Label-efficient Time Series Representation Learning: A Review

0
👨🏫
Sign in to get full access
Overview
- Time series representation learning aims to learn effective representations with limited labeled data
- This is crucial for deploying deep learning models in real-world applications
- To address the scarcity of labeled time series data, various strategies have been developed
Plain English Explanation
Time series data is information that changes over time, like stock prices or weather patterns. [object Object] is a powerful technique for analyzing time series data, but it requires a lot of labeled data to work well. This can be a problem in the real world, where labeled data is often scarce.
To solve this, researchers have developed several strategies, including [object Object], [object Object], and [object Object]. These approaches aim to learn effective representations of time series data using limited labeled data.
The researchers in this paper introduce a new way to categorize these different strategies. They divide them into two groups: "in-domain" approaches that only use data from the same field, and "cross-domain" approaches that use data from other fields as well. This helps us better understand the strengths and weaknesses of each approach.
Technical Explanation
The paper presents a novel taxonomy for categorizing existing [object Object] approaches. They divide them into two main groups:
- In-domain: These approaches rely solely on the target time series data, without using any external data sources.
- Cross-domain: These approaches leverage additional data from related domains to improve the representation learning.
The paper then provides a comprehensive review of the recent advances in each strategy, highlighting their key ideas, strengths, and limitations. For example, transfer learning-based methods can leverage pre-trained models from related domains, while self-supervised learning techniques can learn useful representations without labeled data.
The authors also identify several common challenges and limitations in the current methodologies, such as the difficulty of selecting suitable auxiliary tasks or data sources for cross-domain approaches. They suggest future research directions that could lead to further improvements in this field, such as developing more effective ways to integrate multi-modal data or designing more robust self-supervised objectives.
Critical Analysis
The paper provides a valuable taxonomy and review of the current state of time series representation learning, which is an important and active area of research. By categorizing the approaches into in-domain and cross-domain, the authors offer a clear framework for understanding the trade-offs and considerations involved in each strategy.
However, the paper does not delve deeply into the specific strengths and weaknesses of the different techniques within each category. A more nuanced discussion of the pros and cons of transfer learning, self-supervised learning, and semi-supervised learning approaches could have provided additional insights.
Additionally, the paper does not address the potential challenges of deploying these representation learning models in real-world applications, such as the computational and memory requirements, model interpretability, or the need for robust performance in the face of noisy or missing data.
Further research could explore these practical considerations and investigate how to best integrate time series representation learning into end-to-end application-specific models.
Conclusion
This paper presents a comprehensive taxonomy and review of the current state of time series representation learning, a crucial field for deploying deep learning models in real-world applications with limited labeled data. By categorizing the approaches as in-domain or cross-domain, the authors provide a clear framework for understanding the trade-offs and considerations involved in each strategy.
The paper's insights could inform the development of more effective and efficient time series representation learning techniques, ultimately helping to unlock the full potential of deep learning in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Label-efficient Time Series Representation Learning: A Review
Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, Chee-Keong Kwoh, Xiaoli Li
Label-efficient time series representation learning, which aims to learn effective representations with limited labeled data, is crucial for deploying deep learning models in real-world applications. To address the scarcity of labeled time series data, various strategies, e.g., transfer learning, self-supervised learning, and semi-supervised learning, have been developed. In this survey, we introduce a novel taxonomy for the first time, categorizing existing approaches as in-domain or cross-domain, based on their reliance on external data sources or not. Furthermore, we present a review of the recent advances in each strategy, conclude the limitations of current methodologies, and suggest future research directions that promise further improvements in the field.
Read more7/25/2024

0
Universal Time-Series Representation Learning: A Survey
Patara Trirat, Yooju Shin, Junhyeok Kang, Youngeun Nam, Jihye Na, Minyoung Bae, Joeun Kim, Byunghyun Kim, Jae-Gil Lee
Time-series data exists in every corner of real-world systems and services, ranging from satellites in the sky to wearable devices on human bodies. Learning representations by extracting and inferring valuable information from these time series is crucial for understanding the complex dynamics of particular phenomena and enabling informed decisions. With the learned representations, we can perform numerous downstream analyses more effectively. Among several approaches, deep learning has demonstrated remarkable performance in extracting hidden patterns and features from time-series data without manual feature engineering. This survey first presents a novel taxonomy based on three fundamental elements in designing state-of-the-art universal representation learning methods for time series. According to the proposed taxonomy, we comprehensively review existing studies and discuss their intuitions and insights into how these methods enhance the quality of learned representations. Finally, as a guideline for future studies, we summarize commonly used experimental setups and datasets and discuss several promising research directions. An up-to-date corresponding resource is available at https://github.com/itouchz/awesome-deep-time-series-representations.
Read more8/29/2024
0
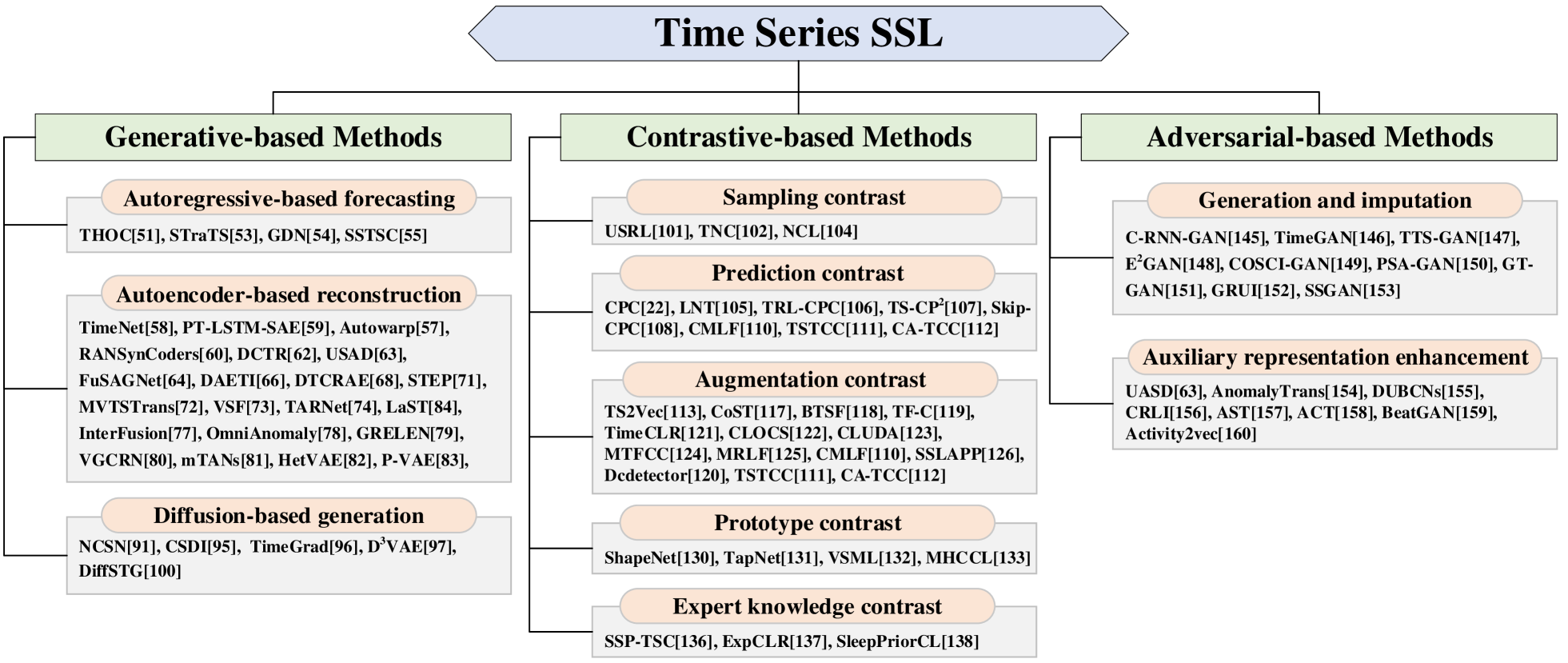
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, Shirui Pan
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods by summarizing them from three perspectives: generative-based, contrastive-based, and adversarial-based. These methods are further divided into ten subcategories with detailed reviews and discussions about their key intuitions, main frameworks, advantages and disadvantages. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
Read more4/9/2024

0
TimeDRL: Disentangled Representation Learning for Multivariate Time-Series
Ching Chang, Chiao-Tung Chan, Wei-Yao Wang, Wen-Chih Peng, Tien-Fu Chen
Multivariate time-series data in numerous real-world applications (e.g., healthcare and industry) are informative but challenging due to the lack of labels and high dimensionality. Recent studies in self-supervised learning have shown their potential in learning rich representations without relying on labels, yet they fall short in learning disentangled embeddings and addressing issues of inductive bias (e.g., transformation-invariance). To tackle these challenges, we propose TimeDRL, a generic multivariate time-series representation learning framework with disentangled dual-level embeddings. TimeDRL is characterized by three novel features: (i) disentangled derivation of timestamp-level and instance-level embeddings from patched time-series data using a [CLS] token strategy; (ii) utilization of timestamp-predictive and instance-contrastive tasks for disentangled representation learning, with the former optimizing timestamp-level embeddings with predictive loss, and the latter optimizing instance-level embeddings with contrastive loss; and (iii) avoidance of augmentation methods to eliminate inductive biases, such as transformation-invariance from cropping and masking. Comprehensive experiments on 6 time-series forecasting datasets and 5 time-series classification datasets have shown that TimeDRL consistently surpasses existing representation learning approaches, achieving an average improvement of forecasting by 58.02% in MSE and classification by 1.48% in accuracy. Furthermore, extensive ablation studies confirmed the relative contribution of each component in TimeDRL's architecture, and semi-supervised learning evaluations demonstrated its effectiveness in real-world scenarios, even with limited labeled data. The code is available at https://github.com/blacksnail789521/TimeDRL.
Read more7/18/2024