KG-RAG: Bridging the Gap Between Knowledge and Creativity
2405.12035
0
0

Abstract
Ensuring factual accuracy while maintaining the creative capabilities of Large Language Model Agents (LMAs) poses significant challenges in the development of intelligent agent systems. LMAs face prevalent issues such as information hallucinations, catastrophic forgetting, and limitations in processing long contexts when dealing with knowledge-intensive tasks. This paper introduces a KG-RAG (Knowledge Graph-Retrieval Augmented Generation) pipeline, a novel framework designed to enhance the knowledge capabilities of LMAs by integrating structured Knowledge Graphs (KGs) with the functionalities of LLMs, thereby significantly reducing the reliance on the latent knowledge of LLMs. The KG-RAG pipeline constructs a KG from unstructured text and then performs information retrieval over the newly created graph to perform KGQA (Knowledge Graph Question Answering). The retrieval methodology leverages a novel algorithm called Chain of Explorations (CoE) which benefits from LLMs reasoning to explore nodes and relationships within the KG sequentially. Preliminary experiments on the ComplexWebQuestions dataset demonstrate notable improvements in the reduction of hallucinated content and suggest a promising path toward developing intelligent systems adept at handling knowledge-intensive tasks.
Create account to get full access
Overview
• The paper "KG-RAG: Bridging the Gap Between Knowledge and Creativity" explores a novel approach to combining knowledge graphs and retrieval-augmented generation (RAG) models to improve the performance of large language models (LLMs) on various tasks.
• It builds upon previous research on retrieval-augmented generation and surveys the integration of RAG with LLMs.
• The proposed KG-RAG model aims to leverage knowledge graphs to enhance the knowledge and reasoning capabilities of LLMs, leading to improved performance on tasks such as customer service, biomedical knowledge generation, and general language understanding.
Plain English Explanation
The paper describes a new way to combine large language models (LLMs) with knowledge graphs to create a more powerful and knowledgeable AI system. LLMs are powerful at generating human-like text, but they can sometimes lack the specific knowledge needed for certain tasks.
The researchers developed a model called "KG-RAG" that bridges the gap between the broad knowledge of LLMs and the structured information in knowledge graphs. Knowledge graphs are databases that store information about the world in a structured way, similar to how the human brain stores knowledge.
By integrating the knowledge graph into the LLM, the KG-RAG model can draw upon both the language understanding capabilities of the LLM and the structured knowledge in the graph. This allows the model to generate more informative and relevant text for tasks like customer service, biomedical knowledge generation, and general language understanding.
The key insight is that by combining the strengths of LLMs and knowledge graphs, the KG-RAG model can produce more knowledgeable and coherent text, bridging the gap between the model's language abilities and its access to structured information about the world.
Technical Explanation
The KG-RAG model builds on the retrieval-augmented generation (RAG) approach, which combines a language model with a retrieval module to leverage external information sources during text generation.
In the case of KG-RAG, the external information source is a knowledge graph. The model consists of two key components:
-
Knowledge Graph Encoder: This module encodes the structured knowledge in the knowledge graph into a format that can be efficiently used by the language model.
-
Retrieval-Augmented Generation: This component integrates the knowledge graph encoder with a large language model, allowing the model to retrieve relevant information from the knowledge graph and incorporate it into the generated text.
During the generation process, the KG-RAG model first encodes the input text using the language model. It then retrieves relevant information from the knowledge graph based on the input, and uses this information to guide the text generation process. This allows the model to produce more knowledgeable and coherent output, as it can draw upon the structured information in the knowledge graph to supplement the language understanding capabilities of the LLM.
The researchers evaluate the KG-RAG model on a range of tasks, including customer service, biomedical knowledge generation, and general language understanding. The results demonstrate the effectiveness of the KG-RAG approach in leveraging knowledge graphs to improve the performance of large language models on these tasks.
Critical Analysis
The paper presents a promising approach to enhancing the knowledge and reasoning capabilities of large language models through the integration of knowledge graphs. However, the authors acknowledge several limitations and areas for future research:
-
Scalability: The performance of the KG-RAG model may be sensitive to the size and quality of the knowledge graph used. Scaling the approach to larger knowledge graphs and maintaining efficient retrieval remains an open challenge.
-
Domain Specificity: While the model demonstrates strong performance on certain tasks, the authors note that the benefits may be more pronounced in domains with well-structured knowledge graphs, such as the biomedical field. Extending the approach to more general domains may require further advancements.
-
Interpretability: The authors do not extensively explore the interpretability of the KG-RAG model, which is an important consideration for real-world applications where transparency and explainability are often desirable.
-
Potential Biases: As with any large language model, the KG-RAG approach may inherit or amplify biases present in the training data or the knowledge graph. The researchers should investigate these potential issues and develop strategies to mitigate them.
Despite these limitations, the KG-RAG model represents a significant step forward in bridging the gap between the language understanding capabilities of LLMs and the structured knowledge available in knowledge graphs. Further research in this direction has the potential to unlock new possibilities for more knowledgeable and coherent language AI systems.
Conclusion
The "KG-RAG: Bridging the Gap Between Knowledge and Creativity" paper introduces a novel approach to combining knowledge graphs and retrieval-augmented generation (RAG) models to enhance the performance of large language models (LLMs) on a variety of tasks. By integrating the structured knowledge in knowledge graphs with the language understanding capabilities of LLMs, the KG-RAG model is able to generate more informative and relevant text, as demonstrated in customer service, biomedical knowledge generation, and general language understanding tasks.
While the paper highlights some limitations and areas for further research, the KG-RAG approach represents a significant step forward in the field of retrieval-augmented generation and the integration of knowledge graphs with large language models. As the researchers continue to refine and scale the model, it has the potential to unlock new possibilities for more knowledgeable and coherent language AI systems that can better assist and serve human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
Costas Mavromatis, George Karypis
0
0
Knowledge Graphs (KGs) represent human-crafted factual knowledge in the form of triplets (head, relation, tail), which collectively form a graph. Question Answering over KGs (KGQA) is the task of answering natural questions grounding the reasoning to the information provided by the KG. Large Language Models (LLMs) are the state-of-the-art models for QA tasks due to their remarkable ability to understand natural language. On the other hand, Graph Neural Networks (GNNs) have been widely used for KGQA as they can handle the complex graph information stored in the KG. In this work, we introduce GNN-RAG, a novel method for combining language understanding abilities of LLMs with the reasoning abilities of GNNs in a retrieval-augmented generation (RAG) style. First, a GNN reasons over a dense KG subgraph to retrieve answer candidates for a given question. Second, the shortest paths in the KG that connect question entities and answer candidates are extracted to represent KG reasoning paths. The extracted paths are verbalized and given as input for LLM reasoning with RAG. In our GNN-RAG framework, the GNN acts as a dense subgraph reasoner to extract useful graph information, while the LLM leverages its natural language processing ability for ultimate KGQA. Furthermore, we develop a retrieval augmentation (RA) technique to further boost KGQA performance with GNN-RAG. Experimental results show that GNN-RAG achieves state-of-the-art performance in two widely used KGQA benchmarks (WebQSP and CWQ), outperforming or matching GPT-4 performance with a 7B tuned LLM. In addition, GNN-RAG excels on multi-hop and multi-entity questions outperforming competing approaches by 8.9--15.5% points at answer F1.
5/31/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024
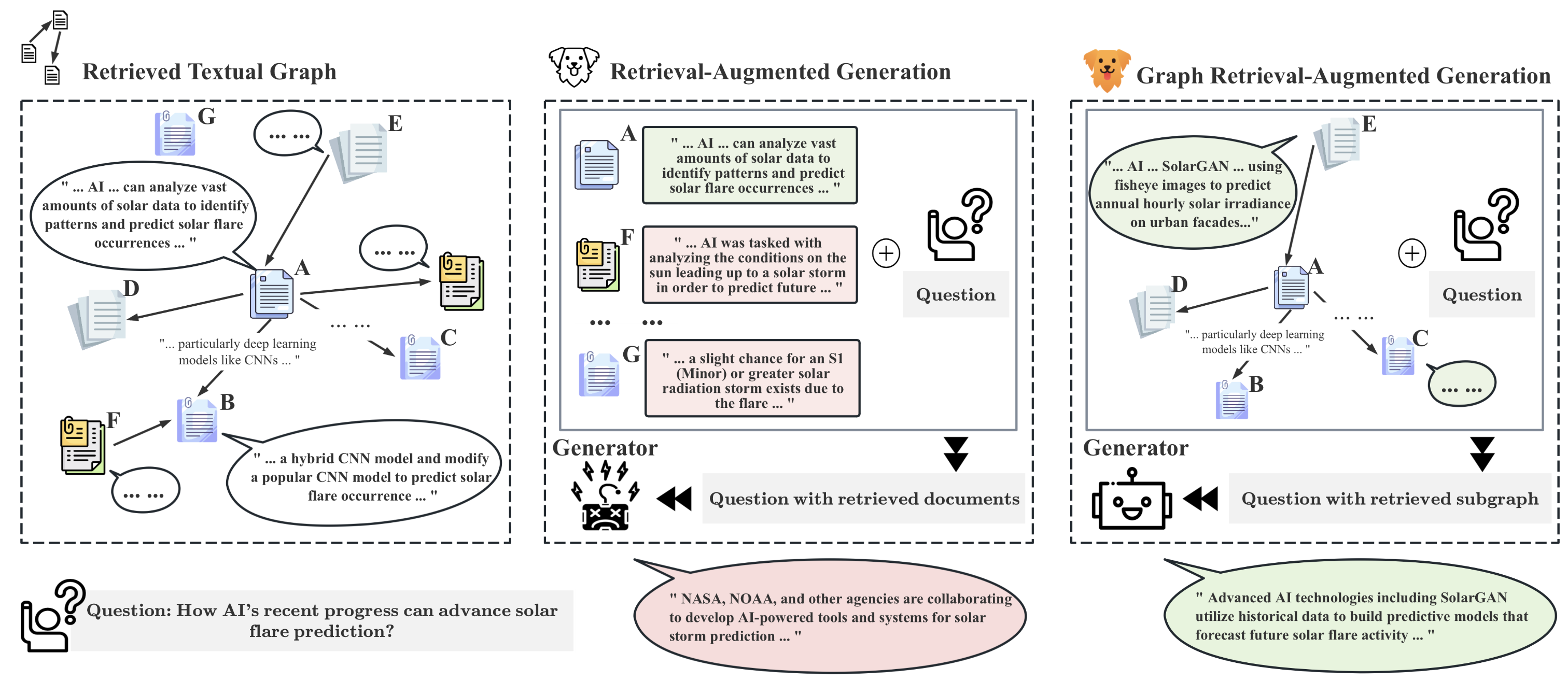
GRAG: Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, Liang Zhao
0
0
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
5/28/2024
🛸
Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering
Zhentao Xu, Mark Jerome Cruz, Matthew Guevara, Tie Wang, Manasi Deshpande, Xiaofeng Wang, Zheng Li
0
0
In customer service technical support, swiftly and accurately retrieving relevant past issues is critical for efficiently resolving customer inquiries. The conventional retrieval methods in retrieval-augmented generation (RAG) for large language models (LLMs) treat a large corpus of past issue tracking tickets as plain text, ignoring the crucial intra-issue structure and inter-issue relations, which limits performance. We introduce a novel customer service question-answering method that amalgamates RAG with a knowledge graph (KG). Our method constructs a KG from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations. During the question-answering phase, our method parses consumer queries and retrieves related sub-graphs from the KG to generate answers. This integration of a KG not only improves retrieval accuracy by preserving customer service structure information but also enhances answering quality by mitigating the effects of text segmentation. Empirical assessments on our benchmark datasets, utilizing key retrieval (MRR, Recall@K, NDCG@K) and text generation (BLEU, ROUGE, METEOR) metrics, reveal that our method outperforms the baseline by 77.6% in MRR and by 0.32 in BLEU. Our method has been deployed within LinkedIn's customer service team for approximately six months and has reduced the median per-issue resolution time by 28.6%.
5/7/2024