KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
2401.18079
4
0
🤯
Abstract
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) are increasingly being used for tasks like document analysis and summarization that require processing large amounts of context.
- These large context windows lead to high memory consumption during inference, with the Key-Value (KV) cache activations being a dominant contributor.
- Quantization, a technique to compress data, is a promising approach to reduce the memory footprint of KV cache activations.
- However, existing quantization solutions struggle to accurately represent KV activations at ultra-low precisions (below 4 bits).
Plain English Explanation
Large language models are computer systems that can understand and generate human-like text. They are becoming more widely used for tasks that require analyzing or summarizing large documents or sets of information.
The challenge is that processing all this context requires a lot of computer memory, and the part of the memory used to store the connections between the words and their meanings (the "Key-Value cache") takes up a significant portion of this.
One way to reduce the memory needed is a technique called quantization, which compresses the data by representing it using fewer bits. But current quantization methods don't work well for the Key-Value cache data, especially when trying to use very low precision (like 2-3 bits per value).
Technical Explanation
The authors present a new method called "KVQuant" that addresses this problem. KVQuant incorporates several novel techniques for quantizing the Key-Value cache activations:
- Per-Channel Key Quantization: Adjusts the dimension along which the Key activations are quantized to better match their distribution.
- Pre-RoPE Key Quantization: Quantizes the Key activations before applying the rotary positional embedding, to mitigate its impact on quantization.
- Non-Uniform KV Cache Quantization: Derives per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions.
- Per-Vector Dense-and-Sparse Quantization: Isolates outliers separately for each vector to minimize skews in quantization ranges.
- Q-Norm: Normalizes the quantization centroids to mitigate distribution shift, providing additional benefits for 2-bit quantization.
By applying these techniques, the authors achieve less than 0.1 perplexity degradation (a measure of language model quality) with 3-bit quantization on benchmark datasets, outperforming existing approaches. This enables serving large language models like LLaMA-7B with context lengths up to 1 million tokens on a single GPU, and up to 10 million tokens on an 8-GPU system.
Critical Analysis
The paper provides a comprehensive set of innovations to address the challenges of quantizing Key-Value cache activations in LLMs. The techniques seem well-designed and the results are impressive, significantly improving on prior art.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it's unclear how the techniques would scale to even larger models or different model architectures. Additionally, the impact on other performance metrics beyond perplexity, such as latency or throughput, is not explored.
Further research could investigate the generalizability of KVQuant, its computational overhead, and its real-world implications for deploying large language models on resource-constrained devices or in low-latency applications.
Conclusion
The KVQuant method presented in this paper is a significant advancement in enabling efficient inference of large language models with large context windows. By innovating on quantization techniques tailored to the Key-Value cache, the authors have demonstrated a path to substantially reducing the memory footprint of these models without sacrificing quality.
This work has important implications for making powerful language AI systems more accessible and deployable, from research to production. As language models continue to grow in scale and capability, techniques like KVQuant will be crucial for unlocking their full potential across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, Anshumali Shrivastava
0
0
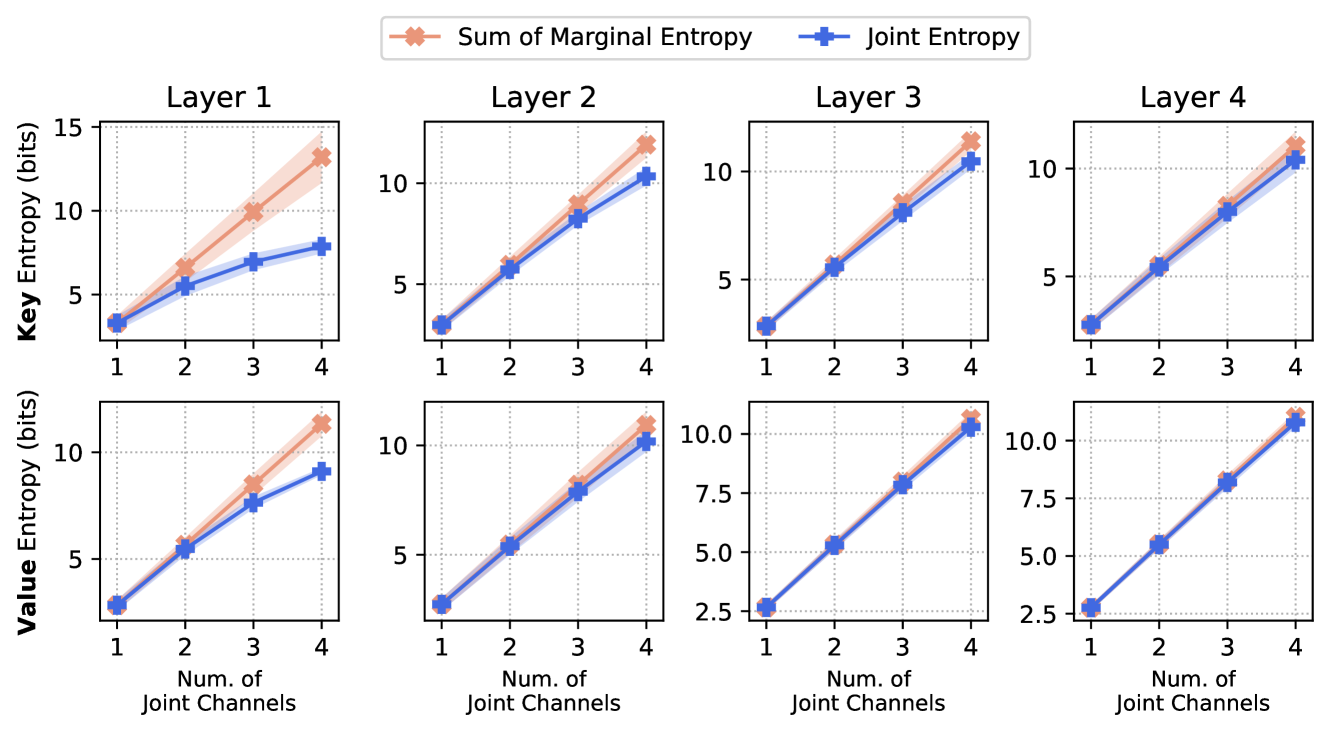
Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As the batch size, context length, or model size increases, the size of the key and value (KV) cache can quickly become the main contributor to GPU memory usage and the bottleneck of inference latency. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. We observe that distinct channels of a key/value activation embedding are highly inter-dependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropies. Based on this insight, we propose Coupled Quantization (CQ), which couples multiple key/value channels together to exploit their inter-dependency and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ outperforms or is competitive with existing baselines in preserving model quality. Furthermore, we demonstrate that CQ can preserve model quality with KV cache quantized down to 1-bit.
5/8/2024
💬
SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, Dahua Lin
0
0
Large language models (LLMs) can now handle longer sequences of tokens, enabling complex tasks like book understanding and generating lengthy novels. However, the key-value (KV) cache required for LLMs consumes substantial memory as context length increasing, becoming the bottleneck for deployment. In this paper, we present a strategy called SKVQ, which stands for sliding-window KV cache quantization, to address the issue of extremely low bitwidth KV cache quantization. To achieve this, SKVQ rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups, and applies clipped dynamic quantization at the group level. Additionally, SKVQ ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache.SKVQ achieves high compression ratios while maintaining accuracy. Our evaluation on LLMs demonstrates that SKVQ surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. With SKVQ, it is possible to process context lengths of up to 1M on an 80GB memory GPU for a 7b model and up to 7 times faster decoding.
5/14/2024
QAQ: Quality Adaptive Quantization for LLM KV Cache
Shichen Dong, Wen Cheng, Jiayu Qin, Wei Wang
0
0
The emergence of LLMs has ignited a fresh surge of breakthroughs in NLP applications, particularly in domains such as question-answering systems and text generation. As the need for longer context grows, a significant bottleneck in model deployment emerges due to the linear expansion of the Key-Value (KV) cache with the context length. Existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. In this paper, we propose QAQ, a Quality Adaptive Quantization scheme for the KV cache. We theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, QAQ achieves up to 10x the compression ratio of the KV cache size with a neglectable impact on model performance. QAQ significantly reduces the practical hurdles of deploying LLMs, opening up new possibilities for longer-context applications. The code is available at github.com/ClubieDong/KVCacheQuantization.
4/15/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024