Is Complexity an Illusion?
2404.07227
0
0
❗
Abstract
Simplicity is held by many to be the key to general intelligence. Simpler models tend to generalise, identifying the cause or generator of data with greater sample efficiency. The implications of the correlation between simplicity and generalisation extend far beyond computer science, addressing questions of physics and even biology. Yet simplicity is a property of form, while generalisation is of function. In interactive settings, any correlation between the two depends on interpretation. In theory there could be no correlation and yet in practice, there is. Previous theoretical work showed generalisation to be a consequence of weak constraints on implied by function, not form. Experiments demonstrated choosing weak constraints over simple forms yielded a 110-500% improvement in generalisation rate. Here we show that all constraints can take equally simple forms, regardless of weakness. However if forms are spatially extended, then function is represented using a finite subset of forms. If function is represented using a finite subset of forms, then we can force a correlation between simplicity and generalisation by making weak constraints take simple forms. If function determined by a goal directed process (e.g. natural selection), then efficiency demands weak constraints take simple forms. Complexity has no causal influence on generalisation, but appears to due to confounding.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the notion of complexity and whether it is a genuine property of systems or simply an illusion created by our limited perspective.
- The authors investigate key questions about the nature of complexity and its underlying mechanisms.
- They present a critical analysis of the existing research on complexity and offer insights into the potential limitations of our current understanding.
Plain English Explanation
The paper examines the idea of complexity and whether it is a real characteristic of systems or just an illusion caused by our restricted viewpoint. The authors look at important questions about the nature of complexity and how it works at a fundamental level. They provide a thoughtful evaluation of the current research on complexity and point out potential issues with how we currently conceive of it.
Technical Explanation
The paper investigates the concept of complexity and whether it is a genuine property of systems or merely an artifact of our limited perspective. The authors explore key questions about the nature of complexity, such as what it is supposed to indicate and how it arises in different contexts.
The paper critically analyzes the existing research on complexity, drawing on insights from related studies to assess the strengths and limitations of current approaches. The authors also consider how our understanding of causality and the nature of language models might inform our conception of complexity.
Critical Analysis
The paper acknowledges the potential computational dualism inherent in how we define and measure complexity, and suggests that our current frameworks may be insufficient to fully capture the underlying mechanisms. The authors raise important questions about the limitations of our existing models and call for a more nuanced and interdisciplinary approach to understanding complexity.
Conclusion
This paper presents a thought-provoking examination of the nature of complexity, challenging the assumption that it is a straightforward and easily quantifiable property of systems. The authors argue that our understanding of complexity may be shaped by the constraints of our own perspective, and they encourage further research to explore the deeper, more fundamental aspects of this phenomenon.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
The Optimal Choice of Hypothesis Is the Weakest, Not the Shortest
Michael Timothy Bennett
0
0
If $A$ and $B$ are sets such that $A subset B$, generalisation may be understood as the inference from $A$ of a hypothesis sufficient to construct $B$. One might infer any number of hypotheses from $A$, yet only some of those may generalise to $B$. How can one know which are likely to generalise? One strategy is to choose the shortest, equating the ability to compress information with the ability to generalise (a proxy for intelligence). We examine this in the context of a mathematical formalism of enactive cognition. We show that compression is neither necessary nor sufficient to maximise performance (measured in terms of the probability of a hypothesis generalising). We formulate a proxy unrelated to length or simplicity, called weakness. We show that if tasks are uniformly distributed, then there is no choice of proxy that performs at least as well as weakness maximisation in all tasks while performing strictly better in at least one. In experiments comparing maximum weakness and minimum description length in the context of binary arithmetic, the former generalised at between $1.1$ and $5$ times the rate of the latter. We argue this demonstrates that weakness is a far better proxy, and explains why Deepmind's Apperception Engine is able to generalise effectively.
4/12/2024
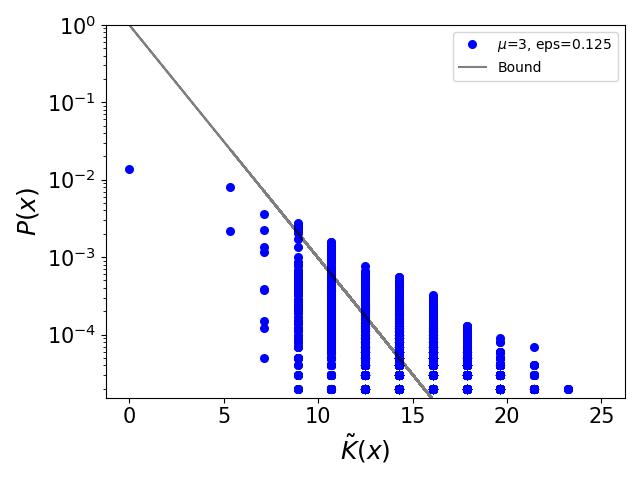
Simplicity bias, algorithmic probability, and the random logistic map
Boumediene Hamzi, Kamaludin Dingle
0
0
Simplicity bias is an intriguing phenomenon prevalent in various input-output maps, characterized by a preference for simpler, more regular, or symmetric outputs. Notably, these maps typically feature high-probability outputs with simple patterns, whereas complex patterns are exponentially less probable. This bias has been extensively examined and attributed to principles derived from algorithmic information theory and algorithmic probability. In a significant advancement, it has been demonstrated that the renowned logistic map and other one-dimensional maps exhibit simplicity bias when conceptualized as input-output systems. Building upon this work, our research delves into the manifestations of simplicity bias within the random logistic map, specifically focusing on scenarios involving additive noise. We discover that simplicity bias is observable in the random logistic map for specific ranges of $mu$ and noise magnitudes. Additionally, we find that this bias persists even with the introduction of small measurement noise, though it diminishes as noise levels increase. Our studies also revisit the phenomenon of noise-induced chaos, particularly when $mu=3.83$, revealing its characteristics through complexity-probability plots. Intriguingly, we employ the logistic map to illustrate a paradoxical aspect of data analysis: more data adhering to a consistent trend can occasionally lead to emph{reduced} confidence in extrapolation predictions, challenging conventional wisdom. We propose that adopting a probability-complexity perspective in analyzing dynamical systems could significantly enrich statistical learning theories related to series prediction and analysis. This approach not only facilitates a deeper understanding of simplicity bias and its implications but also paves the way for novel methodologies in forecasting complex systems behavior.
4/10/2024
👨🏫
Robust agents learn causal world models
Jonathan Richens, Tom Everitt
0
0
It has long been hypothesised that causal reasoning plays a fundamental role in robust and general intelligence. However, it is not known if agents must learn causal models in order to generalise to new domains, or if other inductive biases are sufficient. We answer this question, showing that any agent capable of satisfying a regret bound under a large set of distributional shifts must have learned an approximate causal model of the data generating process, which converges to the true causal model for optimal agents. We discuss the implications of this result for several research areas including transfer learning and causal inference.
4/10/2024
📈
An exactly solvable model for emergence and scaling laws
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Ard Louis
0
0
Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
4/29/2024