Language-Queried Target Sound Extraction Without Parallel Training Data

0

Sign in to get full access
Overview
- This research paper presents a novel approach for extracting target sounds from audio based on natural language queries, without requiring parallel training data.
- The proposed method leverages a language-queried target sound extraction model that can effectively locate and extract the desired sounds from complex audio mixtures.
- The technique demonstrates strong performance on various benchmark datasets, showcasing its potential for practical applications in areas such as audio editing, sound retrieval, and audio-based assistants.
Plain English Explanation
The paper describes a new way to extract specific sounds from audio recordings using natural language instructions, without needing a large dataset of example sounds paired with their textual descriptions.
Normally, training AI models to do this kind of task would require having many examples of different sounds labeled with their names or descriptions. But the researchers found a way to do it without that type of parallel training data.
Their language-queried target sound extraction model can take a textual description of a sound, like "the sound of a dog barking," and then automatically locate and extract just that specific sound from a complex audio recording. This could be very useful for applications like audio editing, searching for particular sounds in large audio libraries, or building AI assistants that can interact with users through sound.
The key innovation is that the model can learn the connection between language and sound without needing a big dataset of labeled examples. This makes the approach more flexible and practical for real-world use cases.
Technical Explanation
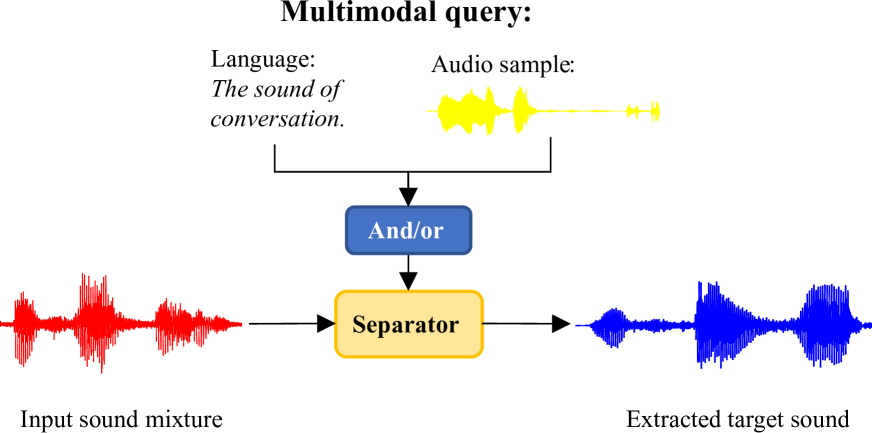
The paper presents a language-queried target sound extraction model that can locate and extract specific target sounds from complex audio mixtures based on natural language descriptions, without requiring parallel training data.
The core of the approach is a neural network architecture that consists of a language encoder and a sound encoder. The language encoder takes the textual query as input and generates a semantic representation. The sound encoder processes the input audio and produces a latent representation of the sound contents.
These two latent representations are then fused and passed through a target sound extraction module that generates a time-frequency mask to isolate the target sound. The model is trained in an end-to-end fashion using only unpaired audio and text data, without needing examples of specific sounds paired with their descriptions.
Experiments on benchmark datasets demonstrate the effectiveness of the proposed method, which outperforms prior work on target sound extraction tasks. The language-queried approach shows strong performance in locating and extracting the target sounds based on the natural language descriptions, even in the presence of background noise and other sound sources.
Critical Analysis
The paper presents a compelling solution for language-queried target sound extraction without requiring parallel training data, which is an important practical limitation in many real-world audio processing applications.
One potential area for further research highlighted in the paper is enhancing the model's ability to handle more complex language queries, such as describing the temporal or spatial characteristics of the target sound. Currently, the approach is limited to relatively simple textual descriptions.
Additionally, the authors acknowledge that the performance of the model may degrade when faced with very challenging audio mixtures or rare sound types not well-represented in the training data. Exploring techniques to improve robustness and generalization could be an important direction for future work.
Overall, the paper makes a significant contribution by demonstrating a novel approach to bridging the gap between language and audio, with promising results that suggest this technology could have widespread applications in the field of audio processing and understanding.
Conclusion
This research paper introduces a language-queried target sound extraction model that can effectively locate and extract specific sounds from complex audio recordings based on natural language descriptions, without requiring parallel training data.
The key innovation is the ability to learn the relationship between language and audio in an unsupervised manner, leveraging only unpaired audio and text data. This makes the approach more flexible and scalable compared to traditional methods that rely on having large datasets of labeled sound examples.
The strong performance demonstrated on benchmark tests suggests this technology could have transformative applications in areas like audio editing, sound retrieval, and conversational AI assistants that interact through sound. As the field of audio understanding continues to advance, techniques like this one will play an increasingly important role in bridging the gap between human language and the auditory world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Language-Queried Target Sound Extraction Without Parallel Training Data
Hao Ma, Zhiyuan Peng, Xu Li, Yukai Li, Mingjie Shao, Qiuqiang Kong, Ju Liu
Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
Read more9/17/2024
0
CLAPSep: Leveraging Contrastive Pre-trained Model for Multi-Modal Query-Conditioned Target Sound Extraction
Hao Ma, Zhiyuan Peng, Xu Li, Mingjie Shao, Xixin Wu, Ju Liu
Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world recordings. This can be achieved by language-queried target sound extraction (TSE), which typically consists of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound accordingly. Existing methods commonly train models from scratch. As a consequence, substantial data and computational resources are required to make the randomly initialized model comprehend sound events and perform separation accordingly. In this paper, we propose to integrate pre-trained models into TSE models to address the above issue. To be specific, we tailor and adapt the powerful contrastive language-audio pre-trained model (CLAP) for USS, denoted as CLAPSep. CLAPSep also accepts flexible user inputs, taking both positive and negative user prompts of uni- and/or multi-modalities for target sound extraction. These key features of CLAPSep can not only enhance the extraction performance but also improve the versatility of its application. We provide extensive experiments on 5 diverse datasets to demonstrate the superior performance and zero- and few-shot generalizability of our proposed CLAPSep with fast training convergence, surpassing previous methods by a significant margin. Full codes and some audio examples are released for reproduction and evaluation.
Read more9/17/2024

0
Bridging Language Gaps in Audio-Text Retrieval
Zhiyong Yan, Heinrich Dinkel, Yongqing Wang, Jizhong Liu, Junbo Zhang, Yujun Wang, Bin Wang
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
Read more6/18/2024

0
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer
Helin Wang, Jiarui Hai, Yen-Ju Lu, Karan Thakkar, Mounya Elhilali, Najim Dehak
In this paper, we introduce SoloAudio, a novel diffusion-based generative model for target sound extraction (TSE). Our approach trains latent diffusion models on audio, replacing the previous U-Net backbone with a skip-connected Transformer that operates on latent features. SoloAudio supports both audio-oriented and language-oriented TSE by utilizing a CLAP model as the feature extractor for target sounds. Furthermore, SoloAudio leverages synthetic audio generated by state-of-the-art text-to-audio models for training, demonstrating strong generalization to out-of-domain data and unseen sound events. We evaluate this approach on the FSD Kaggle 2018 mixture dataset and real data from AudioSet, where SoloAudio achieves the state-of-the-art results on both in-domain and out-of-domain data, and exhibits impressive zero-shot and few-shot capabilities. Source code and demos are released.
Read more9/16/2024