Is Knowledge All Large Language Models Needed for Causal Reasoning?
2401.00139
0
0
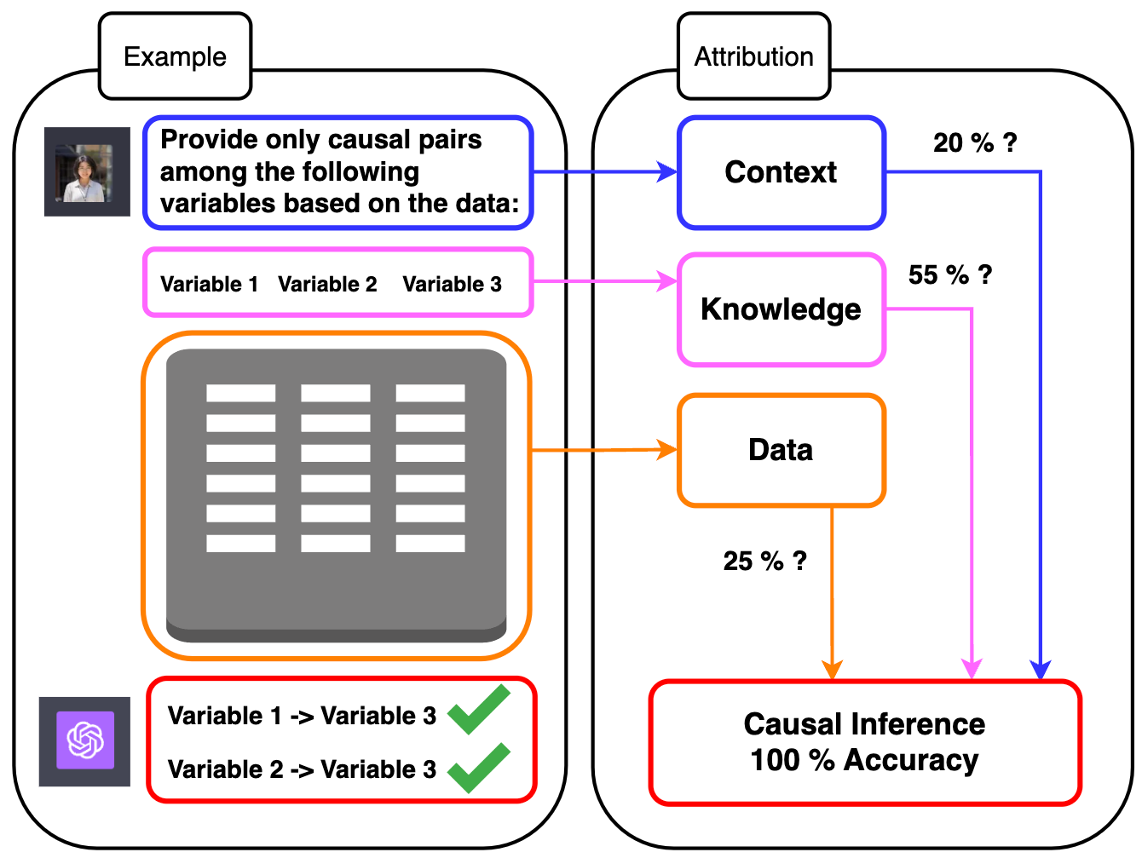
Abstract
This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes ``do-operators for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability mainly depends on the context and domain-specific knowledge provided. In the absence of such knowledge, LLMs can still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations. This motivates the proposed fine-tuned LLM for pairwise causal discovery, effectively leveraging both knowledge and numerical information.
Create account to get full access
Overview
- This paper investigates whether large language models (LLMs) have the necessary knowledge to reason about causal relationships, or if additional training is required.
- The researchers developed a causal attribution model and conducted experiments to evaluate the causal reasoning capabilities of LLMs.
- The findings suggest that while LLMs have some causal reasoning abilities, they may require additional training or architectural changes to fully capture the complexities of causal inference.
Plain English Explanation
Causal reasoning is the ability to understand how different factors or events are connected and how changes in one thing can affect another. This is an important skill for making decisions and understanding the world around us.
The researchers in this paper wanted to see if large language models (LLMs) - powerful AI systems that can understand and generate human-like text - have the necessary knowledge and capabilities to reason about causal relationships. LLMs are trained on vast amounts of text data, which could potentially give them the knowledge needed for causal reasoning.
To test this, the researchers developed a "causal attribution model" - a way of evaluating how well an AI system can identify the causes of different outcomes. They then conducted experiments where they asked LLMs to reason about various causal scenarios.
The results suggest that LLMs do have some ability to reason about causality, but they may not be as proficient as humans. The researchers found that LLMs could sometimes identify the correct causes of events, but they also made mistakes or struggled with more complex causal relationships.
This suggests that while LLMs have a lot of knowledge from their training, they may still need additional specialized training or architectural changes to fully capture the nuances of causal reasoning. The researchers argue that improving the causal reasoning capabilities of LLMs could be an important step in making these systems more reliable and effective for real-world applications.
Technical Explanation
The paper presents a causal attribution model to evaluate the causal reasoning capabilities of large language models (LLMs). The model aims to assess how well an AI system can identify the causes of different outcomes.
In the experiment design, the researchers created a dataset of short narratives describing causal scenarios. They then asked various LLMs, including GPT-3, to read the narratives and identify the key causal factors.
The results suggest that while LLMs have some ability to reason about causality, they may not be as proficient as humans. The researchers found that LLMs could sometimes correctly identify the causes of events, but they also made mistakes or struggled with more complex causal relationships.
The findings indicate that additional training or architectural changes may be needed to improve the causal reasoning capabilities of LLMs. The researchers argue that enhancing the causal reasoning abilities of LLMs could be an important step in making these systems more reliable and effective for real-world applications that require understanding and reasoning about causal relationships.
Critical Analysis
The paper provides a thoughtful and rigorous investigation into the causal reasoning capabilities of large language models (LLMs). The researchers' development of a causal attribution model and the design of their experiments are well-executed and offer valuable insights.
One potential limitation of the study is the relatively limited scope of the causal scenarios used in the experiments. While the researchers aimed to create a diverse set of narratives, the findings may not fully capture the breadth of causal reasoning required in real-world situations. Expanding the range of causal scenarios, perhaps by drawing on a wider variety of domains, could further test the limits of LLMs' causal reasoning abilities.
Additionally, the paper does not delve deeply into the specific architectural or training factors that may be contributing to the observed limitations in LLMs' causal reasoning. Exploring these technical details could provide more actionable insights for researchers and developers looking to enhance the causal reasoning capabilities of these models.
Despite these minor caveats, the paper makes a compelling case for the importance of improving causal reasoning in large language models. As these systems become more ubiquitous in decision-making and real-world applications, their ability to understand and reason about causal relationships will be crucial. The researchers' work in this area is a valuable contribution to the ongoing efforts to advance the causal reasoning capabilities of LLMs.
Conclusion
This paper investigates the causal reasoning capabilities of large language models (LLMs), exploring whether these powerful AI systems have the necessary knowledge and abilities to understand and reason about causal relationships. The researchers developed a causal attribution model and conducted experiments to evaluate the performance of LLMs in various causal reasoning tasks.
The findings suggest that while LLMs do possess some causal reasoning capabilities, they may not be as proficient as humans in this area. The researchers identified limitations in the LLMs' ability to correctly identify the causes of events, particularly in more complex causal scenarios.
These results highlight the need for further research and development to enhance the causal reasoning abilities of LLMs. Improving these capabilities could be crucial for the reliable and effective deployment of these systems in real-world applications that require a deep understanding of causal relationships. By addressing the challenges identified in this paper, researchers and developers can work towards building LLMs that are more adept at causal reasoning, ultimately making these powerful AI tools more valuable and trustworthy in a wide range of contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
0
0
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
4/17/2024
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024
Large Language Models for Constrained-Based Causal Discovery
Kai-Hendrik Cohrs, Gherardo Varando, Emiliano Diaz, Vasileios Sitokonstantinou, Gustau Camps-Valls
0
0
Causality is essential for understanding complex systems, such as the economy, the brain, and the climate. Constructing causal graphs often relies on either data-driven or expert-driven approaches, both fraught with challenges. The former methods, like the celebrated PC algorithm, face issues with data requirements and assumptions of causal sufficiency, while the latter demand substantial time and domain knowledge. This work explores the capabilities of Large Language Models (LLMs) as an alternative to domain experts for causal graph generation. We frame conditional independence queries as prompts to LLMs and employ the PC algorithm with the answers. The performance of the LLM-based conditional independence oracle on systems with known causal graphs shows a high degree of variability. We improve the performance through a proposed statistical-inspired voting schema that allows some control over false-positive and false-negative rates. Inspecting the chain-of-thought argumentation, we find causal reasoning to justify its answer to a probabilistic query. We show evidence that knowledge-based CIT could eventually become a complementary tool for data-driven causal discovery.
6/12/2024
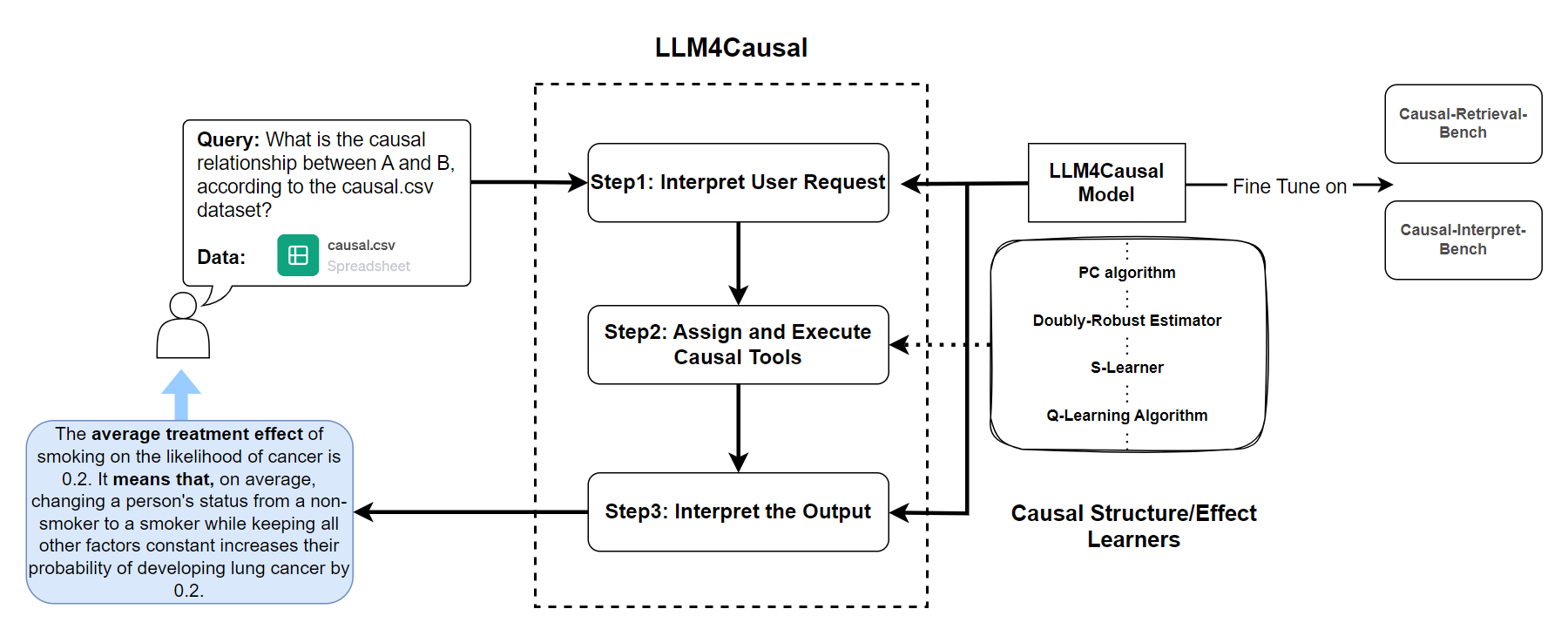
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024