VideoXum: Cross-modal Visual and Textural Summarization of Videos
2303.12060
0
0
❗
Abstract
Video summarization aims to distill the most important information from a source video to produce either an abridged clip or a textual narrative. Traditionally, different methods have been proposed depending on whether the output is a video or text, thus ignoring the correlation between the two semantically related tasks of visual summarization and textual summarization. We propose a new joint video and text summarization task. The goal is to generate both a shortened video clip along with the corresponding textual summary from a long video, collectively referred to as a cross-modal summary. The generated shortened video clip and text narratives should be semantically well aligned. To this end, we first build a large-scale human-annotated dataset -- VideoXum (X refers to different modalities). The dataset is reannotated based on ActivityNet. After we filter out the videos that do not meet the length requirements, 14,001 long videos remain in our new dataset. Each video in our reannotated dataset has human-annotated video summaries and the corresponding narrative summaries. We then design a novel end-to-end model -- VTSUM-BILP to address the challenges of our proposed task. Moreover, we propose a new metric called VT-CLIPScore to help evaluate the semantic consistency of cross-modality summary. The proposed model achieves promising performance on this new task and establishes a benchmark for future research.
Create account to get full access
Overview
- This paper proposes a new task called joint video and text summarization, which aims to generate both a shortened video clip and a corresponding textual summary from a long input video.
- The researchers built a large-scale dataset called VideoXum, which includes human-annotated video and text summaries for over 14,000 videos.
- They developed a novel end-to-end model called VTSUM-BILP to address the challenges of this new task, and introduced a new evaluation metric called VT-CLIPScore to assess the semantic consistency between the video and text summaries.
Plain English Explanation
The goal of video summarization is to take a long video and create a shorter, more concise version that captures the key information. This can be done in different ways - either by producing a shortened video clip or by generating a written summary. However, these two approaches have traditionally been treated as separate tasks, without considering the relationship between the visual and textual summaries.
The researchers in this paper propose a new approach that combines video and text summarization into a single task. The idea is to generate both a shortened video clip and a corresponding textual summary from a longer input video. This "cross-modal summary" should be semantically aligned, meaning the video and text should convey the same key information.
To enable this new task, the researchers first built a large dataset called VideoXum, which includes over 14,000 videos with both human-annotated video summaries and text summaries. This dataset is based on the ActivityNet dataset, with additional curation to meet the length requirements.
The researchers then developed a new end-to-end model called VTSUM-BILP to tackle the joint video and text summarization task. This model learns to generate both the shortened video clip and the textual summary in a unified way, aiming to maintain the semantic consistency between the two outputs.
Additionally, the researchers proposed a new evaluation metric called VT-CLIPScore, which assesses how well the video and text summaries align in terms of their semantic meaning. This metric can be used to measure the performance of models on this new cross-modal summarization task.
Overall, this research introduces an interesting new direction in video summarization, going beyond just producing a shorter video clip or a written summary, and instead trying to generate both in a way that is semantically coherent and well-aligned.
Technical Explanation
The key technical contributions of this paper are:
-
Defining a new cross-modal video summarization task: The researchers propose a new task that goes beyond traditional video or text summarization, and instead aims to generate both a shortened video clip and a corresponding textual summary from a long input video. This "cross-modal summary" should be semantically aligned.
-
Building a large-scale dataset: The researchers created a new dataset called VideoXum, which includes over 14,000 videos with human-annotated video and text summaries. This dataset is based on the ActivityNet dataset, with additional filtering and curation.
-
Developing a new end-to-end model: The researchers proposed a novel model called VTSUM-BILP that can jointly generate the video and text summaries in an end-to-end fashion, aiming to maintain the semantic consistency between the two outputs.
-
Introducing a new evaluation metric: To assess the performance of models on this new cross-modal summarization task, the researchers introduced a metric called VT-CLIPScore, which measures the semantic alignment between the video and text summaries.
The VTSUM-BILP model uses a transformer-based architecture to encode the input video and then generates both the shortened video clip and the textual summary. The model is trained end-to-end using a combination of losses, including a novel "cross-modal consistency" loss that encourages the video and text outputs to be semantically aligned.
The researchers evaluated their model on the VideoXum dataset and showed that it outperforms several baseline approaches, establishing a new benchmark for this cross-modal summarization task. The VT-CLIPScore metric they introduced was also found to be a useful tool for evaluating the semantic consistency between the video and text summaries.
Critical Analysis
The researchers have addressed an interesting and underexplored problem in the field of video summarization. By combining video and text summarization into a single task, they have introduced a novel approach that could have practical applications in areas like video content creation and video understanding.
However, the paper does not fully address some potential limitations and challenges of this new task:
-
Availability of training data: While the VideoXum dataset is a valuable resource, it may not be sufficient to train high-performing models, especially for the cross-modal alignment aspect of the task. Collecting and annotating such large-scale datasets is a significant challenge.
-
Complexity of the task: Generating semantically aligned video and text summaries is a complex challenge, and the researchers acknowledge that their current model does not fully solve the problem. Further research may be needed to develop more advanced techniques for cross-modal understanding and generation.
-
Evaluation and benchmarking: The VT-CLIPScore metric proposed in the paper is a useful step towards evaluating cross-modal consistency, but its limitations and potential biases should be further explored. Developing robust and comprehensive evaluation methods for this task remains an open challenge.
-
Real-world applications: While the researchers mention potential use cases, the paper does not delve into the practical implications and challenges of deploying such a system in real-world scenarios, such as user preferences, computational constraints, and integration with existing workflows.
Overall, this paper presents an interesting new direction in video summarization research and establishes a solid foundation for further exploration. However, there are still numerous challenges and open questions that require deeper investigation to truly unlock the potential of this cross-modal summarization approach.
Conclusion
This paper introduces a novel task of joint video and text summarization, where the goal is to generate both a shortened video clip and a corresponding textual summary from a longer input video. The researchers built a large-scale dataset called VideoXum to enable this new task and developed a novel end-to-end model called VTSUM-BILP to address the challenges.
By combining video and text summarization, this research opens up new avenues for more comprehensive and semantically aligned video understanding and content creation. The proposed VT-CLIPScore metric also represents an important step towards better evaluation of cross-modal consistency in summarization systems.
While this work establishes a promising benchmark, there are still significant challenges to overcome, such as data availability, task complexity, and robust evaluation. Continued research in this direction could lead to advancements in video summarization and broader applications in areas like video retrieval, video editing, and multimedia content analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
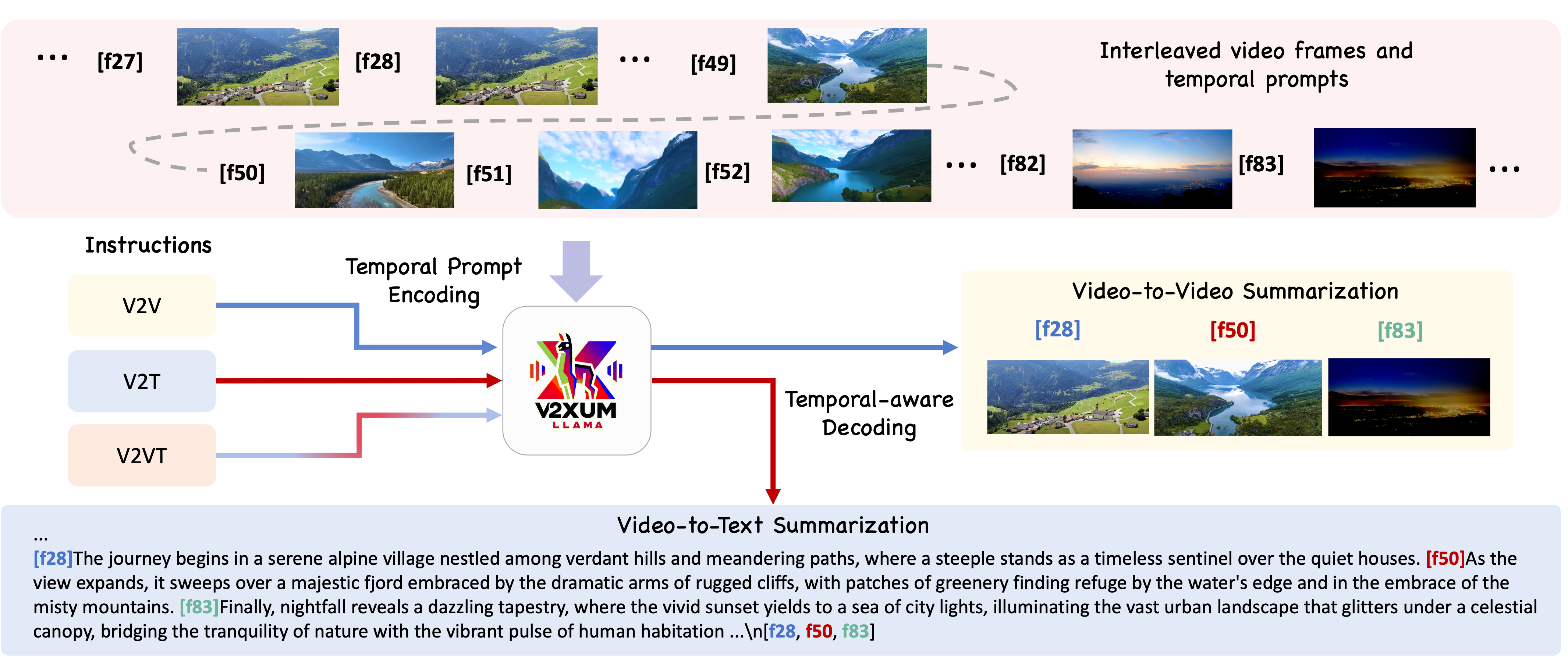
V2Xum-LLM: Cross-Modal Video Summarization with Temporal Prompt Instruction Tuning
Hang Hua, Yunlong Tang, Chenliang Xu, Jiebo Luo
0
0
Video summarization aims to create short, accurate, and cohesive summaries of longer videos. Despite the existence of various video summarization datasets, a notable limitation is their limited amount of source videos, which hampers the effective fine-tuning of advanced large vision-language models (VLMs). Additionally, most existing datasets are created for video-to-video summarization, overlooking the contemporary need for multimodal video content summarization. Recent efforts have been made to expand from unimodal to multimodal video summarization, categorizing the task into three sub-tasks based on the summary's modality: video-to-video (V2V), video-to-text (V2T), and a combination of video and text summarization (V2VT). However, the textual summaries in previous multimodal datasets are inadequate. To address these issues, we introduce Instruct-V2Xum, a cross-modal video summarization dataset featuring 30,000 diverse videos sourced from YouTube, with lengths ranging from 40 to 940 seconds and an average summarization ratio of 16.39%. Each video summary in Instruct-V2Xum is paired with a textual summary that references specific frame indexes, facilitating the generation of aligned video and textual summaries. In addition, we propose a new video summarization framework named V2Xum-LLM. V2Xum-LLM, specifically V2Xum-LLaMA in this study, is the first framework that unifies different video summarization tasks into one large language model's (LLM) text decoder and achieves task-controllable video summarization with temporal prompts and task instructions. Experiments show that V2Xum-LLaMA outperforms strong baseline models on multiple video summarization tasks. Furthermore, we propose an enhanced evaluation metric for V2V and V2VT summarization tasks.
4/19/2024
🌀
Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
Tomoya Sugihara, Shuntaro Masuda, Ling Xiao, Toshihiko Yamasaki
0
0
Current video summarization methods primarily depend on supervised computer vision techniques, which demands time-consuming manual annotations. Further, the annotations are always subjective which make this task more challenging. To address these issues, we analyzed the feasibility in transforming the video summarization into a text summary task and leverage Large Language Models (LLMs) to boost video summarization. This paper proposes a novel self-supervised framework for video summarization guided by LLMs. Our method begins by generating captions for video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the frame captions and the text summary. It's worth noting that we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames whose captions are similar with the text summary. Our model achieves competitive results against other state-of-the-art methods and paves a novel pathway in video summarization.
5/16/2024
🤿
Enhancing Video Summarization with Context Awareness
Hai-Dang Huynh-Lam, Ngoc-Phuong Ho-Thi, Minh-Triet Tran, Trung-Nghia Le
0
0
Video summarization is a crucial research area that aims to efficiently browse and retrieve relevant information from the vast amount of video content available today. With the exponential growth of multimedia data, the ability to extract meaningful representations from videos has become essential. Video summarization techniques automatically generate concise summaries by selecting keyframes, shots, or segments that capture the video's essence. This process improves the efficiency and accuracy of various applications, including video surveillance, education, entertainment, and social media. Despite the importance of video summarization, there is a lack of diverse and representative datasets, hindering comprehensive evaluation and benchmarking of algorithms. Existing evaluation metrics also fail to fully capture the complexities of video summarization, limiting accurate algorithm assessment and hindering the field's progress. To overcome data scarcity challenges and improve evaluation, we propose an unsupervised approach that leverages video data structure and information for generating informative summaries. By moving away from fixed annotations, our framework can produce representative summaries effectively. Moreover, we introduce an innovative evaluation pipeline tailored specifically for video summarization. Human participants are involved in the evaluation, comparing our generated summaries to ground truth summaries and assessing their informativeness. This human-centric approach provides valuable insights into the effectiveness of our proposed techniques. Experimental results demonstrate that our training-free framework outperforms existing unsupervised approaches and achieves competitive results compared to state-of-the-art supervised methods.
4/9/2024

Cross-lingual Cross-temporal Summarization: Dataset, Models, Evaluation
Ran Zhang, Jihed Ouni, Steffen Eger
0
0
While summarization has been extensively researched in natural language processing (NLP), cross-lingual cross-temporal summarization (CLCTS) is a largely unexplored area that has the potential to improve cross-cultural accessibility and understanding. This paper comprehensively addresses the CLCTS task, including dataset creation, modeling, and evaluation. We (1) build the first CLCTS corpus with 328 instances for hDe-En (extended version with 455 instances) and 289 for hEn-De (extended version with 501 instances), leveraging historical fiction texts and Wikipedia summaries in English and German; (2) examine the effectiveness of popular transformer end-to-end models with different intermediate finetuning tasks; (3) explore the potential of GPT-3.5 as a summarizer; (4) report evaluations from humans, GPT-4, and several recent automatic evaluation metrics. Our results indicate that intermediate task finetuned end-to-end models generate bad to moderate quality summaries while GPT-3.5, as a zero-shot summarizer, provides moderate to good quality outputs. GPT-3.5 also seems very adept at normalizing historical text. To assess data contamination in GPT-3.5, we design an adversarial attack scheme in which we find that GPT-3.5 performs slightly worse for unseen source documents compared to seen documents. Moreover, it sometimes hallucinates when the source sentences are inverted against its prior knowledge with a summarization accuracy of 0.67 for plot omission, 0.71 for entity swap, and 0.53 for plot negation. Overall, our regression results of model performances suggest that longer, older, and more complex source texts (all of which are more characteristic for historical language variants) are harder to summarize for all models, indicating the difficulty of the CLCTS task.
6/4/2024