KAN v.s. MLP for Offline Reinforcement Learning

0

Sign in to get full access
Overview
- The paper compares Kolmogorov-Arnold networks (KANs) and multi-layer perceptrons (MLPs) for offline reinforcement learning.
- Offline reinforcement learning aims to learn a policy from historical data without interacting with the environment.
- KANs are a type of neural network architecture inspired by the Kolmogorov-Arnold representation theorem.
- The paper evaluates the performance of KANs and MLPs on several offline reinforcement learning benchmarks.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent interacts with an environment and learns how to maximize rewards. In offline reinforcement learning, the agent learns from historical data without actively interacting with the environment.
The paper compares two types of neural network architectures for offline reinforcement learning: Kolmogorov-Arnold networks (KANs) and multi-layer perceptrons (MLPs). KANs are a special type of neural network inspired by a mathematical theorem that states any continuous function can be represented by a composition of simpler functions.
The researchers evaluate the performance of KANs and MLPs on several benchmark offline reinforcement learning tasks. They aim to understand the relative strengths and weaknesses of these two neural network architectures for this type of learning problem.
Technical Explanation
The paper investigates the use of Kolmogorov-Arnold networks (KANs) and multi-layer perceptrons (MLPs) for offline reinforcement learning. Offline reinforcement learning involves learning an optimal policy from historical data without interacting with the environment.
The authors first provide background on KANs, which are a type of neural network architecture inspired by the Kolmogorov-Arnold representation theorem. This theorem states that any continuous function can be represented as a composition of simpler functions. The authors hypothesize that this inductive bias of KANs may be advantageous for offline reinforcement learning compared to the more general MLP architecture.
The paper then describes the experimental setup, where the researchers evaluate KANs and MLPs on several offline reinforcement learning benchmark tasks. These tasks involve learning policies from offline datasets collected in various simulated environments.
The results show that KANs generally outperform MLPs on the evaluated offline reinforcement learning tasks. The authors attribute this superior performance to the inductive bias of KANs, which allows them to more effectively learn the underlying structure of the value function from limited offline data.
Critical Analysis
The paper provides a thorough comparison of Kolmogorov-Arnold networks (KANs) and multi-layer perceptrons (MLPs) for offline reinforcement learning. The researchers carefully designed their experiments to isolate the performance differences between these two neural network architectures.
One potential limitation of the study is the use of only simulated environments for the offline reinforcement learning benchmarks. It would be valuable to also evaluate the methods on real-world datasets to understand their practical applicability.
Additionally, the paper does not explore the reasons behind the performance differences in depth. While the authors attribute the superior performance of KANs to their inductive bias, a more detailed analysis of the learned representations and decision-making processes of the two architectures could provide additional insights.
Further research could also investigate the scalability of KANs to larger and more complex offline reinforcement learning problems, as well as explore potential hybrid approaches that combine the strengths of KANs and MLPs.
Conclusion
This paper presents a comparative study of Kolmogorov-Arnold networks (KANs) and multi-layer perceptrons (MLPs) for offline reinforcement learning. The results demonstrate the potential advantages of KANs, which leverage their inductive bias to more effectively learn value functions from limited offline data.
The findings have implications for the design of neural network architectures for offline reinforcement learning applications, where data efficiency is critical. Further research in this direction could lead to improved algorithms and methods for learning optimal policies from historical interaction data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!KAN v.s. MLP for Offline Reinforcement Learning
Haihong Guo, Fengxin Li, Jiao Li, Hongyan Liu
Kolmogorov-Arnold Networks (KAN) is an emerging neural network architecture in machine learning. It has greatly interested the research community about whether KAN can be a promising alternative of the commonly used Multi-Layer Perceptions (MLP). Experiments in various fields demonstrated that KAN-based machine learning can achieve comparable if not better performance than MLP-based methods, but with much smaller parameter scales and are more explainable. In this paper, we explore the incorporation of KAN into the actor and critic networks for offline reinforcement learning (RL). We evaluated the performance, parameter scales, and training efficiency of various KAN and MLP based conservative Q-learning (CQL) on the the classical D4RL benchmark for offline RL. Our study demonstrates that KAN can achieve performance close to the commonly used MLP with significantly fewer parameters. This provides us an option to choose the base networks according to the requirements of the offline RL tasks.
Read more9/17/2024

0
Kolmogorov-Arnold Network for Online Reinforcement Learning
Victor Augusto Kich, Jair Augusto Bottega, Raul Steinmetz, Ricardo Bedin Grando, Ayano Yorozu, Akihisa Ohya
Kolmogorov-Arnold Networks (KANs) have shown potential as an alternative to Multi-Layer Perceptrons (MLPs) in neural networks, providing universal function approximation with fewer parameters and reduced memory usage. In this paper, we explore the use of KANs as function approximators within the Proximal Policy Optimization (PPO) algorithm. We evaluate this approach by comparing its performance to the original MLP-based PPO using the DeepMind Control Proprio Robotics benchmark. Our results indicate that the KAN-based reinforcement learning algorithm can achieve comparable performance to its MLP-based counterpart, often with fewer parameters. These findings suggest that KANs may offer a more efficient option for reinforcement learning models.
Read more9/4/2024

0
Kolmogorov-Arnold Networks (KAN) for Time Series Classification and Robust Analysis
Chang Dong, Liangwei Zheng, Weitong Chen
Kolmogorov-Arnold Networks (KAN) has recently attracted significant attention as a promising alternative to traditional Multi-Layer Perceptrons (MLP). Despite their theoretical appeal, KAN require validation on large-scale benchmark datasets. Time series data, which has become increasingly prevalent in recent years, especially univariate time series are naturally suited for validating KAN. Therefore, we conducted a fair comparison among KAN, MLP, and mixed structures. The results indicate that KAN can achieve performance comparable to, or even slightly better than, MLP across 128 time series datasets. We also performed an ablation study on KAN, revealing that the output is primarily determined by the base component instead of b-spline function. Furthermore, we assessed the robustness of these models and found that KAN and the hybrid structure MLP_KAN exhibit significant robustness advantages, attributed to their lower Lipschitz constants. This suggests that KAN and KAN layers hold strong potential to be robust models or to improve the adversarial robustness of other models.
Read more9/12/2024
19
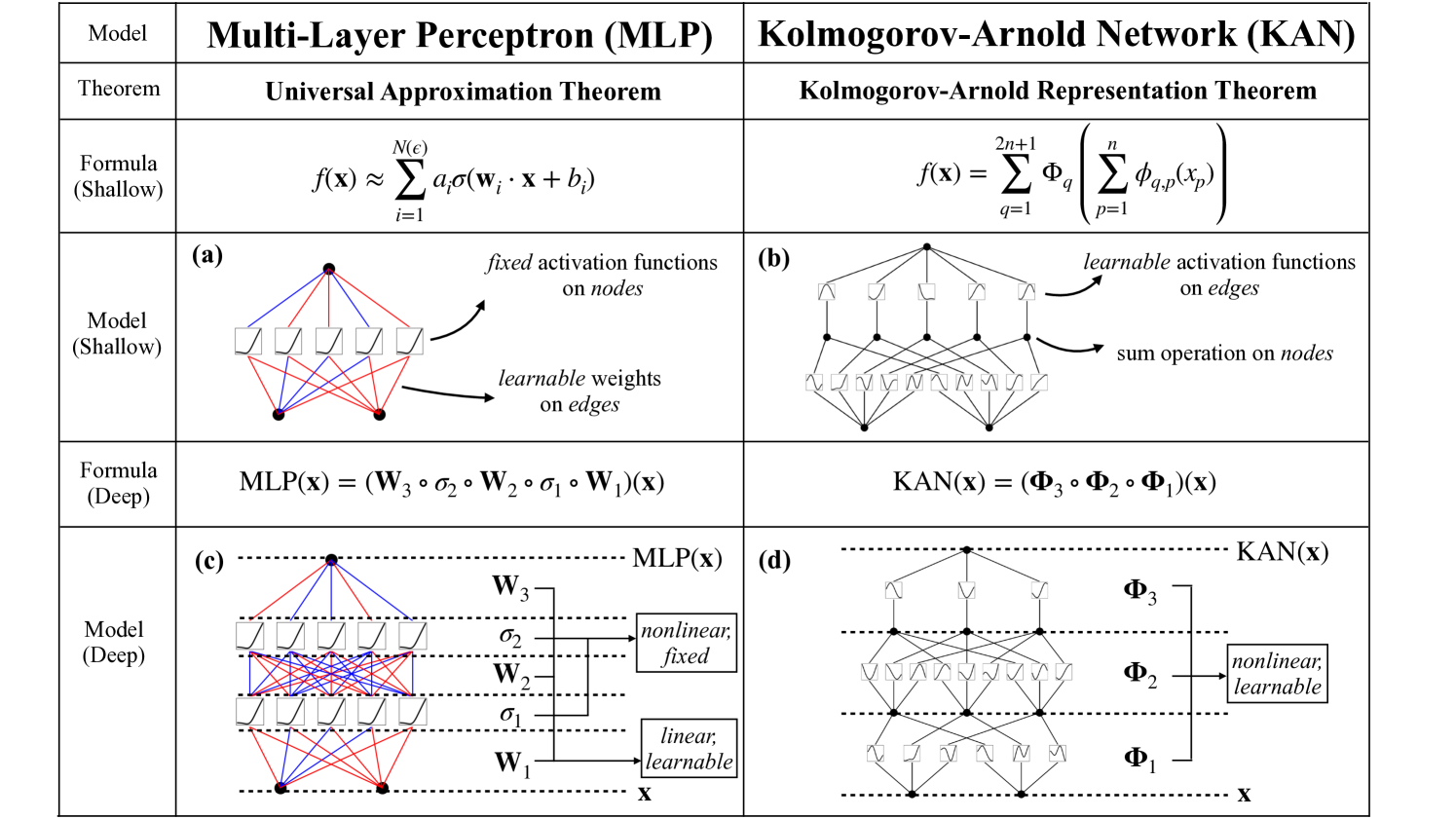
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljav{c}i'c, Thomas Y. Hou, Max Tegmark
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (neurons), KANs have learnable activation functions on edges (weights). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Read more6/18/2024