Kolmogorov-Arnold Transformer

0

Sign in to get full access
Overview
- The paper introduces the Kolmogorov–Arnold Transformer (KAT), a novel neural network architecture inspired by the Kolmogorov-Arnold representation theorem.
- KAT aims to capture the inherent structure of data and learn efficient representations, with potential applications in various domains like time series classification and forecasting.
- The authors provide a detailed technical explanation of the KAT architecture and demonstrate its performance on several benchmark datasets.
Plain English Explanation
The Kolmogorov–Arnold Transformer (KAT) is a new type of neural network that is designed to better understand the underlying structure of data. It is based on a mathematical result known as the Kolmogorov-Arnold representation theorem, which states that any continuous function can be approximated by a combination of simpler functions.
The key idea behind KAT is to leverage this property to learn efficient representations of data. Instead of treating data as a black box, KAT tries to extract the inherent patterns and relationships within the data. This can be useful in a variety of applications, such as time series classification and forecasting.
The authors of the paper describe the technical details of the KAT architecture and show that it can outperform other neural network models on several benchmark datasets. This suggests that the Kolmogorov-Arnold representation can be a powerful tool for building more effective and interpretable machine learning models.
Technical Explanation
The paper introduces the Kolmogorov–Arnold Transformer (KAT), a novel neural network architecture that is inspired by the Kolmogorov-Arnold representation theorem. This theorem states that any continuous function can be approximated by a finite sum of simpler functions, which the authors leverage to design a model that can efficiently capture the inherent structure of data.
The core component of KAT is the Kolmogorov-Arnold (KA) layer, which consists of a combination of convolutional and fully connected layers. This layer applies a series of transformations to the input data, effectively decomposing it into a sum of simpler functions that reflect the underlying structure of the data.
The authors then stack multiple KA layers to form the complete KAT architecture, which can be used for a variety of tasks, such as time series classification and forecasting. They evaluate the performance of KAT on several benchmark datasets and demonstrate that it can outperform other neural network models, especially in cases where the data has a clear underlying structure.
Critical Analysis
The paper provides a compelling theoretical motivation for the Kolmogorov–Arnold Transformer (KAT) architecture and presents promising experimental results. However, the authors also acknowledge several limitations and areas for further research.
One potential concern is the computational complexity of the KA layers, which may limit the scalability of the KAT model to large-scale datasets or real-time applications. The authors suggest that further optimization of the layer design or the use of rational Kolmogorov-Arnold networks could help address this issue.
Additionally, the paper does not provide a detailed analysis of the interpretability and explainability of the KAT model. While the Kolmogorov-Arnold representation theorem suggests that the model should be able to extract meaningful patterns from the data, the authors could have explored this aspect more thoroughly, perhaps through visualization or feature importance analysis.
Further research could also investigate the performance of KAT on a wider range of tasks and datasets, as well as its robustness to various data characteristics, such as noise or missing values. Comparisons with other state-of-the-art architectures designed for structured data representation, such as Graph Neural Networks, could also provide valuable insights.
Conclusion
The Kolmogorov–Arnold Transformer (KAT) proposed in this paper represents a novel and promising approach to neural network design, leveraging the Kolmogorov-Arnold representation theorem to capture the inherent structure of data. The authors demonstrate the potential of this architecture through experimental results, suggesting that KAT could be a valuable tool for a variety of applications, particularly in domains where the underlying data structure is important.
While the paper identifies some limitations and areas for further research, the core idea of using the Kolmogorov-Arnold representation to build more efficient and interpretable machine learning models is compelling and deserves further exploration. As the field of deep learning continues to evolve, architectures like KAT could play an important role in advancing our ability to understand and model complex real-world phenomena.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Kolmogorov-Arnold Transformer
Xingyi Yang, Xinchao Wang
Transformers stand as the cornerstone of mordern deep learning. Traditionally, these models rely on multi-layer perceptron (MLP) layers to mix the information between channels. In this paper, we introduce the Kolmogorov-Arnold Transformer (KAT), a novel architecture that replaces MLP layers with Kolmogorov-Arnold Network (KAN) layers to enhance the expressiveness and performance of the model. Integrating KANs into transformers, however, is no easy feat, especially when scaled up. Specifically, we identify three key challenges: (C1) Base function. The standard B-spline function used in KANs is not optimized for parallel computing on modern hardware, resulting in slower inference speeds. (C2) Parameter and Computation Inefficiency. KAN requires a unique function for each input-output pair, making the computation extremely large. (C3) Weight initialization. The initialization of weights in KANs is particularly challenging due to their learnable activation functions, which are critical for achieving convergence in deep neural networks. To overcome the aforementioned challenges, we propose three key solutions: (S1) Rational basis. We replace B-spline functions with rational functions to improve compatibility with modern GPUs. By implementing this in CUDA, we achieve faster computations. (S2) Group KAN. We share the activation weights through a group of neurons, to reduce the computational load without sacrificing performance. (S3) Variance-preserving initialization. We carefully initialize the activation weights to make sure that the activation variance is maintained across layers. With these designs, KAT scales effectively and readily outperforms traditional MLP-based transformers.
Read more9/18/2024
19
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljav{c}i'c, Thomas Y. Hou, Max Tegmark
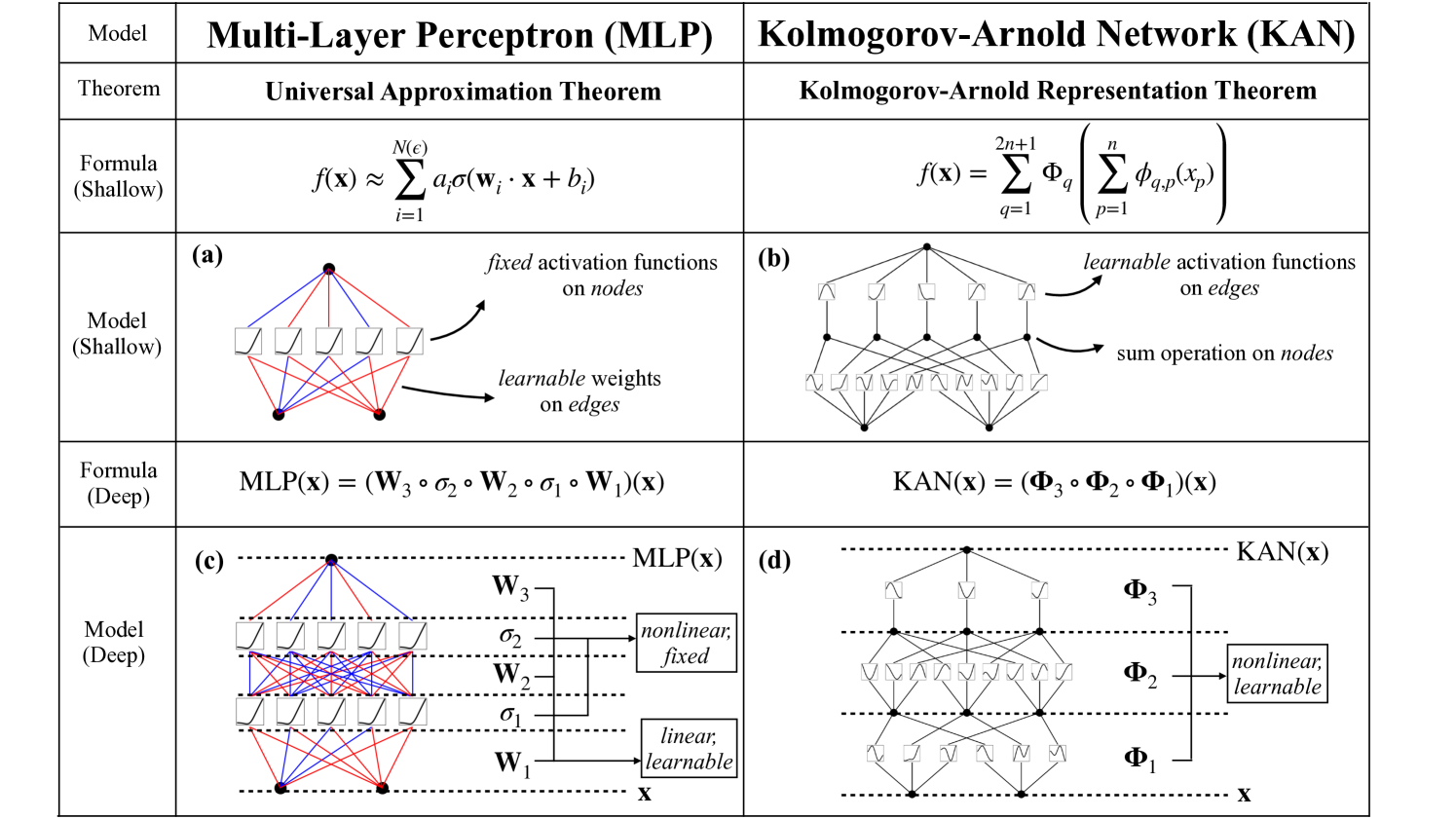
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (neurons), KANs have learnable activation functions on edges (weights). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Read more6/18/2024

0
rKAN: Rational Kolmogorov-Arnold Networks
Alireza Afzal Aghaei
The development of Kolmogorov-Arnold networks (KANs) marks a significant shift from traditional multi-layer perceptrons in deep learning. Initially, KANs employed B-spline curves as their primary basis function, but their inherent complexity posed implementation challenges. Consequently, researchers have explored alternative basis functions such as Wavelets, Polynomials, and Fractional functions. In this research, we explore the use of rational functions as a novel basis function for KANs. We propose two different approaches based on Pade approximation and rational Jacobi functions as trainable basis functions, establishing the rational KAN (rKAN). We then evaluate rKAN's performance in various deep learning and physics-informed tasks to demonstrate its practicality and effectiveness in function approximation.
Read more6/21/2024

0
Kolmogorov-Arnold Networks (KAN) for Time Series Classification and Robust Analysis
Chang Dong, Liangwei Zheng, Weitong Chen
Kolmogorov-Arnold Networks (KAN) has recently attracted significant attention as a promising alternative to traditional Multi-Layer Perceptrons (MLP). Despite their theoretical appeal, KAN require validation on large-scale benchmark datasets. Time series data, which has become increasingly prevalent in recent years, especially univariate time series are naturally suited for validating KAN. Therefore, we conducted a fair comparison among KAN, MLP, and mixed structures. The results indicate that KAN can achieve performance comparable to, or even slightly better than, MLP across 128 time series datasets. We also performed an ablation study on KAN, revealing that the output is primarily determined by the base component instead of b-spline function. Furthermore, we assessed the robustness of these models and found that KAN and the hybrid structure MLP_KAN exhibit significant robustness advantages, attributed to their lower Lipschitz constants. This suggests that KAN and KAN layers hold strong potential to be robust models or to improve the adversarial robustness of other models.
Read more9/12/2024