Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
2404.01102
0
0

Abstract
Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a diffusion-based approach for zero-shot medical image-to-image translation, enabling cross-modality segmentation without the need for paired training data.
- The model can translate between different medical imaging modalities, such as MRI and CT scans, and use the translated images for segmentation tasks.
- This is a significant advancement as it removes the requirement for expensive and time-consuming data collection and annotation, which has been a major bottleneck in medical image analysis.
Plain English Explanation
The paper introduces a new method for translating medical images from one type, like an MRI scan, to another type, like a CT scan, without any paired training data. This is called "zero-shot" translation, meaning the model can do this task without being explicitly trained on matched image pairs.
The key innovation is using a diffusion model, which is a type of machine learning model that works by gradually adding noise to an image and then learning how to reverse that process to generate new images. By training the diffusion model on unpaired images from different modalities, it can learn to translate between them.
This is an important advancement because collecting large datasets of matched medical images, where the same patient has been scanned using multiple imaging techniques, is extremely challenging and costly. The zero-shot translation approach sidesteps this requirement, potentially making medical image analysis more accessible and scalable.
Once the model can translate between modalities, it can then use the translated images for downstream tasks like segmentation, where the goal is to identify and outline specific anatomical structures or lesions in the image. This cross-modality segmentation is valuable because different imaging techniques may be better suited for visualizing different medical conditions.
Technical Explanation
The paper proposes a diffusion-based zero-shot medical image-to-image translation model for enabling cross-modality segmentation. The model learns to translate between different medical imaging modalities, such as MRI and CT scans, without requiring paired training data.
The core of the approach is a diffusion model that is trained on unpaired images from the source and target modalities. The diffusion model learns to gradually add noise to the input image and then reverse that process to generate a translated image in the target modality. This allows the model to learn the underlying mapping between the modalities without needing explicit paired examples.
The translated images can then be used for cross-modal segmentation, where the goal is to outline specific anatomical structures or lesions. The paper demonstrates how this zero-shot cross-modality segmentation approach can achieve performance comparable to supervised methods that require paired training data.
Critical Analysis
The paper presents a compelling approach to the challenging problem of cross-modality medical image analysis. By leveraging diffusion models for zero-shot translation, the method effectively sidesteps the need for expensive and time-consuming data collection and annotation.
However, the paper does acknowledge some limitations. The translation quality may be affected by domain shift, where the source and target modalities have significant differences in their underlying distributions. Additionally, the segmentation performance is still lower than that of supervised methods, even if the zero-shot approach is a significant advancement.
Further research could explore ways to improve the cross-modal conditioning and reconstruction to better handle domain shift, as well as investigate the potential of using language-guided medical image segmentation to further enhance the zero-shot capabilities.
Conclusion
This paper presents a novel diffusion-based approach for zero-shot medical image-to-image translation, enabling cross-modality segmentation without the need for paired training data. This is a significant advancement, as it removes a major bottleneck in medical image analysis and could potentially make these powerful techniques more accessible to a wider range of healthcare providers and researchers.
The ability to translate between modalities and leverage the strengths of different imaging techniques for segmentation tasks has valuable applications in areas like disease diagnosis, treatment planning, and monitoring. While the method still has room for improvement, this work represents an important step forward in the field of medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
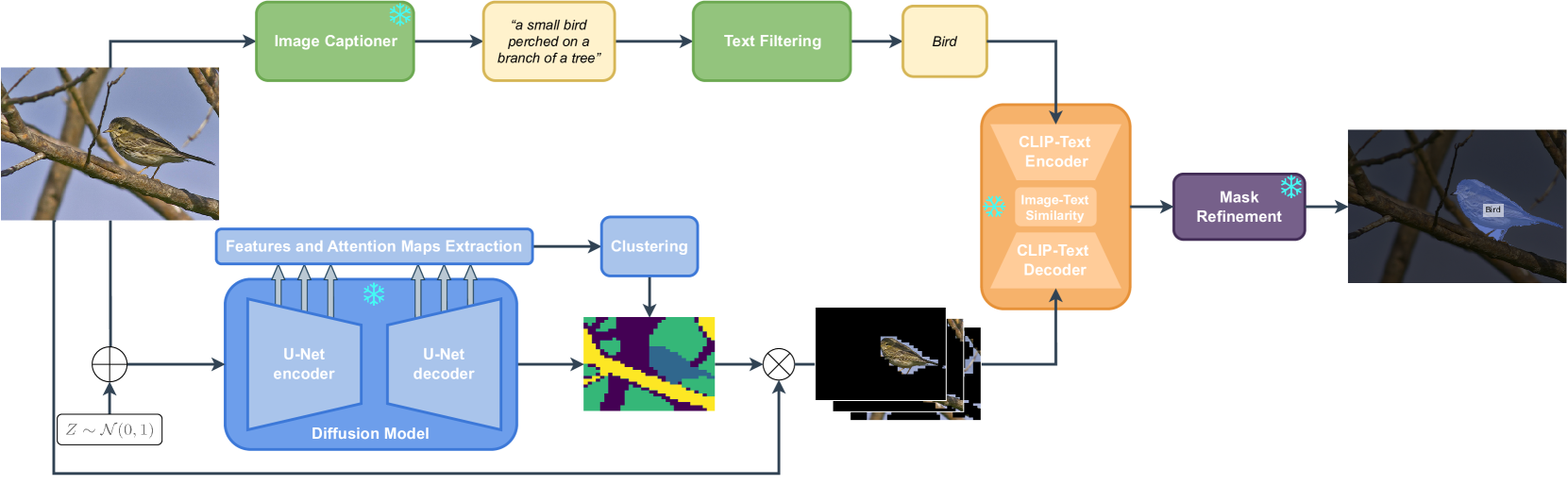
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024
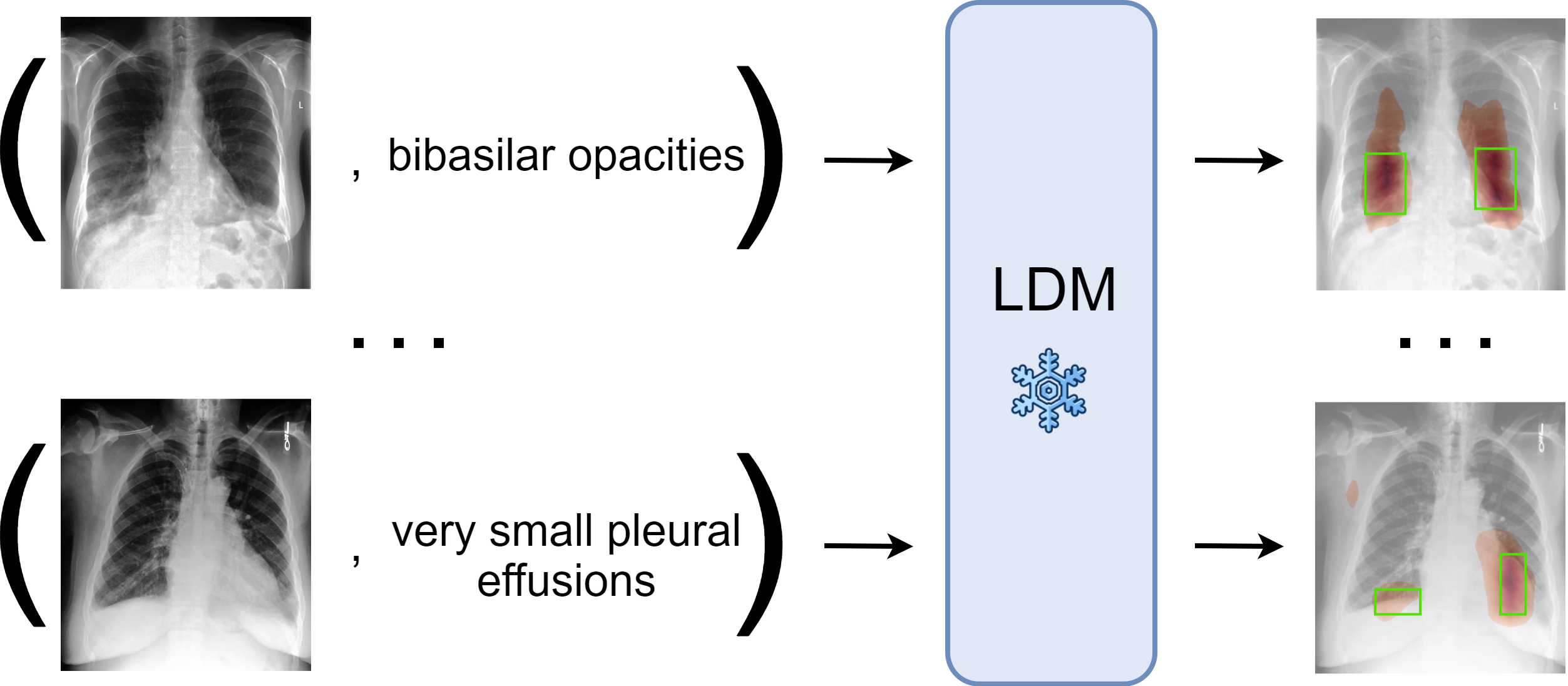
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
0
0
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
4/22/2024
🤷
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, Mar Gonzalez-Franco
0
0
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU. The project page is at url{https://sites.google.com/view/diffseg/home}.
4/3/2024
🏋️
Cross-modal tumor segmentation using generative blending augmentation and self training
Guillaume Sall'e, Pierre-Henri Conze, Julien Bert, Nicolas Boussion, Dimitris Visvikis, Vincent Jaouen
0
0
textit{Objectives}: Data scarcity and domain shifts lead to biased training sets that do not accurately represent deployment conditions. A related practical problem is cross-modal image segmentation, where the objective is to segment unlabelled images using previously labelled datasets from other imaging modalities. textit{Methods}: We propose a cross-modal segmentation method based on conventional image synthesis boosted by a new data augmentation technique called Generative Blending Augmentation (GBA). GBA leverages a SinGAN model to learn representative generative features from a single training image to diversify realistically tumor appearances. This way, we compensate for image synthesis errors, subsequently improving the generalization power of a downstream segmentation model. The proposed augmentation is further combined to an iterative self-training procedure leveraging pseudo labels at each pass. textit{Results}: The proposed solution ranked first for vestibular schwannoma (VS) segmentation during the validation and test phases of the MICCAI CrossMoDA 2022 challenge, with best mean Dice similarity and average symmetric surface distance measures. textit{Conclusion and significance}: Local contrast alteration of tumor appearances and iterative self-training with pseudo labels are likely to lead to performance improvements in a variety of segmentation contexts.
4/1/2024