Iterative thresholding for non-linear learning in the strong $varepsilon$-contamination model

0
📈
Sign in to get full access
Overview
- This paper presents an iterative thresholding algorithm for non-linear learning in the strong ε-contamination model.
- The algorithm is designed to be robust to outliers and can learn non-linear target functions.
- The authors provide theoretical guarantees on the algorithm's performance and demonstrate its effectiveness on various experiments.
Plain English Explanation
The paper introduces a new technique called Iterative Thresholding for learning complex, non-linear relationships in data, even when some of the data is corrupted or contains outliers.
Imagine you're trying to predict a person's income based on their education, age, and other factors. The relationship between these variables is often non-linear and can be difficult to model accurately. Traditional machine learning algorithms may struggle in the presence of outliers or corrupted data points.
The Iterative Thresholding approach works by iteratively refining the model, gradually identifying and removing the corrupted data points. This makes the algorithm more robust to outliers and allows it to better capture the underlying non-linear patterns in the data.
The paper provides mathematical guarantees on the algorithm's performance and demonstrates its effectiveness on various real-world datasets. This represents an important advance in the field of robust and flexible machine learning models.
Technical Explanation
The paper introduces an Iterative Thresholding algorithm for non-linear learning in the strong ε-contamination model.
The key idea is to learn a non-linear target function f(x) from data that may be corrupted by outliers. The algorithm proceeds in an iterative fashion, where in each iteration, it:
- Estimates the current model parameters using a robust loss function.
- Identifies and removes data points that are likely to be outliers based on a thresholding rule.
- Updates the model parameters using the remaining, "clean" data points.
This iterative process continues until convergence, with the goal of learning an accurate non-linear model while being robust to the presence of outliers.
The authors provide theoretical guarantees on the algorithm's performance, showing that it can achieve near-optimal statistical rates of convergence under certain assumptions. They also demonstrate the effectiveness of the Iterative Thresholding approach on both synthetic and real-world datasets, where it outperforms alternative robust learning methods.
Critical Analysis
The paper presents a well-designed and theoretically grounded algorithm for robust non-linear learning. The authors consider an important and practical setting where the data may be contaminated by outliers, which can significantly degrade the performance of standard machine learning techniques.
One potential limitation of the approach is that it relies on the strong ε-contamination model, which assumes a specific structure of the outliers. In practice, the distribution of outliers may not always conform to this model, and the algorithm's performance may suffer in such cases.
Additionally, the theoretical analysis makes several assumptions, such as the smoothness and curvature of the target function, which may not always hold in real-world applications. It would be interesting to see how the algorithm performs under more relaxed assumptions or in the presence of other types of data corruption, such as adversarial attacks.
Overall, the Iterative Thresholding algorithm represents a promising approach for robust non-linear learning, and the paper provides valuable insights and theoretical guarantees. Further research exploring its practical applications and limitations would be a valuable contribution to the field.
Conclusion
This paper presents a novel Iterative Thresholding algorithm for non-linear learning in the presence of outliers. The algorithm is designed to be robust to data corruption and can effectively capture complex, non-linear relationships in the data.
The authors provide theoretical guarantees on the algorithm's performance and demonstrate its effectiveness on various experiments. This work represents an important advancement in the field of robust and flexible machine learning models, with potential applications in a wide range of real-world scenarios where data quality and reliability are critical.
Overall, this paper makes a valuable contribution to the ongoing efforts to develop more robust and adaptable machine learning techniques that can handle the challenges of noisy, complex, and potentially adversarial data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Iterative thresholding for non-linear learning in the strong $varepsilon$-contamination model
Arvind Rathnashyam, Alex Gittens
We derive approximation bounds for learning single neuron models using thresholded gradient descent when both the labels and the covariates are possibly corrupted adversarially. We assume the data follows the model $y = sigma(mathbf{w}^{*} cdot mathbf{x}) + xi,$ where $sigma$ is a nonlinear activation function, the noise $xi$ is Gaussian, and the covariate vector $mathbf{x}$ is sampled from a sub-Gaussian distribution. We study sigmoidal, leaky-ReLU, and ReLU activation functions and derive a $O(nusqrt{epsilonlog(1/epsilon)})$ approximation bound in $ell_{2}$-norm, with sample complexity $O(d/epsilon)$ and failure probability $e^{-Omega(d)}$. We also study the linear regression problem, where $sigma(mathbf{x}) = mathbf{x}$. We derive a $O(nuepsilonlog(1/epsilon))$ approximation bound, improving upon the previous $O(nu)$ approximation bounds for the gradient-descent based iterative thresholding algorithms of Bhatia et al. (NeurIPS 2015) and Shen and Sanghavi (ICML 2019). Our algorithm has a $O(textrm{polylog}(N,d)log(R/epsilon))$ runtime complexity when $|mathbf{w}^{*}|_2 leq R$, improving upon the $O(text{polylog}(N,d)/epsilon^2)$ runtime complexity of Awasthi et al. (NeurIPS 2022).
Read more9/6/2024
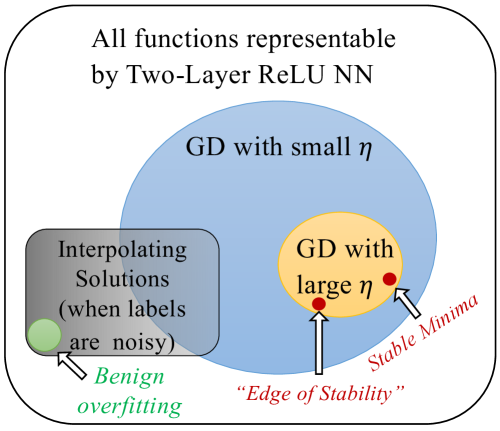
0
Stable Minima Cannot Overfit in Univariate ReLU Networks: Generalization by Large Step Sizes
Dan Qiao, Kaiqi Zhang, Esha Singh, Daniel Soudry, Yu-Xiang Wang
We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can emph{stably} converge to. We show that gradient descent with a fixed learning rate $eta$ can only find local minima that represent smooth functions with a certain weighted emph{first order total variation} bounded by $1/eta - 1/2 + widetilde{O}(sigma + sqrt{mathrm{MSE}})$ where $sigma$ is the label noise level, $mathrm{MSE}$ is short for mean squared error against the ground truth, and $widetilde{O}(cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without regularization can achieve near-optimal rates in nonparametric regression.
Read more6/12/2024
➖
0
High-probability Convergence Bounds for Nonlinear Stochastic Gradient Descent Under Heavy-tailed Noise
Aleksandar Armacki, Pranay Sharma, Gauri Joshi, Dragana Bajovic, Dusan Jakovetic, Soummya Kar
We study high-probability convergence guarantees of learning on streaming data in the presence of heavy-tailed noise. In the proposed scenario, the model is updated in an online fashion, as new information is observed, without storing any additional data. To combat the heavy-tailed noise, we consider a general framework of nonlinear stochastic gradient descent (SGD), providing several strong results. First, for non-convex costs and component-wise nonlinearities, we establish a convergence rate arbitrarily close to $mathcal{O}left(t^{-frac{1}{4}}right)$, whose exponent is independent of noise and problem parameters. Second, for strongly convex costs and a broader class of nonlinearities, we establish convergence of the last iterate to the optimum, with a rate $mathcal{O}left(t^{-zeta} right)$, where $zeta in (0,1)$ depends on problem parameters, noise and nonlinearity. As we show analytically and numerically, $zeta$ can be used to inform the preferred choice of nonlinearity for given problem settings. Compared to state-of-the-art, who only consider clipping, require bounded noise moments of order $eta in (1,2]$, and establish convergence rates whose exponents go to zero as $eta rightarrow 1$, we provide high-probability guarantees for a much broader class of nonlinearities and symmetric density noise, with convergence rates whose exponents are bounded away from zero, even when the noise has finite first moment only. Moreover, in the case of strongly convex functions, we demonstrate analytically and numerically that clipping is not always the optimal nonlinearity, further underlining the value of our general framework.
Read more4/22/2024
🔍
0
Langevin dynamics based algorithm e-TH$varepsilon$O POULA for stochastic optimization problems with discontinuous stochastic gradient
Dong-Young Lim, Ariel Neufeld, Sotirios Sabanis, Ying Zhang
We introduce a new Langevin dynamics based algorithm, called e-TH$varepsilon$O POULA, to solve optimization problems with discontinuous stochastic gradients which naturally appear in real-world applications such as quantile estimation, vector quantization, CVaR minimization, and regularized optimization problems involving ReLU neural networks. We demonstrate both theoretically and numerically the applicability of the e-TH$varepsilon$O POULA algorithm. More precisely, under the conditions that the stochastic gradient is locally Lipschitz in average and satisfies a certain convexity at infinity condition, we establish non-asymptotic error bounds for e-TH$varepsilon$O POULA in Wasserstein distances and provide a non-asymptotic estimate for the expected excess risk, which can be controlled to be arbitrarily small. Three key applications in finance and insurance are provided, namely, multi-period portfolio optimization, transfer learning in multi-period portfolio optimization, and insurance claim prediction, which involve neural networks with (Leaky)-ReLU activation functions. Numerical experiments conducted using real-world datasets illustrate the superior empirical performance of e-TH$varepsilon$O POULA compared to SGLD, TUSLA, ADAM, and AMSGrad in terms of model accuracy.
Read more7/2/2024