Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
2405.08890
0
0
🌀
Abstract
Current video summarization methods primarily depend on supervised computer vision techniques, which demands time-consuming manual annotations. Further, the annotations are always subjective which make this task more challenging. To address these issues, we analyzed the feasibility in transforming the video summarization into a text summary task and leverage Large Language Models (LLMs) to boost video summarization. This paper proposes a novel self-supervised framework for video summarization guided by LLMs. Our method begins by generating captions for video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the frame captions and the text summary. It's worth noting that we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames whose captions are similar with the text summary. Our model achieves competitive results against other state-of-the-art methods and paves a novel pathway in video summarization.
Create account to get full access
Overview
- Current video summarization methods rely on supervised computer vision techniques, which require time-consuming manual annotations that are subjective
- This paper proposes a novel self-supervised framework for video summarization guided by Large Language Models (LLMs)
- The method generates captions for video frames, which are then synthesized into text summaries by LLMs
- The semantic distance between the frame captions and the text summary is used to optimize the model's diversity
Plain English Explanation
This research paper explores a new way to summarize videos using large language models. Instead of relying on detailed annotations made by humans, which can be time-consuming and subjective, the researchers developed a self-supervised approach.
The key idea is to generate captions for each video frame, and then use a large language model to synthesize those captions into a concise text summary. The researchers measure how similar the text summary is to the individual frame captions, and use this information to train the model to produce diverse and representative summaries.
This approach aims to enhance video summarization by leveraging the power of large language models, which have become increasingly adept at understanding and generating natural language. By cross-linking the visual and textual information, the model can create video summaries that capture the key elements without the need for extensive manual labeling.
Technical Explanation
The proposed framework begins by generating captions for each video frame using a pre-trained image captioning model. These frame-level captions are then fed into a large language model, which synthesizes them into a concise text summary.
To optimize the model's performance, the researchers introduce a novel loss function that encourages the generated summary to be diverse and representative of the video's content. Specifically, the loss function measures the semantic distance between the frame captions and the text summary, incentivizing the model to select a summary that captures a wide range of information from the video.
The final video summary is generated by selecting the frames whose captions are most similar to the text summary produced by the language model. This cross-modal approach of combining visual and textual information allows the model to distill the essence of the video into a compact and informative summary.
Critical Analysis
The researchers acknowledge that their approach relies on the quality and accuracy of the pre-trained image captioning model, which could introduce potential biases or errors into the video summarization process. Additionally, the paper does not address the computational complexity of the model, which could be a concern for real-world deployment.
Furthermore, the experiments were conducted on limited datasets, raising questions about the generalizability of the approach to more diverse and challenging video content. The researchers also do not explore the potential for interactive or user-guided video summarization, which could be a valuable direction for future research.
Despite these limitations, the proposed framework represents a promising step towards more efficient and scalable video summarization methods by leveraging the power of large language models. The self-supervised approach and the introduction of a novel loss function are particularly noteworthy contributions that could inspire further research in this area.
Conclusion
This paper presents a novel self-supervised framework for video summarization that leverages large language models to transform the task into a text summarization problem. By generating captions for video frames and then synthesizing them into a concise text summary, the model is able to produce informative and diverse video summaries without relying on time-consuming manual annotations.
The key innovation of this work is the use of a novel loss function that encourages the model to select a summary that captures a wide range of information from the video. This cross-modal approach of combining visual and textual information represents a promising direction for advancing the field of video summarization and could have significant implications for a variety of applications, such as video archiving, content recommendation, and educational resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
0
0
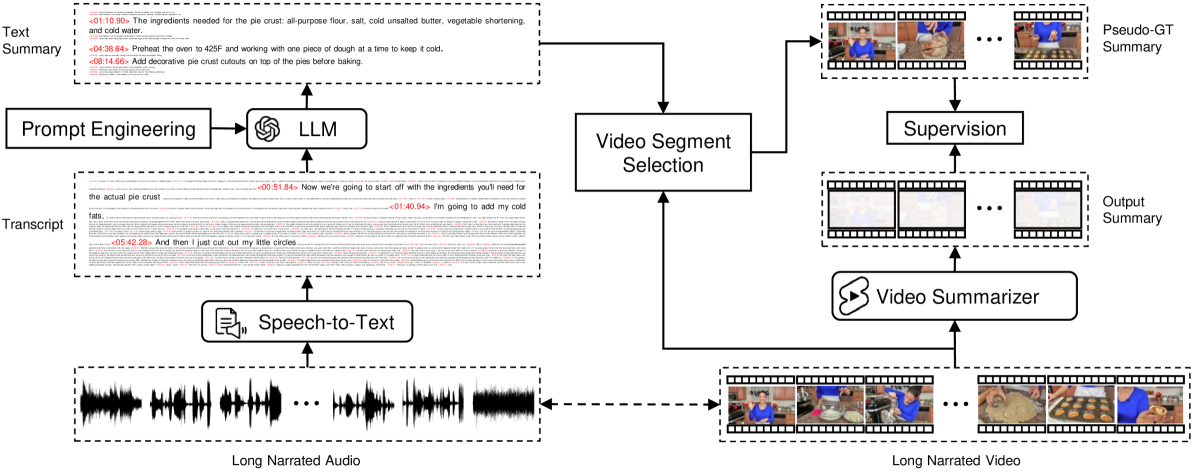
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
4/5/2024
🤿
Enhancing Video Summarization with Context Awareness
Hai-Dang Huynh-Lam, Ngoc-Phuong Ho-Thi, Minh-Triet Tran, Trung-Nghia Le
0
0
Video summarization is a crucial research area that aims to efficiently browse and retrieve relevant information from the vast amount of video content available today. With the exponential growth of multimedia data, the ability to extract meaningful representations from videos has become essential. Video summarization techniques automatically generate concise summaries by selecting keyframes, shots, or segments that capture the video's essence. This process improves the efficiency and accuracy of various applications, including video surveillance, education, entertainment, and social media. Despite the importance of video summarization, there is a lack of diverse and representative datasets, hindering comprehensive evaluation and benchmarking of algorithms. Existing evaluation metrics also fail to fully capture the complexities of video summarization, limiting accurate algorithm assessment and hindering the field's progress. To overcome data scarcity challenges and improve evaluation, we propose an unsupervised approach that leverages video data structure and information for generating informative summaries. By moving away from fixed annotations, our framework can produce representative summaries effectively. Moreover, we introduce an innovative evaluation pipeline tailored specifically for video summarization. Human participants are involved in the evaluation, comparing our generated summaries to ground truth summaries and assessing their informativeness. This human-centric approach provides valuable insights into the effectiveness of our proposed techniques. Experimental results demonstrate that our training-free framework outperforms existing unsupervised approaches and achieves competitive results compared to state-of-the-art supervised methods.
4/9/2024
❗
VideoXum: Cross-modal Visual and Textural Summarization of Videos
Jingyang Lin, Hang Hua, Ming Chen, Yikang Li, Jenhao Hsiao, Chiuman Ho, Jiebo Luo
0
0
Video summarization aims to distill the most important information from a source video to produce either an abridged clip or a textual narrative. Traditionally, different methods have been proposed depending on whether the output is a video or text, thus ignoring the correlation between the two semantically related tasks of visual summarization and textual summarization. We propose a new joint video and text summarization task. The goal is to generate both a shortened video clip along with the corresponding textual summary from a long video, collectively referred to as a cross-modal summary. The generated shortened video clip and text narratives should be semantically well aligned. To this end, we first build a large-scale human-annotated dataset -- VideoXum (X refers to different modalities). The dataset is reannotated based on ActivityNet. After we filter out the videos that do not meet the length requirements, 14,001 long videos remain in our new dataset. Each video in our reannotated dataset has human-annotated video summaries and the corresponding narrative summaries. We then design a novel end-to-end model -- VTSUM-BILP to address the challenges of our proposed task. Moreover, we propose a new metric called VT-CLIPScore to help evaluate the semantic consistency of cross-modality summary. The proposed model achieves promising performance on this new task and establishes a benchmark for future research.
4/24/2024
V2Xum-LLM: Cross-Modal Video Summarization with Temporal Prompt Instruction Tuning
Hang Hua, Yunlong Tang, Chenliang Xu, Jiebo Luo
0
0
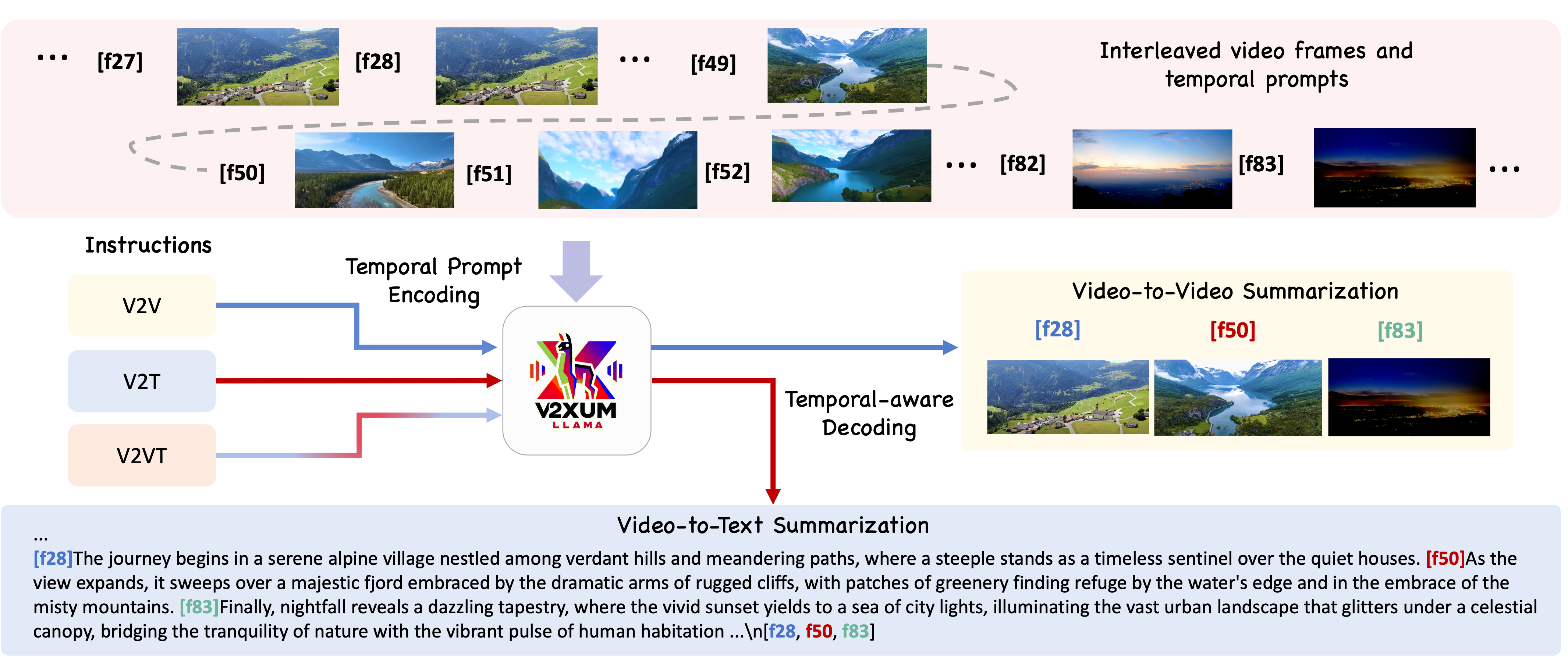
Video summarization aims to create short, accurate, and cohesive summaries of longer videos. Despite the existence of various video summarization datasets, a notable limitation is their limited amount of source videos, which hampers the effective fine-tuning of advanced large vision-language models (VLMs). Additionally, most existing datasets are created for video-to-video summarization, overlooking the contemporary need for multimodal video content summarization. Recent efforts have been made to expand from unimodal to multimodal video summarization, categorizing the task into three sub-tasks based on the summary's modality: video-to-video (V2V), video-to-text (V2T), and a combination of video and text summarization (V2VT). However, the textual summaries in previous multimodal datasets are inadequate. To address these issues, we introduce Instruct-V2Xum, a cross-modal video summarization dataset featuring 30,000 diverse videos sourced from YouTube, with lengths ranging from 40 to 940 seconds and an average summarization ratio of 16.39%. Each video summary in Instruct-V2Xum is paired with a textual summary that references specific frame indexes, facilitating the generation of aligned video and textual summaries. In addition, we propose a new video summarization framework named V2Xum-LLM. V2Xum-LLM, specifically V2Xum-LLaMA in this study, is the first framework that unifies different video summarization tasks into one large language model's (LLM) text decoder and achieves task-controllable video summarization with temporal prompts and task instructions. Experiments show that V2Xum-LLaMA outperforms strong baseline models on multiple video summarization tasks. Furthermore, we propose an enhanced evaluation metric for V2V and V2VT summarization tasks.
4/19/2024