Kolmogorov-Arnold Networks in Low-Data Regimes: A Comparative Study with Multilayer Perceptrons

0

Sign in to get full access
Overview
- This paper compares the performance of Kolmogorov-Arnold Networks (KANs) and Multilayer Perceptrons (MLPs) in low-data regimes.
- KANs are a type of neural network architecture inspired by Kolmogorov's universal approximation theorem.
- The study examines the relative strengths and weaknesses of KANs and MLPs across a range of small-scale datasets.
Plain English Explanation
The paper looks at two different types of neural networks - Kolmogorov-Arnold Networks (KANs) and Multilayer Perceptrons (MLPs) - and compares how they perform when there is only a small amount of training data available.
Neural networks are a type of machine learning model that can be very powerful, but they typically require a lot of training data to work well. This can be a problem in real-world situations where data is limited, such as when developing AI systems for specialized or niche applications.
The researchers wanted to see if KANs, which are designed based on a mathematical theorem about function approximation, might be better able to learn from small datasets compared to the more common MLP architecture. They tested the two models on several different small-scale datasets and compared their performance.
The results suggest that KANs can indeed outperform MLPs in low-data regimes, potentially making them a better choice for applications where data is scarce. This could have important implications for developing efficient and effective AI systems in a wide range of domains.
Technical Explanation
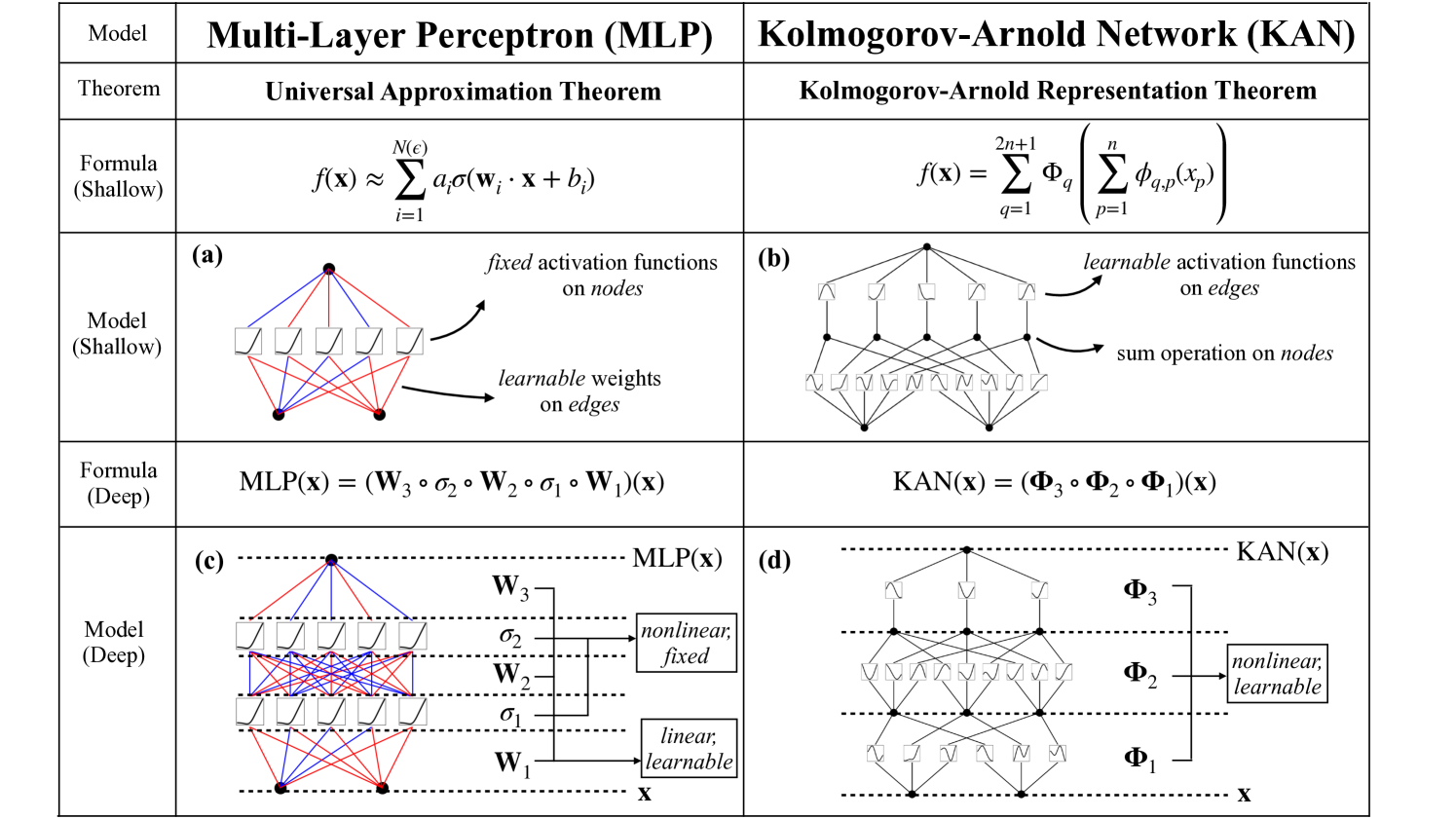
The paper compares the performance of Kolmogorov-Arnold Networks (KANs) and Multilayer Perceptrons (MLPs) on a variety of small-scale datasets. KANs are a type of neural network architecture inspired by Kolmogorov's universal approximation theorem, which states that any continuous function can be represented as a superposition of simpler functions.
The researchers hypothesized that the structural properties of KANs might make them better able to learn from limited training data compared to traditional MLPs. To test this, they conducted experiments across several small datasets spanning image classification, tabular data, and synthetic function approximation tasks.
The results indicate that KANs generally outperformed MLPs when only a small amount of training data was available. The authors attribute this to KANs' ability to more efficiently utilize the limited information in the training set due to their specialized architecture. Notably, the advantage of KANs was most pronounced on the more complex function approximation tasks.
The paper also discusses potential limitations of KANs, such as the challenge of optimizing their specialized architecture and the need for further research to fully understand their capabilities and limitations in low-data regimes. Overall, the findings suggest that KANs may be a promising alternative to MLPs in applications where training data is scarce.
Critical Analysis
The paper provides a thorough and well-designed comparative study of KANs and MLPs in low-data regimes. The experimental setup is thoughtful, covering a diverse range of datasets and tasks to get a comprehensive understanding of the models' relative strengths and weaknesses.
One potential limitation mentioned by the authors is the challenge of optimizing the specialized KAN architecture, which could make them more difficult to train and deploy in practice compared to the more widely-used MLP. The paper also notes the need for further research to fully characterize the capabilities of KANs, especially in terms of their ability to learn from limited data across a wider array of problem domains.
While the results are promising for the use of KANs in low-data applications, it would be valuable to see additional comparisons to other neural network architectures, such as few-shot learning or meta-learning approaches, to better situate the relative merits of the KAN design. Exploring the transferability of KAN models across different tasks would also be an interesting avenue for future work.
Overall, this paper makes a compelling case for the potential of KANs as an alternative to MLPs when training data is scarce. The findings could have important implications for developing efficient and effective AI systems in domains where data is limited.
Conclusion
This paper presents a comparative study of Kolmogorov-Arnold Networks (KANs) and Multilayer Perceptrons (MLPs) in low-data regimes. The results suggest that KANs, which are inspired by Kolmogorov's universal approximation theorem, can outperform traditional MLPs when only a small amount of training data is available.
The advantages of KANs appear to be most pronounced on more complex function approximation tasks, highlighting their potential utility in applications where data is scarce. While the paper notes some challenges in optimizing the specialized KAN architecture, the findings indicate that this model design may be a promising alternative to MLPs for developing efficient and effective AI systems in low-data scenarios.
Overall, this work contributes valuable insights into the relative strengths of different neural network architectures, and could help guide the selection of appropriate models for a variety of real-world applications with limited training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Kolmogorov-Arnold Networks in Low-Data Regimes: A Comparative Study with Multilayer Perceptrons
Farhad Pourkamali-Anaraki
Multilayer Perceptrons (MLPs) have long been a cornerstone in deep learning, known for their capacity to model complex relationships. Recently, Kolmogorov-Arnold Networks (KANs) have emerged as a compelling alternative, utilizing highly flexible learnable activation functions directly on network edges, a departure from the neuron-centric approach of MLPs. However, KANs significantly increase the number of learnable parameters, raising concerns about their effectiveness in data-scarce environments. This paper presents a comprehensive comparative study of MLPs and KANs from both algorithmic and experimental perspectives, with a focus on low-data regimes. We introduce an effective technique for designing MLPs with unique, parameterized activation functions for each neuron, enabling a more balanced comparison with KANs. Using empirical evaluations on simulated data and two real-world data sets from medicine and engineering, we explore the trade-offs between model complexity and accuracy, with particular attention to the role of network depth. Our findings show that MLPs with individualized activation functions achieve significantly higher predictive accuracy with only a modest increase in parameters, especially when the sample size is limited to around one hundred. For example, in a three-class classification problem within additive manufacturing, MLPs achieve a median accuracy of 0.91, significantly outperforming KANs, which only reach a median accuracy of 0.53 with default hyperparameters. These results offer valuable insights into the impact of activation function selection in neural networks.
Read more9/17/2024
19
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljav{c}i'c, Thomas Y. Hou, Max Tegmark
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (neurons), KANs have learnable activation functions on edges (weights). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Read more6/18/2024

0
Activation Space Selectable Kolmogorov-Arnold Networks
Zhuoqin Yang, Jiansong Zhang, Xiaoling Luo, Zheng Lu, Linlin Shen
The multilayer perceptron (MLP), a fundamental paradigm in current artificial intelligence, is widely applied in fields such as computer vision and natural language processing. However, the recently proposed Kolmogorov-Arnold Network (KAN), based on nonlinear additive connections, has been proven to achieve performance comparable to MLPs with significantly fewer parameters. Despite this potential, the use of a single activation function space results in reduced performance of KAN and related works across different tasks. To address this issue, we propose an activation space Selectable KAN (S-KAN). S-KAN employs an adaptive strategy to choose the possible activation mode for data at each feedforward KAN node. Our approach outperforms baseline methods in seven representative function fitting tasks and significantly surpasses MLP methods with the same level of parameters. Furthermore, we extend the structure of S-KAN and propose an activation space selectable Convolutional KAN (S-ConvKAN), which achieves leading results on four general image classification datasets. Our method mitigates the performance variability of the original KAN across different tasks and demonstrates through extensive experiments that feedforward KANs with selectable activations can achieve or even exceed the performance of MLP-based methods. This work contributes to the understanding of the data-centric design of new AI paradigms and provides a foundational reference for innovations in KAN-based network architectures.
Read more8/19/2024

0
KAN we improve on HEP classification tasks? Kolmogorov-Arnold Networks applied to an LHC physics example
Johannes Erdmann, Florian Mausolf, Jan Lukas Spah
Recently, Kolmogorov-Arnold Networks (KANs) have been proposed as an alternative to multilayer perceptrons, suggesting advantages in performance and interpretability. We study a typical binary event classification task in high-energy physics including high-level features and comment on the performance and interpretability of KANs in this context. We find that the learned activation functions of a one-layer KAN resemble the log-likelihood ratio of the input features. In deeper KANs, the activations in the first KAN layer differ from those in the one-layer KAN, which indicates that the deeper KANs learn more complex representations of the data. We study KANs with different depths and widths and we compare them to multilayer perceptrons in terms of performance and number of trainable parameters. For the chosen classification task, we do not find that KANs are more parameter efficient. However, small KANs may offer advantages in terms of interpretability that come at the cost of only a moderate loss in performance.
Read more8/7/2024