Joint semi-supervised and contrastive learning enables zero-shot domain-adaptation and multi-domain segmentation
2405.05336
0
0
Abstract
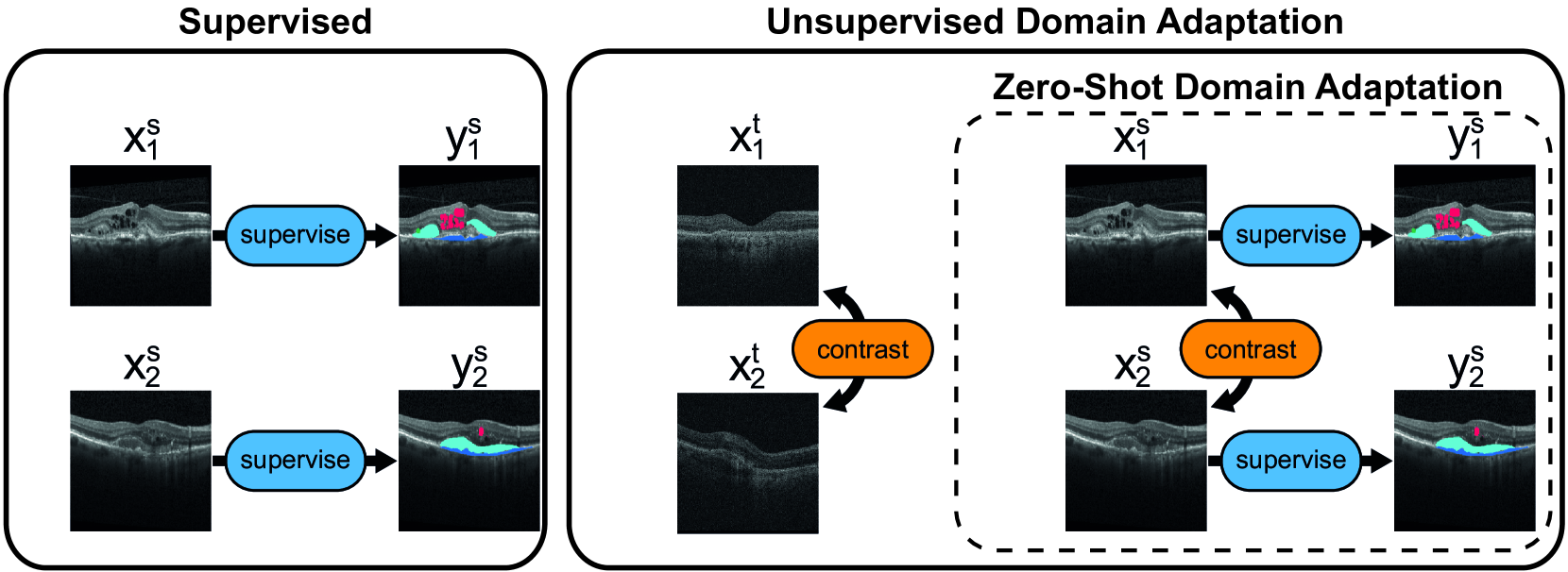
Despite their effectiveness, current deep learning models face challenges with images coming from different domains with varying appearance and content. We introduce SegCLR, a versatile framework designed to segment volumetric images across different domains, employing supervised and contrastive learning simultaneously to effectively learn from both labeled and unlabeled data. We demonstrate the superior performance of SegCLR through a comprehensive evaluation involving three diverse clinical datasets of retinal fluid segmentation in 3D Optical Coherence Tomography (OCT), various network configurations, and verification across 10 different network initializations. In an unsupervised domain adaptation context, SegCLR achieves results on par with a supervised upper-bound model trained on the intended target domain. Notably, we discover that the segmentation performance of SegCLR framework is marginally impacted by the abundance of unlabeled data from the target domain, thereby we also propose an effective zero-shot domain adaptation extension of SegCLR, eliminating the need for any target domain information. This shows that our proposed addition of contrastive loss in standard supervised training for segmentation leads to superior models, inherently more generalizable to both in- and out-of-domain test data. We additionally propose a pragmatic solution for SegCLR deployment in realistic scenarios with multiple domains containing labeled data. Accordingly, our framework pushes the boundaries of deep-learning based segmentation in multi-domain applications, regardless of data availability - labeled, unlabeled, or nonexistent.
Create account to get full access
Overview
This paper presents a novel approach to enable zero-shot domain adaptation and multi-domain segmentation using joint semi-supervised and contrastive learning. The key ideas are:
- Leveraging both labeled and unlabeled data through semi-supervised learning
- Enforcing consistency across domains through contrastive learning
- Enabling zero-shot adaptation to unseen domains without any labeled data
- Supporting multi-domain segmentation with a single model
Plain English Explanation
The researchers developed a machine learning system that can learn to segment images from multiple different domains, even if it hasn't been explicitly trained on some of those domains before. This is an important capability, as real-world applications often involve data from diverse sources that may not be available during model training.
The system uses a combination of semi-supervised learning and contrastive learning to achieve this. Semi-supervised learning means the model can learn from both labeled data (where the correct segmentation is provided) and unlabeled data (where the model has to figure out the segmentation on its own). Contrastive learning encourages the model to find representations that are consistent across different domains, even if the actual image content varies.
By training the model this way, the researchers were able to show that it could be applied to completely new domains without any additional labeled data - a "zero-shot" adaptation. The model was also able to segment images from multiple domains simultaneously, rather than requiring separate models for each domain.
This work demonstrates how advanced machine learning techniques can enable more flexible and robust computer vision systems that can handle real-world complexity. The ability to adapt to new data sources and handle multiple tasks with a single model has significant practical implications.
Technical Explanation
The paper proposes a novel framework for joint semi-supervised and contrastive learning to enable zero-shot domain adaptation and multi-domain semantic segmentation. The key components are:
-
Semi-supervised Learning: The model is trained on both labeled data, where the ground truth segmentation maps are provided, and unlabeled data, where the model must learn to predict the segmentation without supervision. This allows the model to leverage all available data, including unlabeled samples from the target domain.
-
Contrastive Learning: The model is trained to learn representations that are consistent across different domains, even if the image content varies significantly. This is achieved through a contrastive loss function that encourages the model to map similar pixels/regions from different domains to nearby points in the representation space, while pushing apart dissimilar ones.
-
Zero-shot Domain Adaptation: By learning domain-agnostic representations through the semi-supervised and contrastive training, the model can be directly applied to new domains without any labeled data from those domains. This "zero-shot" adaptation capability is demonstrated experimentally.
-
Multi-domain Segmentation: The trained model is able to perform semantic segmentation on images from multiple different domains simultaneously, without requiring separate models for each domain. This is enabled by the shared, domain-invariant representation learned by the framework.
The proposed method is evaluated on several public medical imaging datasets, showing significant improvements over prior work in both zero-shot domain adaptation and multi-domain segmentation tasks. The results highlight the effectiveness of jointly leveraging semi-supervised and contrastive learning for building versatile and generalizable computer vision systems.
Critical Analysis
The paper presents a compelling approach to address important challenges in domain adaptation and multi-domain segmentation. The key strengths are the joint use of semi-supervised and contrastive learning, which allows the model to learn powerful representations that generalize well to new domains.
However, the paper does not discuss some potential limitations. For example, the performance of the zero-shot adaptation likely depends on the similarity between the source and target domains. It's unclear how well the method would perform if the domains are very different (e.g., adapting from natural images to medical scans). Additionally, the training process may be computationally intensive, especially for larger model sizes and dataset scales.
Further research could explore ways to make the zero-shot adaptation more robust to larger domain shifts, as well as techniques to improve the efficiency of the training process. Investigating the interpretability of the learned representations could also lead to additional insights.
Overall, this work represents an important advance in domain-adaptive and multi-task computer vision, with promising applications in real-world scenarios where data sources are diverse and dynamic. The ability to leverage both labeled and unlabeled data, while maintaining consistent performance across domains, is a significant step forward.
Conclusion
This paper presents a novel framework that combines semi-supervised and contrastive learning to enable zero-shot domain adaptation and multi-domain semantic segmentation. By leveraging both labeled and unlabeled data, and enforcing consistency across domains, the model is able to learn powerful representations that generalize well to new, unseen domains.
The key contributions of this work are the demonstration of zero-shot adaptation capabilities, as well as the ability to perform multi-domain segmentation with a single model. These advances have important practical implications, as they enable more flexible and robust computer vision systems that can handle the diversity and dynamism of real-world data.
While the paper highlights the strengths of the proposed approach, further research is needed to address potential limitations, such as the dependence on domain similarity and the computational efficiency of the training process. Nonetheless, this work represents a significant step forward in the field of domain-adaptive and multi-task machine learning, with the potential to drive important breakthroughs in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
0
0
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
5/31/2024

Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Zihao Wang, Yingyu Yang, Yuzhou Chen, Tingting Yuan, Maxime Sermesant, Herve Delingette, Ona Wu
0
0
Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
4/11/2024

Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Jiaqi Yue, Jiancheng Zhao, Chunhui Zhao
0
0
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
5/24/2024
💬
HC$^2$L: Hybrid and Cooperative Contrastive Learning for Cross-lingual Spoken Language Understanding
Bowen Xing, Ivor W. Tsang
0
0
State-of-the-art model for zero-shot cross-lingual spoken language understanding performs cross-lingual unsupervised contrastive learning to achieve the label-agnostic semantic alignment between each utterance and its code-switched data. However, it ignores the precious intent/slot labels, whose label information is promising to help capture the label-aware semantics structure and then leverage supervised contrastive learning to improve both source and target languages' semantics. In this paper, we propose Hybrid and Cooperative Contrastive Learning to address this problem. Apart from cross-lingual unsupervised contrastive learning, we design a holistic approach that exploits source language supervised contrastive learning, cross-lingual supervised contrastive learning and multilingual supervised contrastive learning to perform label-aware semantics alignments in a comprehensive manner. Each kind of supervised contrastive learning mechanism includes both single-task and joint-task scenarios. In our model, one contrastive learning mechanism's input is enhanced by others. Thus the total four contrastive learning mechanisms are cooperative to learn more consistent and discriminative representations in the virtuous cycle during the training process. Experiments show that our model obtains consistent improvements over 9 languages, achieving new state-of-the-art performance.
5/13/2024