KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting

0
Sign in to get full access
Overview
- Introduces KoReA-SFL, a knowledge replay-based split federated learning approach to address catastrophic forgetting in continual learning settings
- Proposes a method to maintain performance on past tasks while learning new tasks in a federated learning environment
- Evaluates the approach on multiple benchmark datasets and compares it to state-of-the-art continual learning and federated learning methods
Plain English Explanation
KoReA-SFL is a new machine learning technique that aims to help AI systems learn new information without forgetting what they've learned before. This is a common problem in continual learning, where AI models need to keep updating their knowledge over time.
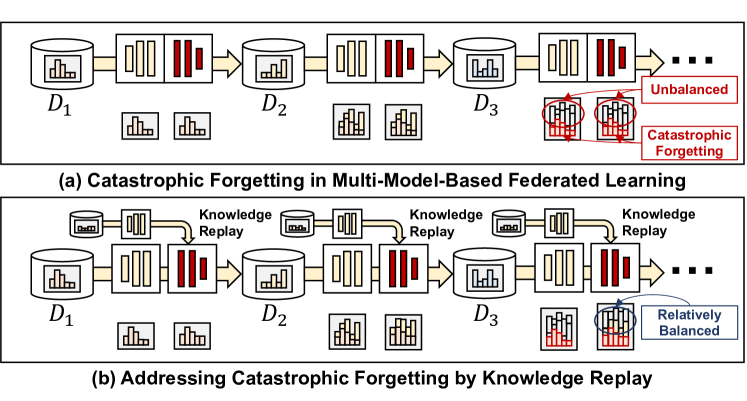
The key idea behind KoReA-SFL is to use knowledge replay - storing and replaying examples of past tasks - to help the model remember what it has learned previously. This is combined with a federated learning approach, where the model is trained across multiple devices or users without centralizing all the data.
By using knowledge replay in a federated setting, KoReA-SFL can help AI systems learn new skills while preserving their performance on older tasks, overcoming the challenge of catastrophic forgetting. This could be useful for applications where an AI system needs to continually expand its capabilities over time, like personalized federated continual learning or asynchronous federated learning.
Technical Explanation
The KoReA-SFL approach works by splitting the neural network model into two parts - a shared encoder and multiple task-specific decoders. During training, the shared encoder is updated through federated learning, while the decoders are trained individually on each client's data.
To prevent catastrophic forgetting, KoReA-SFL employs a knowledge replay mechanism. Small subsets of data from past tasks are stored and replayed during training, allowing the shared encoder to consolidate its learning without forgetting previous knowledge.
Experiments on benchmark datasets show that KoReA-SFL outperforms state-of-the-art continual learning methods like have-your-cake-and-eat-it-too and one-shot sequential federated learning, as well as federated learning approaches like CORE. This demonstrates the effectiveness of the knowledge replay technique in preserving performance on past tasks while learning new ones in a federated setting.
Critical Analysis
The authors acknowledge that the performance of KoReA-SFL can be sensitive to the choice of hyperparameters, particularly the amount of stored knowledge and the frequency of knowledge replay. Additionally, the paper does not explore the scalability of the approach to a large number of tasks or clients, which would be an important consideration for real-world applications.
Furthermore, the paper does not address the potential privacy implications of storing and replaying user data in a federated setting. This is an important aspect that should be carefully considered, as data privacy is a critical concern in federated learning.
Conclusion
Overall, KoReA-SFL represents an interesting approach to addressing the challenge of catastrophic forgetting in continual learning, leveraging both knowledge replay and federated learning techniques. The results demonstrate promising performance improvements over existing methods, but future research should explore the scalability and privacy implications of the approach in more depth.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting
Zeke Xia, Ming Hu, Dengke Yan, Ruixuan Liu, Anran Li, Xiaofei Xie, Mingsong Chen
Although Split Federated Learning (SFL) is good at enabling knowledge sharing among resource-constrained clients, it suffers from the problem of low training accuracy due to the neglect of data heterogeneity and catastrophic forgetting. To address this issue, we propose a novel SFL approach named KoReA-SFL, which adopts a multi-model aggregation mechanism to alleviate gradient divergence caused by heterogeneous data and a knowledge replay strategy to deal with catastrophic forgetting. Specifically, in KoReA-SFL cloud servers (i.e., fed server and main server) maintain multiple branch model portions rather than a global portion for local training and an aggregated master-model portion for knowledge sharing among branch portions. To avoid catastrophic forgetting, the main server of KoReA-SFL selects multiple assistant devices for knowledge replay according to the training data distribution of each server-side branch-model portion. Experimental results obtained from non-IID and IID scenarios demonstrate that KoReA-SFL significantly outperforms conventional SFL methods (by up to 23.25% test accuracy improvement).
Read more4/22/2024
🔎
0
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Dengke Yan, Ming Hu, Zeke Xia, Yanxin Yang, Jun Xia, Xiaofei Xie, Mingsong Chen
Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5% inference accuracy improvement and 3.54X training acceleration.
Read more4/9/2024
🤯
0
AdaptSFL: Adaptive Split Federated Learning in Resource-constrained Edge Networks
Zheng Lin, Guanqiao Qu, Wei Wei, Xianhao Chen, Kin K. Leung
The increasing complexity of deep neural networks poses significant barriers to democratizing them to resource-limited edge devices. To address this challenge, split federated learning (SFL) has emerged as a promising solution by of floading the primary training workload to a server via model partitioning while enabling parallel training among edge devices. However, although system optimization substantially influences the performance of SFL under resource-constrained systems, the problem remains largely uncharted. In this paper, we provide a convergence analysis of SFL which quantifies the impact of model splitting (MS) and client-side model aggregation (MA) on the learning performance, serving as a theoretical foundation. Then, we propose AdaptSFL, a novel resource-adaptive SFL framework, to expedite SFL under resource-constrained edge computing systems. Specifically, AdaptSFL adaptively controls client-side MA and MS to balance communication-computing latency and training convergence. Extensive simulations across various datasets validate that our proposed AdaptSFL framework takes considerably less time to achieve a target accuracy than benchmarks, demonstrating the effectiveness of the proposed strategies.
Read more5/24/2024
📈
0
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
Yumeng Shao, Jun Li, Long Shi, Kang Wei, Ming Ding, Qianmu Li, Zengxiang Li, Wen Chen, Shi Jin
Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50%, while achieving an average 3% improvement in learning accuracy over state-of-the-art AFL algorithms.
Read more5/14/2024