Evaluating Interventional Reasoning Capabilities of Large Language Models
2404.05545
0
0
Abstract
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper evaluates the ability of large language models (LLMs) to perform interventional reasoning, which involves understanding how changes to some variables affect other variables in a causal system.
- The researchers designed a set of tasks to test the causal reasoning capabilities of different LLMs, including GPT-3, Chinchilla, and PaLM.
- The results suggest that current LLMs have limited interventional reasoning abilities, and the authors discuss potential ways to improve these capabilities.
Plain English Explanation
This research paper looks at how well large language models, which are AI systems trained on vast amounts of text data, can reason about cause and effect relationships. The researchers wanted to see if these models could understand how changing one thing (an "intervention") would impact other things in a complex system.
To test this, the researchers created a series of tasks that required the language models to predict the effects of hypothetical changes. For example, they might ask the model what would happen to a person's income if their education level changed. The models were then evaluated on how well they could make these kinds of predictions.
The results showed that current large language models, like GPT-3, Chinchilla, and PaLM, have relatively limited abilities when it comes to this type of causal reasoning. They struggled to accurately forecast the downstream effects of interventions.
The researchers discuss potential ways to improve the causal reasoning capabilities of these language models, such as by incorporating more explicit information about causal relationships or using smaller, more specialized models to complement the capabilities of larger language models.
Overall, this study highlights an important limitation in the reasoning abilities of current large language models and suggests that more work is needed to develop AI systems that can truly understand cause and effect.
Technical Explanation
The paper "Evaluating Interventional Reasoning Capabilities of Large Language Models" investigates the ability of large language models (LLMs) to perform interventional reasoning. Interventional reasoning involves understanding how changes to some variables (interventions) affect other variables in a causal system.
To assess the causal reasoning capabilities of LLMs, the researchers designed a set of tasks where the models were asked to predict the effects of hypothetical interventions on target variables. The tasks covered a range of causal scenarios, including those involving confounding variables, mediating variables, and colliders.
The researchers evaluated the performance of several prominent LLMs, including GPT-3, Chinchilla, and PaLM, on these interventional reasoning tasks. The results showed that the current generation of LLMs has limited abilities when it comes to this type of causal reasoning. The models struggled to accurately forecast the downstream effects of interventions, particularly in more complex causal scenarios.
The paper discusses potential reasons for the LLMs' poor performance, such as a lack of explicit causal knowledge in the training data or the models' tendencies to rely on statistical associations rather than true causal understanding. The authors also suggest ways to enhance the causal reasoning capabilities of LLMs, such as by incorporating causal inductive biases or using more targeted, causal-aware training approaches.
Overall, this study highlights an important limitation in the current state of large language models and underscores the need for further research and development to create AI systems that can truly understand and reason about causal relationships.
Critical Analysis
The paper provides a compelling and rigorous evaluation of the interventional reasoning capabilities of large language models. The researchers have designed a well-structured set of tasks that effectively test the models' ability to reason about causal relationships and the effects of interventions.
One potential caveat is that the study focuses on a relatively narrow set of causal scenarios, and it's unclear how the models would perform on a wider range of causal structures and contexts. The authors acknowledge this limitation and suggest that future research should explore a more diverse set of causal tasks.
Additionally, while the paper discusses potential reasons for the LLMs' poor performance, such as a lack of explicit causal knowledge in the training data, it would be valuable to see a more in-depth analysis of the models' internal representations and decision-making processes. This could provide further insights into the underlying limitations of current language models when it comes to causal reasoning.
Another area for potential further research is the impact of model size and architecture on causal reasoning capabilities. The paper compares the performance of several prominent LLMs, but it would be interesting to explore whether smaller, more specialized models or alternative architectural approaches could offer improved interventional reasoning abilities.
Overall, this paper makes an important contribution to our understanding of the limitations of large language models in the realm of causal reasoning. The findings highlight the need for continued research and development to create AI systems that can more effectively reason about cause and effect relationships.
Conclusion
This research paper has evaluated the interventional reasoning capabilities of large language models, which involves understanding how changes to some variables affect other variables in a causal system. The results suggest that current LLMs, including GPT-3, Chinchilla, and PaLM, have relatively limited abilities when it comes to this type of causal reasoning.
The study highlights an important limitation in the current state of large language models and underscores the need for further research and development to create AI systems that can truly understand and reason about causal relationships. Potential avenues for improvement include incorporating more explicit causal knowledge, using smaller, more specialized models, and exploring alternative architectural approaches.
As AI continues to advance and become more integrated into various aspects of our lives, it is crucial that we develop systems with robust causal reasoning capabilities. This research paper provides valuable insights and a foundation for future work in this important area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
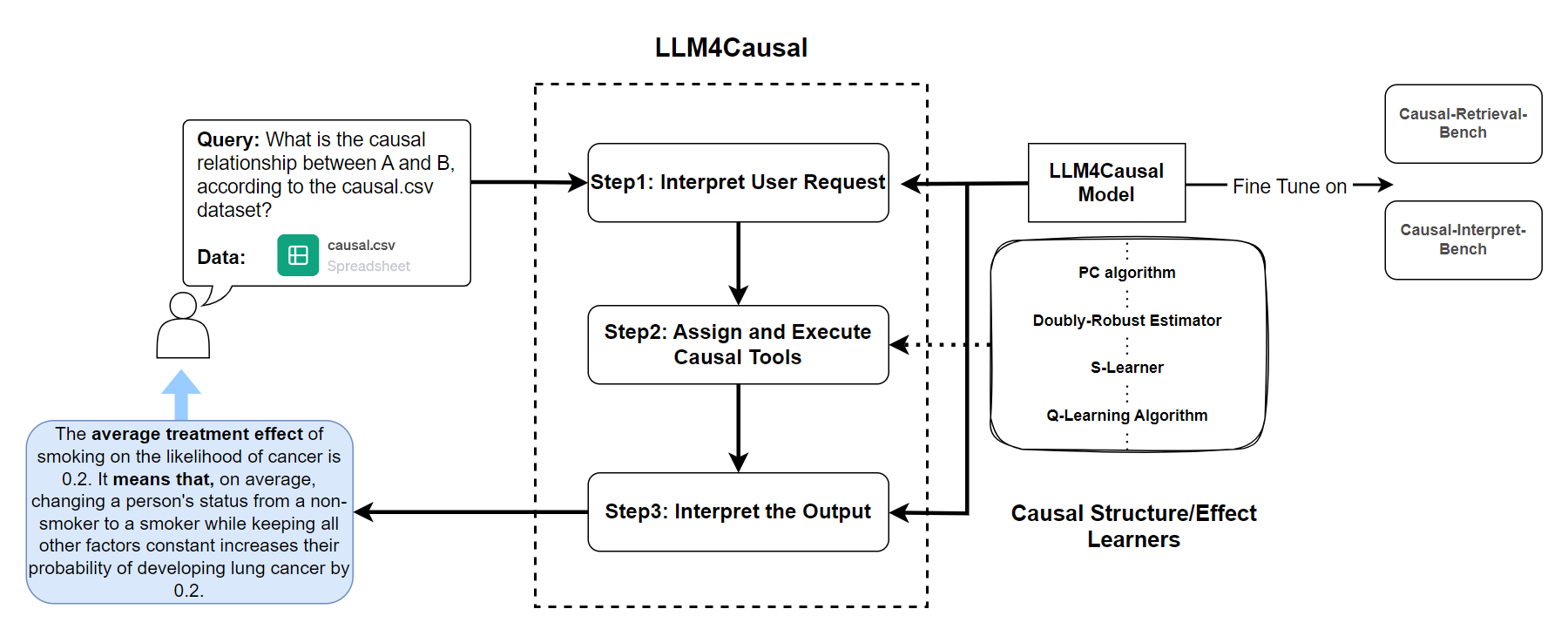
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
0
0
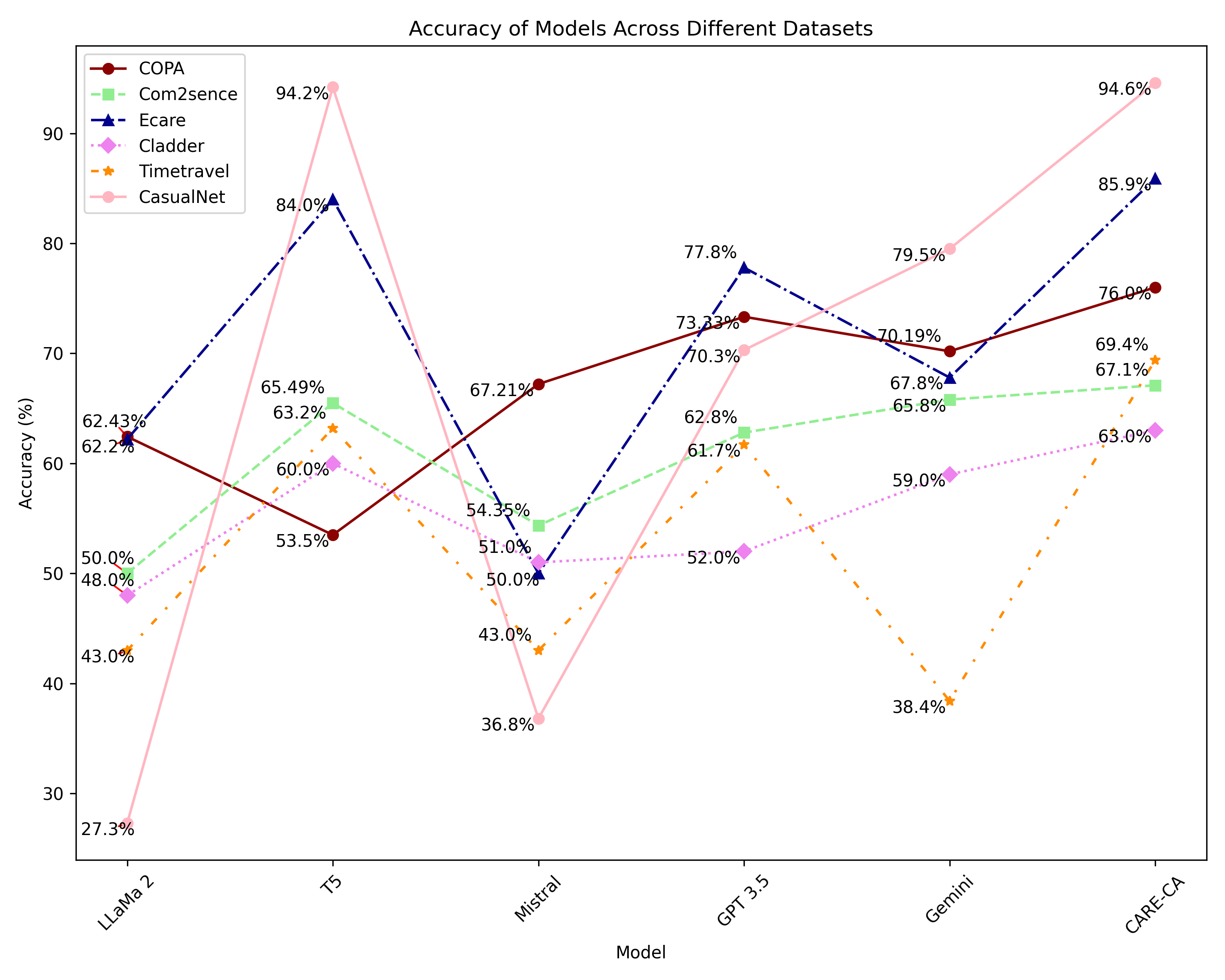
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
4/17/2024
💬
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
0
0
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
4/23/2024