The JPEG Pleno Learning-based Point Cloud Coding Standard: Serving Man and Machine

0
✅
Sign in to get full access
Overview
- Efficient point cloud coding is crucial for applications like virtual reality, autonomous driving, and digital twin systems.
- Deep learning offers advanced techniques to compress point clouds more efficiently than traditional methods, while also enabling effective computer vision tasks in the compressed domain.
- JPEG has finalized the JPEG Pleno Learning-based Point Cloud Coding (PCC) standard, which leverages deep learning for both geometry and color coding.
Plain English Explanation
Efficient point cloud coding is essential for applications that rely on rich, interactive 3D data representations. Deep learning has emerged as a powerful tool in this domain, offering techniques to compress point clouds more efficiently than traditional methods. This allows for effective computer vision tasks to be performed directly on the compressed data, benefiting both human visualization and machine processing.
Recognizing this potential, the JPEG organization has recently finalized the JPEG Pleno Learning-based Point Cloud Coding (PCC) standard. This standard leverages deep learning models to encode the geometry of point clouds directly in their original 3D form, while the color data is projected onto 2D images and encoded using the JPEG AI standard, which is also based on deep learning.
The main advantage of this approach is that it can achieve significant compression rates, especially for the geometry of point clouds, while still maintaining the ability to perform computer vision tasks on the compressed data. This is a significant improvement over traditional coding methods, which typically struggle to balance compression performance and the ability to process the data effectively.
Technical Explanation
The JPEG Pleno Learning-based Point Cloud Coding (PCC) standard leverages deep learning to achieve efficient coding of both the geometry and color information in static point clouds.
For the geometry, the standard uses sparse convolutional neural networks to process the data directly in its original 3D form. This allows for more effective compression compared to traditional methods that rely on converting the 3D data to 2D representations.
The color information is handled by projecting the data onto 2D images and then encoding it using the JPEG AI standard, which is also a learning-based approach. This combination of 3D geometry coding and 2D color coding powered by deep learning is what makes the JPEG PCC standard unique and powerful.
The paper provides a comprehensive technical description of the JPEG PCC standard and a thorough benchmarking of its performance against the state-of-the-art. The results show that the JPEG PCC standard outperforms the conventional MPEG PCC standards, especially in geometry coding, achieving significant rate reductions. While the color compression performance is less competitive, the power of the full learning-based coding framework for both geometry and color, as well as the associated effective compressed domain processing, helps to overcome this limitation.
Critical Analysis
The paper provides a detailed technical explanation of the JPEG Pleno Learning-based Point Cloud Coding (PCC) standard, highlighting its strengths and potential weaknesses.
One of the key strengths of the JPEG PCC standard is its ability to achieve significant compression rates, particularly for the geometry of point clouds, while still maintaining the ability to perform computer vision tasks on the compressed data. This is a significant improvement over traditional coding methods, which often struggle to balance these two important factors.
However, the paper also acknowledges that the color compression performance of the JPEG PCC standard is less competitive compared to the geometry coding. This limitation is mitigated by the power of the full learning-based coding framework and the associated effective compressed domain processing, but it is still an area that could benefit from further research and optimization.
Additionally, the paper does not delve into the potential computational and memory requirements of the deep learning models used in the JPEG PCC standard. As with any deep learning-based approach, there may be trade-offs between compression performance and the hardware resources required to encode and decode the point cloud data, which could be an important consideration for certain applications.
Overall, the JPEG PCC standard represents a significant step forward in the field of efficient point cloud coding, leveraging the power of deep learning to achieve impressive results. However, as with any new technology, there may be areas for further research and improvement, particularly in addressing the color compression performance and the computational considerations.
Conclusion
The JPEG Pleno Learning-based Point Cloud Coding (PCC) standard is a notable advancement in the field of efficient point cloud coding, addressing the growing demand for rich and interactive 3D data representations in applications such as virtual reality, autonomous driving, and digital twin systems.
By leveraging deep learning techniques, the JPEG PCC standard is able to achieve significant compression rates, particularly for the geometry of point clouds, while also maintaining the ability to perform effective computer vision tasks directly on the compressed data. This represents a significant improvement over traditional coding methods, which often struggle to balance these two important factors.
While the color compression performance of the JPEG PCC standard is less competitive, the power of the full learning-based coding framework and the associated effective compressed domain processing helps to mitigate this limitation. As the field of deep learning continues to evolve, there may be opportunities for further optimization and improvement in this area.
Overall, the JPEG PCC standard is a promising step forward in the quest for efficient and versatile point cloud coding, with the potential to have a substantial impact on a wide range of applications that rely on rich, interactive 3D data representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
The JPEG Pleno Learning-based Point Cloud Coding Standard: Serving Man and Machine
Andr'e F. R. Guarda (Instituto de Telecomunicac{c}~oes, Lisbon, Portugal), Nuno M. M. Rodrigues (Instituto de Telecomunicac{c}~oes, Lisbon, Portugal, ESTG, Polit'ecnico de Leiria, Leiria, Portugal), Fernando Pereira (Instituto de Telecomunicac{c}~oes, Lisbon, Portugal, Instituto Superior T'ecnico - Universidade de Lisboa, Lisbon, Portugal)
Efficient point cloud coding has become increasingly critical for multiple applications such as virtual reality, autonomous driving, and digital twin systems, where rich and interactive 3D data representations may functionally make the difference. Deep learning has emerged as a powerful tool in this domain, offering advanced techniques for compressing point clouds more efficiently than conventional coding methods while also allowing effective computer vision tasks performed in the compressed domain thus, for the first time, making available a common compressed visual representation effective for both man and machine. Taking advantage of this potential, JPEG has recently finalized the JPEG Pleno Learning-based Point Cloud Coding (PCC) standard offering efficient lossy coding of static point clouds, targeting both human visualization and machine processing by leveraging deep learning models for geometry and color coding. The geometry is processed directly in its original 3D form using sparse convolutional neural networks, while the color data is projected onto 2D images and encoded using the also learning-based JPEG AI standard. The goal of this paper is to provide a complete technical description of the JPEG PCC standard, along with a thorough benchmarking of its performance against the state-of-the-art, while highlighting its main strengths and weaknesses. In terms of compression performance, JPEG PCC outperforms the conventional MPEG PCC standards, especially in geometry coding, achieving significant rate reductions. Color compression performance is less competitive but this is overcome by the power of a full learning-based coding framework for both geometry and color and the associated effective compressed domain processing.
Read more9/14/2024

0
New!Learned Compression for Images and Point Clouds
Mateen Ulhaq
Over the last decade, deep learning has shown great success at performing computer vision tasks, including classification, super-resolution, and style transfer. Now, we apply it to data compression to help build the next generation of multimedia codecs. This thesis provides three primary contributions to this new field of learned compression. First, we present an efficient low-complexity entropy model that dynamically adapts the encoding distribution to a specific input by compressing and transmitting the encoding distribution itself as side information. Secondly, we propose a novel lightweight low-complexity point cloud codec that is highly specialized for classification, attaining significant reductions in bitrate compared to non-specialized codecs. Lastly, we explore how motion within the input domain between consecutive video frames is manifested in the corresponding convolutionally-derived latent space.
Read more9/16/2024
✅
0
Inter-Frame Compression for Dynamic Point Cloud Geometry Coding
Anique Akhtar, Zhu Li, Geert Van der Auwera
Efficient point cloud compression is essential for applications like virtual and mixed reality, autonomous driving, and cultural heritage. This paper proposes a deep learning-based inter-frame encoding scheme for dynamic point cloud geometry compression. We propose a lossy geometry compression scheme that predicts the latent representation of the current frame using the previous frame by employing a novel feature space inter-prediction network. The proposed network utilizes sparse convolutions with hierarchical multiscale 3D feature learning to encode the current frame using the previous frame. The proposed method introduces a novel predictor network for motion compensation in the feature domain to map the latent representation of the previous frame to the coordinates of the current frame to predict the current frame's feature embedding. The framework transmits the residual of the predicted features and the actual features by compressing them using a learned probabilistic factorized entropy model. At the receiver, the decoder hierarchically reconstructs the current frame by progressively rescaling the feature embedding. The proposed framework is compared to the state-of-the-art Video-based Point Cloud Compression (V-PCC) and Geometry-based Point Cloud Compression (G-PCC) schemes standardized by the Moving Picture Experts Group (MPEG). The proposed method achieves more than 88% BD-Rate (Bjontegaard Delta Rate) reduction against G-PCCv20 Octree, more than 56% BD-Rate savings against G-PCCv20 Trisoup, more than 62% BD-Rate reduction against V-PCC intra-frame encoding mode, and more than 52% BD-Rate savings against V-PCC P-frame-based inter-frame encoding mode using HEVC. These significant performance gains are cross-checked and verified in the MPEG working group.
Read more9/4/2024
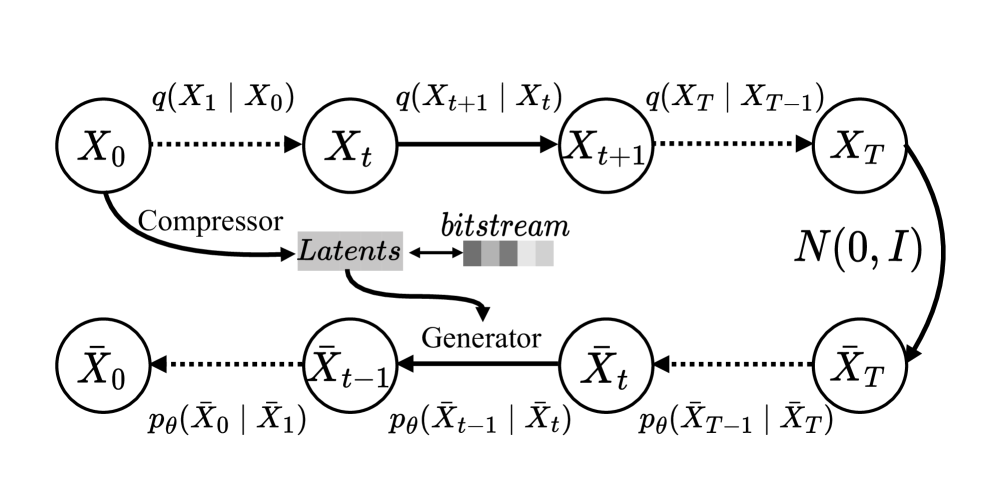
0
Diff-PCC: Diffusion-based Neural Compression for 3D Point Clouds
Kai Liu, Kang You, Pan Gao
Stable diffusion networks have emerged as a groundbreaking development for their ability to produce realistic and detailed visual content. This characteristic renders them ideal decoders, capable of producing high-quality and aesthetically pleasing reconstructions. In this paper, we introduce the first diffusion-based point cloud compression method, dubbed Diff-PCC, to leverage the expressive power of the diffusion model for generative and aesthetically superior decoding. Different from the conventional autoencoder fashion, a dual-space latent representation is devised in this paper, in which a compressor composed of two independent encoding backbones is considered to extract expressive shape latents from distinct latent spaces. At the decoding side, a diffusion-based generator is devised to produce high-quality reconstructions by considering the shape latents as guidance to stochastically denoise the noisy point clouds. Experiments demonstrate that the proposed Diff-PCC achieves state-of-the-art compression performance (e.g., 7.711 dB BD-PSNR gains against the latest G-PCC standard at ultra-low bitrate) while attaining superior subjective quality. Source code will be made publicly available.
Read more8/21/2024