QAQ: Quality Adaptive Quantization for LLM KV Cache
2403.04643
0
0
Abstract
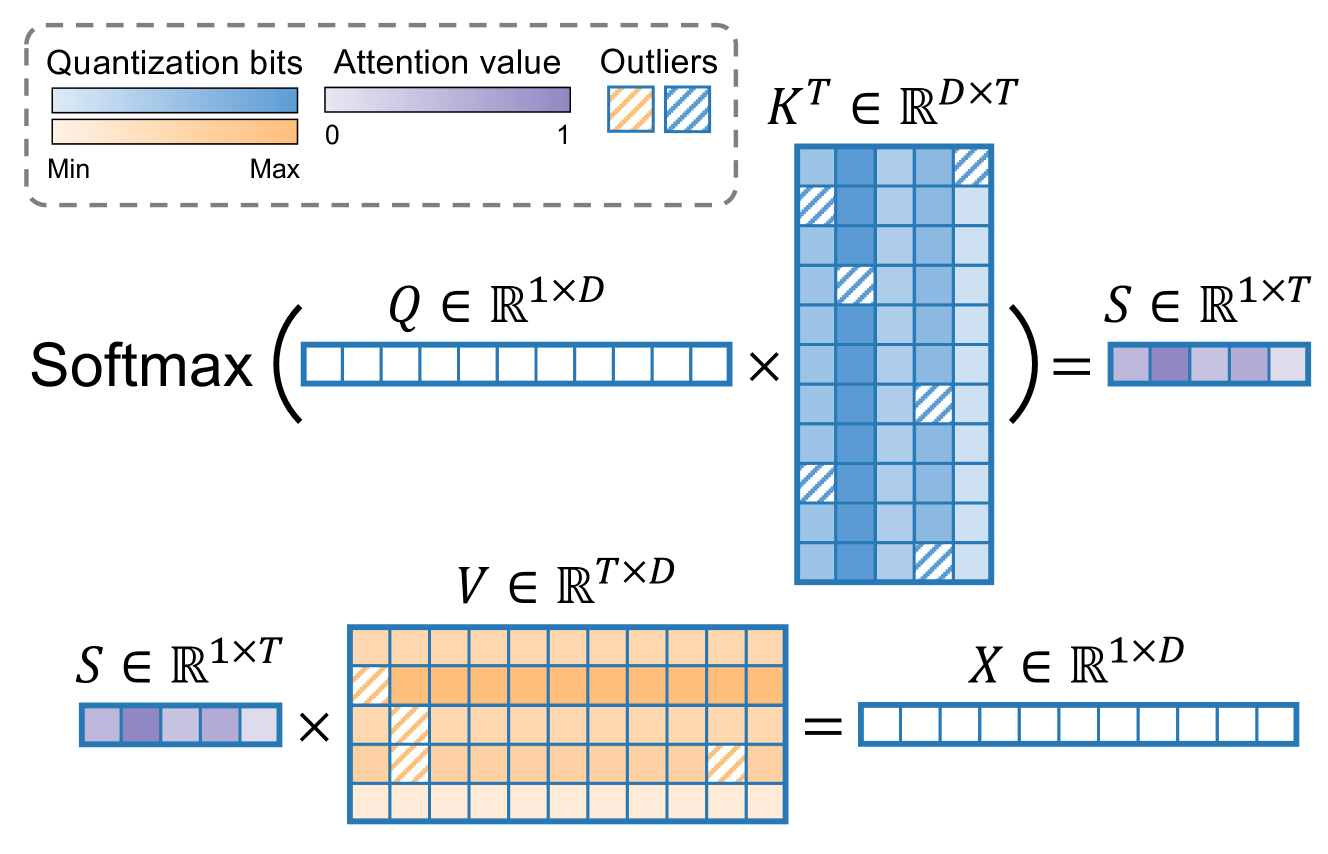
The emergence of LLMs has ignited a fresh surge of breakthroughs in NLP applications, particularly in domains such as question-answering systems and text generation. As the need for longer context grows, a significant bottleneck in model deployment emerges due to the linear expansion of the Key-Value (KV) cache with the context length. Existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. In this paper, we propose QAQ, a Quality Adaptive Quantization scheme for the KV cache. We theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, QAQ achieves up to 10x the compression ratio of the KV cache size with a neglectable impact on model performance. QAQ significantly reduces the practical hurdles of deploying LLMs, opening up new possibilities for longer-context applications. The code is available at github.com/ClubieDong/KVCacheQuantization.
Create account to get full access
Overview
- The paper presents "QAQ", a quality-adaptive quantization technique for improving the efficiency of large language model (LLM) key-value (KV) caches.
- LLM KV caches store key-value pairs used during inference, and quantization can compress these caches to save memory and increase throughput.
- QAQ adapts the quantization level to the importance of each KV pair, preserving high quality for critical pairs while aggressively compressing less important ones.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. To run efficiently, these models rely on a key-value (KV) cache that stores important data used during inference. This paper introduces QAQ, a new technique to compress this KV cache while preserving the model's accuracy.
The key idea behind QAQ is that not all KV pairs in the cache are equally important. Some are critical for the model's performance, while others are less crucial. QAQ adaptively adjusts the level of compression (quantization) applied to each pair based on its importance. High-priority pairs are preserved with high fidelity, while less important ones are compressed more aggressively.
This adaptive approach allows QAQ to dramatically reduce the memory footprint of the KV cache without significantly impacting the model's accuracy. By selectively compressing different parts of the cache, QAQ can strike a better balance between efficiency and quality compared to uniform compression techniques.
Technical Explanation
The paper first describes the problem of efficiently storing and accessing the large KV caches used by modern LLMs. Quantization is a common approach to compress these caches, but existing methods apply the same level of compression to all KV pairs, which can degrade model performance.
To address this, the authors propose QAQ, a quality-adaptive quantization technique. QAQ first analyzes the importance of each KV pair using a lightweight importance estimator. It then applies varying levels of quantization to each pair based on its estimated importance. Critical pairs are preserved with high fidelity, while less important pairs are more aggressively compressed.
The authors evaluate QAQ on several large language models, including GPT-3 and Chinchilla. They show that QAQ can reduce the KV cache size by up to 4.5x while maintaining the same model accuracy as uncompressed baselines. This allows for significantly higher throughput during inference.
Critical Analysis
The paper provides a thorough evaluation of QAQ, demonstrating its effectiveness across multiple LLM architectures and datasets. However, the authors acknowledge that the importance estimation used by QAQ relies on heuristics and could be further improved.
Additionally, the paper does not explore the potential impact of QAQ on other aspects of LLM performance, such as latency or energy consumption. While the focus is on memory efficiency and throughput, it would be valuable to understand how QAQ affects the overall system-level trade-offs.
Finally, the authors mention that QAQ could be combined with other KV cache optimization techniques, such as SqueezeCube or Cherry-Top, to further enhance efficiency. Exploring these synergies could be a fruitful area for future research.
Conclusion
The QAQ technique presented in this paper offers a promising approach to improving the efficiency of LLM KV caches. By adaptively adjusting the level of quantization applied to each KV pair based on its importance, QAQ can significantly reduce memory usage and increase throughput without compromising model accuracy.
This work contributes to the ongoing efforts to make large language models more efficient and accessible, which is crucial as these models continue to grow in size and complexity. The insights from this paper could inspire further research into adaptive compression techniques and the optimization of LLM inference systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, Dahua Lin
0
0
Large language models (LLMs) can now handle longer sequences of tokens, enabling complex tasks like book understanding and generating lengthy novels. However, the key-value (KV) cache required for LLMs consumes substantial memory as context length increasing, becoming the bottleneck for deployment. In this paper, we present a strategy called SKVQ, which stands for sliding-window KV cache quantization, to address the issue of extremely low bitwidth KV cache quantization. To achieve this, SKVQ rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups, and applies clipped dynamic quantization at the group level. Additionally, SKVQ ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache.SKVQ achieves high compression ratios while maintaining accuracy. Our evaluation on LLMs demonstrates that SKVQ surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. With SKVQ, it is possible to process context lengths of up to 1M on an 80GB memory GPU for a 7b model and up to 7 times faster decoding.
5/14/2024
🤯
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, Amir Gholami
0
0
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
4/5/2024
KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, Anshumali Shrivastava
0
0
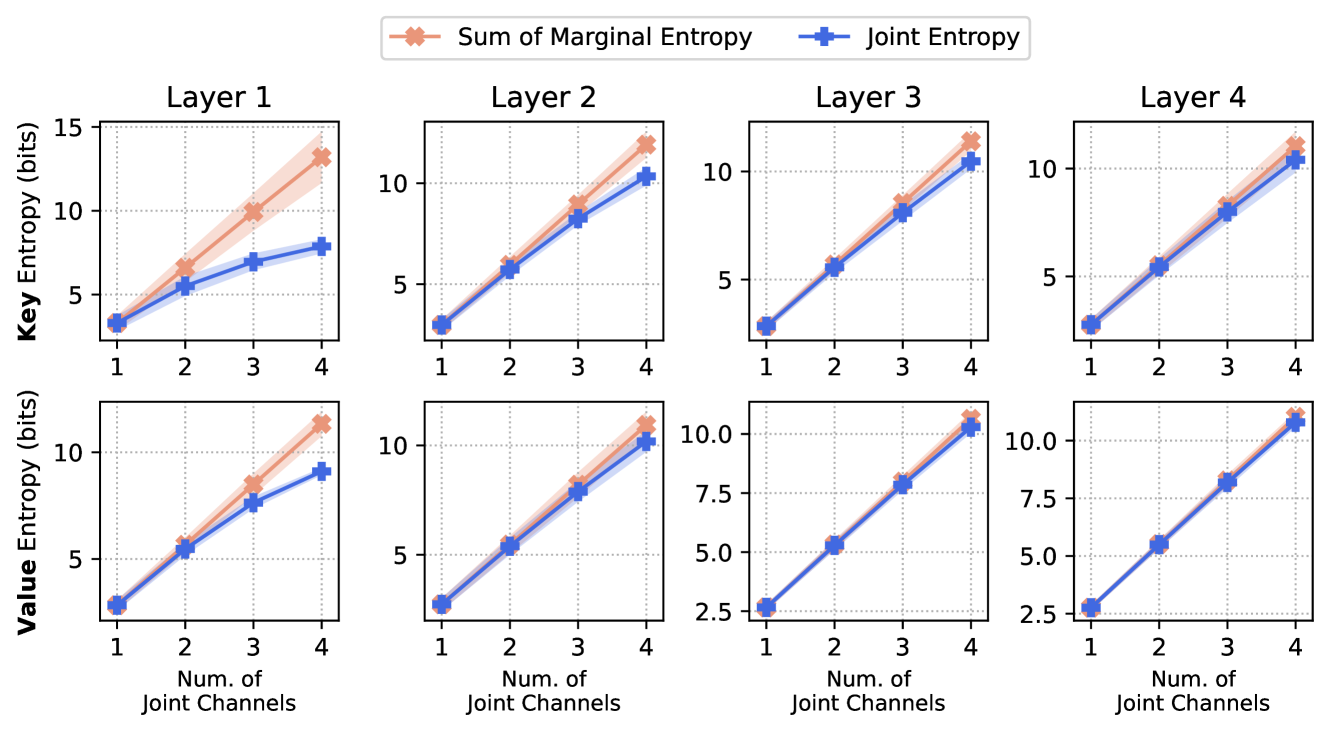
Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As the batch size, context length, or model size increases, the size of the key and value (KV) cache can quickly become the main contributor to GPU memory usage and the bottleneck of inference latency. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. We observe that distinct channels of a key/value activation embedding are highly inter-dependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropies. Based on this insight, we propose Coupled Quantization (CQ), which couples multiple key/value channels together to exploit their inter-dependency and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ outperforms or is competitive with existing baselines in preserving model quality. Furthermore, we demonstrate that CQ can preserve model quality with KV cache quantized down to 1-bit.
5/8/2024
QCQA: Quality and Capacity-aware grouped Query Attention
Vinay Joshi, Prashant Laddha, Shambhavi Sinha, Om Ji Omer, Sreenivas Subramoney
0
0
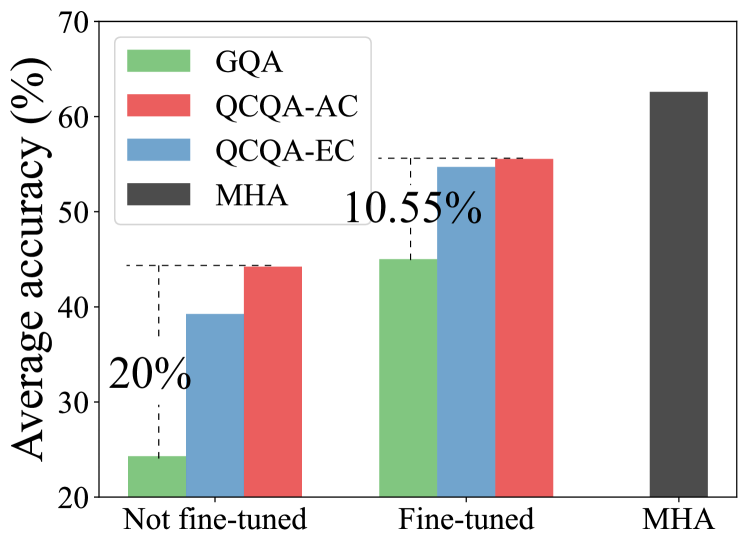
Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7,$B model, QCQA achieves $mathbf{20}$% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $mathbf{10.55},$% higher accuracy than GQA. Furthermore, QCQA requires $40,$% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
6/18/2024