JMI at SemEval 2024 Task 3: Two-step approach for multimodal ECAC using in-context learning with GPT and instruction-tuned Llama models

0

Sign in to get full access
Overview
- This paper presents a two-step approach for multimodal Emotion Cause Anticipation and Classification (ECAC) using large language models.
- The approach combines in-context learning with GPT models and instruction-tuned LLaMA models to tackle the ECAC task.
- Experiments are conducted on the SemEval 2024 Task 3 dataset.
Plain English Explanation
Emotion recognition and understanding is an important task in artificial intelligence, with applications in areas like customer service, mental health support, and content moderation. The ECAC task aims to not only identify the emotion in a given text, but also the cause or reason behind that emotion.
The researchers in this paper propose a two-step approach to tackle the ECAC challenge. First, they use large language models like GPT in an "in-context learning" setup. This allows the model to quickly adapt to the task by providing it with example inputs and outputs during inference.
Then, they fine-tune an instruction-tuned version of the LLaMA language model. Instruction-tuning means the model has been trained to follow natural language instructions, allowing it to understand and execute complex tasks more effectively.
By combining these two techniques - in-context learning and instruction-tuning - the researchers aim to create a powerful system that can accurately identify emotions and their causes in multimodal (text and image) inputs. This could have valuable applications in areas where understanding human emotions is crucial.
Technical Explanation
The paper proposes a two-step approach for the ECAC task:
-
In-Context Learning with GPT Models:
- The researchers leverage large language models like GPT-3 in an in-context learning setup.
- In-context learning allows the model to quickly adapt to the task by providing it with example inputs and outputs during inference.
- This step aims to leverage the strong text understanding capabilities of GPT models.
-
Instruction-Tuned LLaMA Models:
- The researchers fine-tune the LLaMA language model using instruction-tuning.
- Instruction-tuning trains the model to follow natural language instructions, improving its ability to understand and execute complex tasks.
- This step aims to combine the multimodal understanding of the LLaMA model with its instruction-following capabilities.
The experiments are conducted on the SemEval 2024 Task 3 dataset, which contains multimodal inputs (text and images) and requires predicting the emotion and its cause.
Critical Analysis
The proposed two-step approach is a novel and interesting attempt to tackle the challenging ECAC task. By leveraging the strengths of different language models through in-context learning and instruction-tuning, the researchers aim to create a robust and versatile system.
However, the paper does not provide much detail on the specific implementation and hyperparameters used for the GPT and LLaMA models. Additionally, the evaluation metrics and comparison to other state-of-the-art approaches are not discussed in depth.
It would be helpful to understand the performance improvements gained by the two-step approach compared to using a single model or other multimodal techniques. The authors could also discuss potential limitations, such as the computational cost or scalability of the proposed method.
Further research could explore alternative ways of combining different language models or incorporating additional modalities (e.g., audio, video) to enhance the ECAC task. Investigating the interpretability and explainability of the system's predictions could also be a valuable direction.
Conclusion
This paper presents a two-step approach for multimodal ECAC using large language models. By leveraging in-context learning with GPT and instruction-tuned LLaMA models, the researchers aim to create a powerful system that can accurately identify emotions and their causes in text and image inputs.
The proposed method has the potential to advance the state-of-the-art in emotion recognition and understanding, with applications in various domains where understanding human emotions is crucial. While the technical details and evaluation could be further explored, the paper offers an interesting and innovative approach to the ECAC challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
JMI at SemEval 2024 Task 3: Two-step approach for multimodal ECAC using in-context learning with GPT and instruction-tuned Llama models
Arefa, Mohammed Abbas Ansari, Chandni Saxena, Tanvir Ahmad
This paper presents our system development for SemEval-2024 Task 3: The Competition of Multimodal Emotion Cause Analysis in Conversations. Effectively capturing emotions in human conversations requires integrating multiple modalities such as text, audio, and video. However, the complexities of these diverse modalities pose challenges for developing an efficient multimodal emotion cause analysis (ECA) system. Our proposed approach addresses these challenges by a two-step framework. We adopt two different approaches in our implementation. In Approach 1, we employ instruction-tuning with two separate Llama 2 models for emotion and cause prediction. In Approach 2, we use GPT-4V for conversation-level video description and employ in-context learning with annotated conversation using GPT 3.5. Our system wins rank 4, and system ablation experiments demonstrate that our proposed solutions achieve significant performance gains. All the experimental codes are available on Github.
Read more4/3/2024

0
MIPS at SemEval-2024 Task 3: Multimodal Emotion-Cause Pair Extraction in Conversations with Multimodal Language Models
Zebang Cheng, Fuqiang Niu, Yuxiang Lin, Zhi-Qi Cheng, Bowen Zhang, Xiaojiang Peng
This paper presents our winning submission to Subtask 2 of SemEval 2024 Task 3 on multimodal emotion cause analysis in conversations. We propose a novel Multimodal Emotion Recognition and Multimodal Emotion Cause Extraction (MER-MCE) framework that integrates text, audio, and visual modalities using specialized emotion encoders. Our approach sets itself apart from top-performing teams by leveraging modality-specific features for enhanced emotion understanding and causality inference. Experimental evaluation demonstrates the advantages of our multimodal approach, with our submission achieving a competitive weighted F1 score of 0.3435, ranking third with a margin of only 0.0339 behind the 1st team and 0.0025 behind the 2nd team. Project: https://github.com/MIPS-COLT/MER-MCE.git
Read more4/12/2024
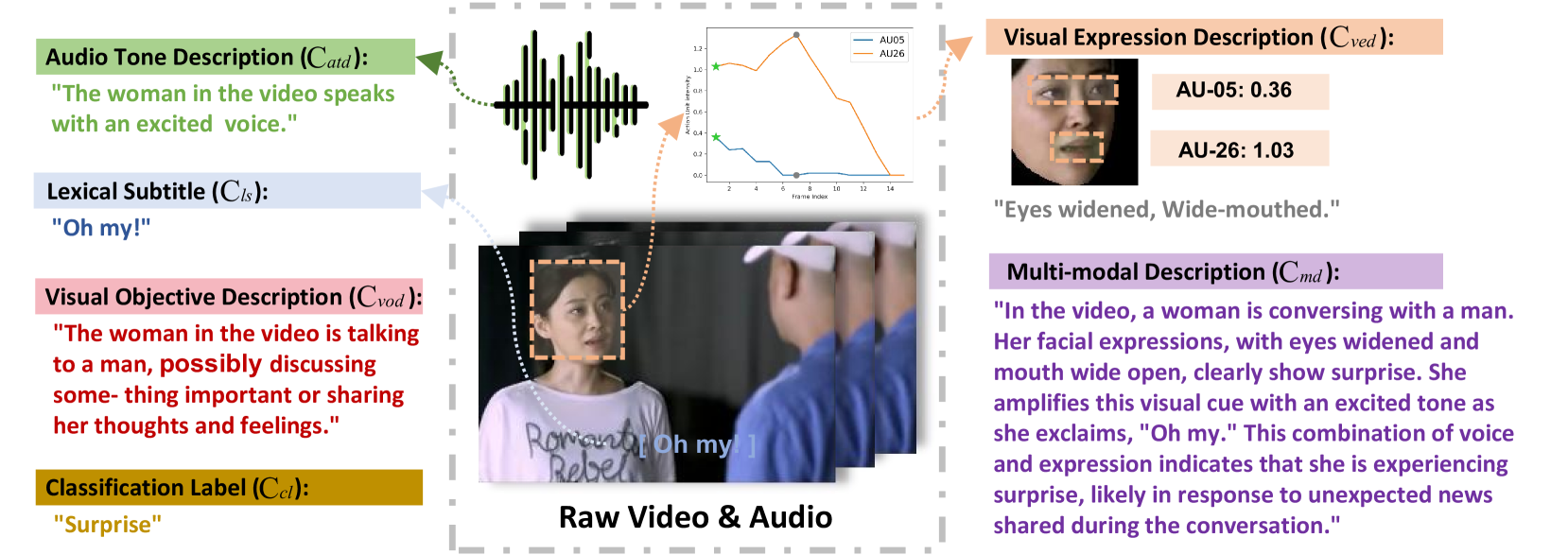
0
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
Read more6/18/2024

0
Samsung Research China-Beijing at SemEval-2024 Task 3: A multi-stage framework for Emotion-Cause Pair Extraction in Conversations
Shen Zhang, Haojie Zhang, Jing Zhang, Xudong Zhang, Yimeng Zhuang, Jinting Wu
In human-computer interaction, it is crucial for agents to respond to human by understanding their emotions. Unraveling the causes of emotions is more challenging. A new task named Multimodal Emotion-Cause Pair Extraction in Conversations is responsible for recognizing emotion and identifying causal expressions. In this study, we propose a multi-stage framework to generate emotion and extract the emotion causal pairs given the target emotion. In the first stage, Llama-2-based InstructERC is utilized to extract the emotion category of each utterance in a conversation. After emotion recognition, a two-stream attention model is employed to extract the emotion causal pairs given the target emotion for subtask 2 while MuTEC is employed to extract causal span for subtask 1. Our approach achieved first place for both of the two subtasks in the competition.
Read more4/29/2024