of text, identifying important names and entities in text, and answering questions about a passage. It covers 10 different African languages, chosen to represent the linguistic diversity of the continent. By testing large language models on this benchmark, the researchers can get a better sense of how capable these models are for real-world use in African contexts.
The results show that while the language models perform reasonably well on high-resource languages, they struggle significantly on the African languages in the IrokoBench dataset. This suggests that more work is needed to make large language models perform well across a wider range of the world's languages, including those that are less commonly represented in the data used to train these models.
Technical Explanation
The authors introduce IrokoBench, a new benchmark for evaluating the performance of large language models on African languages. The benchmark includes a variety of natural language processing tasks, such as text classification, named entity recognition, and question answering, across 10 diverse African languages.
To create the benchmark, the authors collected data from various sources, including web pages, books, and social media, and carefully curated and annotated it. The languages represented in the benchmark are Amharic, Hausa, Igbo, Kinyarwanda, Luganda, Oromo, Sesotho, Tigrinya, Twi, and Yoruba.
The authors evaluate several state-of-the-art large language models, including BERT, GPT-3, and T5, on the IrokoBench tasks. They find that while these models perform reasonably well on high-resource languages, they struggle significantly on the African languages in the benchmark. This suggests that current large language models are not well-suited for many real-world applications in African contexts.
Critical Analysis
The IrokoBench benchmark represents an important step forward in evaluating the capabilities of large language models on African languages. By focusing on a diverse set of languages and a range of common NLP tasks, the benchmark provides a comprehensive assessment of model performance that goes beyond just a few high-resource languages.
However, the authors acknowledge several limitations of the current benchmark, such as the relatively small size of the datasets and the potential for bias in the data collection process. Additionally, the benchmark does not cover all the languages spoken in Africa, and it remains to be seen how well the findings generalize to other African languages not included in the dataset.
Furthermore, the authors do not delve deeply into the reasons why the large language models struggle on the African languages. It would be valuable to understand the specific linguistic features or data challenges that contribute to the performance gap, as this could inform future efforts to improve model performance.
Overall, the IrokoBench benchmark is a valuable contribution to the field of AI and language technology, as it highlights the pressing need to develop more inclusive and multilingual large language models that can perform well across a wider range of the world's languages, including those that are less commonly represented in current training data.
Conclusion
The IrokoBench benchmark introduced in this paper is a significant step forward in evaluating the performance of large language models on African languages. The authors' findings demonstrate that while these models perform well on high-resource languages, they struggle significantly on the diverse set of African languages included in the benchmark.
This work underscores the importance of developing more inclusive and multilingual language models that can perform well across a wider range of the world's languages, not just those that are most well-represented in current training data. By addressing this challenge, researchers and practitioners can help ensure that the benefits of advanced language technology are more equitably distributed, supporting applications and use cases in African and other underrepresented contexts.
The IrokoBench benchmark provides a valuable tool for tracking progress in this direction and encouraging further research and development to create more robust and inclusive large language models that can truly serve the global community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
David Ifeoluwa Adelani, Jessica Ojo, Israel Abebe Azime, Jian Yun Zhuang, Jesujoba O. Alabi, Xuanli He, Millicent Ochieng, Sara Hooker, Andiswa Bukula, En-Shiun Annie Lee, Chiamaka Chukwuneke, Happy Buzaaba, Blessing Sibanda, Godson Kalipe, Jonathan Mukiibi, Salomon Kabongo, Foutse Yuehgoh, Mmasibidi Setaka, Lolwethu Ndolela, Nkiruka Odu, Rooweither Mabuya, Shamsuddeen Hassan Muhammad, Salomey Osei, Sokhar Samb, Tadesse Kebede Guge, Pontus Stenetorp
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
Read more6/6/2024

0
InkubaLM: A small language model for low-resource African languages
Atnafu Lambebo Tonja, Bonaventure F. P. Dossou, Jessica Ojo, Jenalea Rajab, Fadel Thior, Eric Peter Wairagala, Anuoluwapo Aremu, Pelonomi Moiloa, Jade Abbott, Vukosi Marivate, Benjamin Rosman
High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
Read more9/4/2024
💬
0
EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Atnafu Lambebo Tonja, Israel Abebe Azime, Tadesse Destaw Belay, Mesay Gemeda Yigezu, Moges Ahmed Mehamed, Abinew Ali Ayele, Ebrahim Chekol Jibril, Michael Melese Woldeyohannis, Olga Kolesnikova, Philipp Slusallek, Dietrich Klakow, Shengwu Xiong, Seid Muhie Yimam
Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
Read more6/26/2024
💬
0
How good are Large Language Models on African Languages?
Jessica Ojo, Kelechi Ogueji, Pontus Stenetorp, David Ifeoluwa Adelani
Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on tasks and languages they are not trained on. However, their performance on African languages is largely understudied relative to high-resource languages. We present an analysis of four popular large language models (mT0, Aya, LLaMa 2, and GPT-4) on six tasks (topic classification, sentiment classification, machine translation, summarization, question answering, and named entity recognition) across 60 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce lower performance for African languages, and there is a large gap in performance compared to high-resource languages (such as English) for most tasks. We find that GPT-4 has an average to good performance on classification tasks, yet its performance on generative tasks such as machine translation and summarization is significantly lacking. Surprisingly, we find that mT0 had the best overall performance for cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Similarly, we find the recent Aya model to have comparable result to mT0 in almost all tasks except for topic classification where it outperform mT0. Overall, LLaMa 2 showed the worst performance, which we believe is due to its English and code-centric~(around 98%) pre-training corpus. Our findings confirms that performance on African languages continues to remain a hurdle for the current LLMs, underscoring the need for additional efforts to close this gap.
Read more5/1/2024