GRAG: Graph Retrieval-Augmented Generation
2405.16506
0
0
Abstract
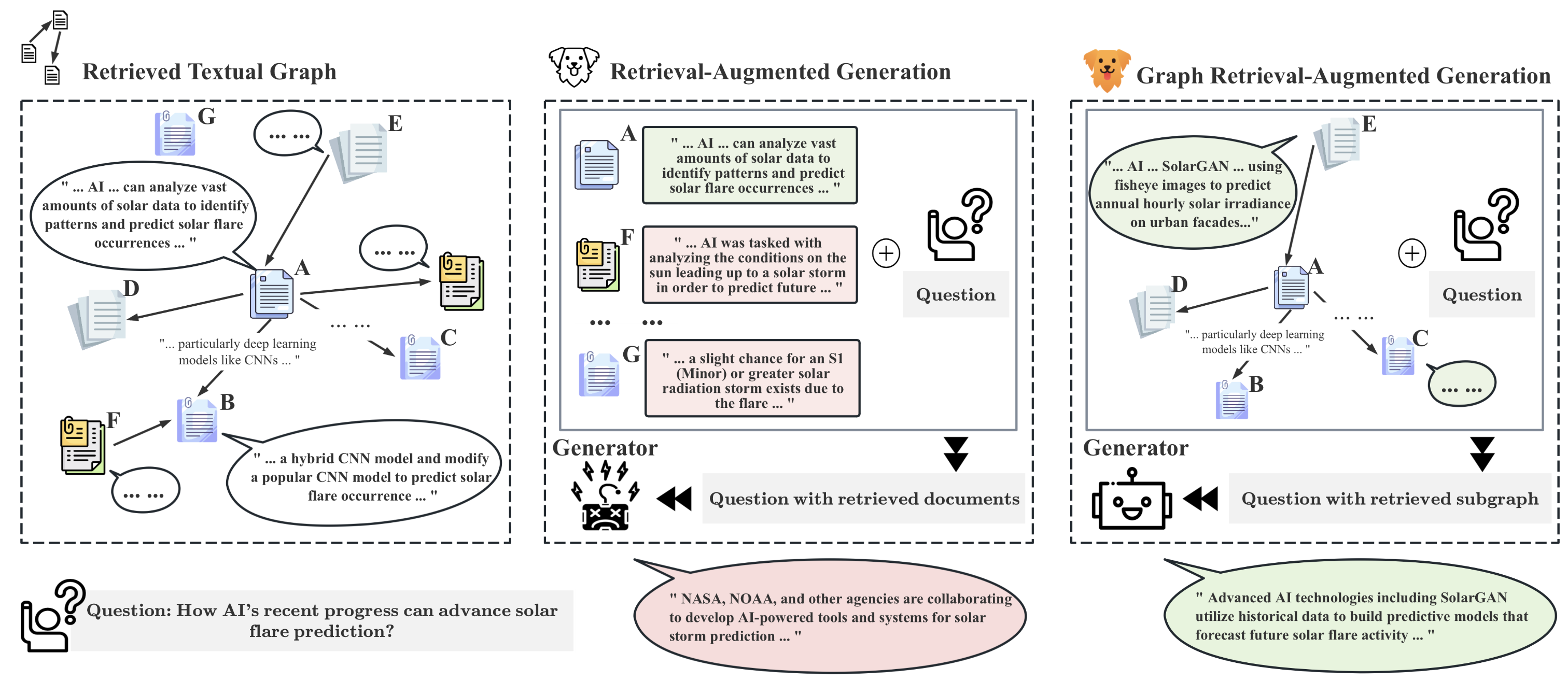
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
Create account to get full access
Overview
- This paper introduces GRAG (Graph Retrieval-Augmented Generation), a novel technique that leverages large language models (LLMs) and retrieval to enhance text generation.
- GRAG aims to empower LLMs to better understand and utilize relational knowledge from graphs, allowing for more informative and coherent text generation.
- The approach involves retrieving relevant subgraphs from a knowledge base and incorporating them into the language model's generation process.
Plain English Explanation
GRAG is a new method that helps large language models, like the ones used in chatbots and writing assistants, to be better at generating text. It does this by allowing the models to access and use information from knowledge graphs - databases that store information in a structured, interconnected way.
Normally, language models generate text based solely on the patterns they've learned from the training data. But with GRAG, the model can retrieve relevant information from a knowledge graph and weave it into the text it produces. This allows the generated text to be more informative, coherent, and grounded in real-world knowledge.
For example, if a user asks the language model to write about a historical event, GRAG could retrieve information about the key people, dates, and locations involved from a knowledge graph. The model could then incorporate this contextual information into the text it generates, resulting in a more accurate and comprehensive response.
By bridging the gap between the language model's text generation capabilities and the structured knowledge stored in graphs, GRAG aims to empower these large models to produce more knowledgeable and meaningful text. This could lead to significant improvements in applications like dialog systems, question answering, and content generation.
Technical Explanation
The core idea behind GRAG is to combine the strengths of large language models (LLMs) and knowledge graphs to enhance text generation. LLMs excel at generating fluent, contextual text, but can lack the grounding in real-world knowledge that is often necessary for informative and coherent output. Knowledge graphs, on the other hand, provide a structured representation of entities and their relationships, but lack the language generation capabilities of LLMs.
GRAG bridges this gap by incorporating a graph retrieval module into the language model's generation process. Given an input prompt, the model first retrieves a relevant subgraph from a knowledge base. It then encodes this subgraph and integrates it with the language model's representation of the prompt, allowing the model to condition its text generation on the retrieved knowledge.
The authors evaluate GRAG on a range of text generation tasks, including dialog generation, question answering, and summarization. Their results demonstrate that GRAG consistently outperforms baseline language models, producing more informative, coherent, and factually accurate text.
Critical Analysis
The GRAG paper presents a promising approach to enhancing the capabilities of large language models, but it also raises some important considerations:
One key limitation is the reliance on a static knowledge graph. While the knowledge graph provides a structured source of information, it may not always contain the most up-to-date or relevant facts for a given generation task. Integrating GRAG with a more dynamic knowledge source, such as a collaborative retrieval-augmented generation system, could help address this issue.
Additionally, the paper does not thoroughly explore the potential biases or inconsistencies that may arise from the interaction between the language model and the retrieved knowledge. Further research is needed to understand how GRAG handles conflicting information or handles edge cases where the knowledge graph may be incomplete or inaccurate.
Overall, the GRAG approach represents an important step forward in empowering large language models to leverage structured knowledge. However, continued research and refinement will be necessary to fully unlock the potential of this hybrid approach to text generation.
Conclusion
The GRAG paper introduces a novel technique that combines the strengths of large language models and knowledge graphs to enhance text generation. By retrieving relevant subgraphs and integrating them into the language model's generation process, GRAG allows for the production of more informative, coherent, and factually accurate text.
This research represents an important advancement in the field of language AI, with potential applications in a wide range of domains, from dialog systems and question answering to content generation. By bridging the gap between the language understanding of LLMs and the structured knowledge of graphs, GRAG opens up new possibilities for more intelligent and useful text-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Augmenting Textual Generation via Topology Aware Retrieval
Yu Wang, Nedim Lipka, Ruiyi Zhang, Alexa Siu, Yuying Zhao, Bo Ni, Xin Wang, Ryan Rossi, Tyler Derr
0
0
Despite the impressive advancements of Large Language Models (LLMs) in generating text, they are often limited by the knowledge contained in the input and prone to producing inaccurate or hallucinated content. To tackle these issues, Retrieval-augmented Generation (RAG) is employed as an effective strategy to enhance the available knowledge base and anchor the responses in reality by pulling additional texts from external databases. In real-world applications, texts are often linked through entities within a graph, such as citations in academic papers or comments in social networks. This paper exploits these topological relationships to guide the retrieval process in RAG. Specifically, we explore two kinds of topological connections: proximity-based, focusing on closely connected nodes, and role-based, which looks at nodes sharing similar subgraph structures. Our empirical research confirms their relevance to text relationships, leading us to develop a Topology-aware Retrieval-augmented Generation framework. This framework includes a retrieval module that selects texts based on their topological relationships and an aggregation module that integrates these texts into prompts to stimulate LLMs for text generation. We have curated established text-attributed networks and conducted comprehensive experiments to validate the effectiveness of this framework, demonstrating its potential to enhance RAG with topological awareness.
5/29/2024
🛸
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, Bryan Hooi
0
0
Given a graph with textual attributes, we enable users to `chat with their graph': that is, to ask questions about the graph using a conversational interface. In response to a user's questions, our method provides textual replies and highlights the relevant parts of the graph. While existing works integrate large language models (LLMs) and graph neural networks (GNNs) in various ways, they mostly focus on either conventional graph tasks (such as node, edge, and graph classification), or on answering simple graph queries on small or synthetic graphs. In contrast, we develop a flexible question-answering framework targeting real-world textual graphs, applicable to multiple applications including scene graph understanding, common sense reasoning, and knowledge graph reasoning. Toward this goal, we first develop a Graph Question Answering (GraphQA) benchmark with data collected from different tasks. Then, we propose our G-Retriever method, introducing the first retrieval-augmented generation (RAG) approach for general textual graphs, which can be fine-tuned to enhance graph understanding via soft prompting. To resist hallucination and to allow for textual graphs that greatly exceed the LLM's context window size, G-Retriever performs RAG over a graph by formulating this task as a Prize-Collecting Steiner Tree optimization problem. Empirical evaluations show that our method outperforms baselines on textual graph tasks from multiple domains, scales well with larger graph sizes, and mitigates hallucination.~footnote{Our codes and datasets are available at: url{https://github.com/XiaoxinHe/G-Retriever}}
5/28/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024

KG-RAG: Bridging the Gap Between Knowledge and Creativity
Diego Sanmartin
0
0
Ensuring factual accuracy while maintaining the creative capabilities of Large Language Model Agents (LMAs) poses significant challenges in the development of intelligent agent systems. LMAs face prevalent issues such as information hallucinations, catastrophic forgetting, and limitations in processing long contexts when dealing with knowledge-intensive tasks. This paper introduces a KG-RAG (Knowledge Graph-Retrieval Augmented Generation) pipeline, a novel framework designed to enhance the knowledge capabilities of LMAs by integrating structured Knowledge Graphs (KGs) with the functionalities of LLMs, thereby significantly reducing the reliance on the latent knowledge of LLMs. The KG-RAG pipeline constructs a KG from unstructured text and then performs information retrieval over the newly created graph to perform KGQA (Knowledge Graph Question Answering). The retrieval methodology leverages a novel algorithm called Chain of Explorations (CoE) which benefits from LLMs reasoning to explore nodes and relationships within the KG sequentially. Preliminary experiments on the ComplexWebQuestions dataset demonstrate notable improvements in the reduction of hallucinated content and suggest a promising path toward developing intelligent systems adept at handling knowledge-intensive tasks.
5/21/2024