Large Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation

0

Sign in to get full access
Overview
This paper explores the use of large language models (LLMs) as tools for generating biomedical hypotheses. LLMs are sophisticated artificial intelligence systems trained on vast amounts of text data, which can be used to generate human-like text on a wide range of topics. The researchers in this study investigate whether LLMs can be leveraged to propose new ideas and connections in the biomedical domain that could lead to valuable scientific discoveries.
Plain English Explanation
Large language models are powerful AI systems that have been trained on huge amounts of text data from the internet and other sources. These models have become remarkably skilled at understanding and generating human-like text on all kinds of topics. The researchers in this study wanted to see if these LLMs could be used to propose new ideas and theories in the field of biomedicine.
The basic idea is that an LLM, with its broad knowledge and ability to make connections, might be able to come up with hypotheses about things like new drug targets, disease mechanisms, or genomic relationships that human researchers haven't thought of yet. If an LLM can generate promising biomedical hypotheses, it could potentially accelerate scientific discovery and lead to important breakthroughs.
Technical Explanation
The researchers conducted a comprehensive evaluation of several prominent LLMs, including GPT-3, T5, and BART, to assess their capability as biomedical hypothesis generators. They curated a diverse set of biomedical prompts covering topics such as drug repurposing, disease etiology, and gene-disease associations. The models were then tasked with generating hypotheses in response to these prompts.
The researchers developed a multi-stage evaluation framework to assess the quality and novelty of the generated hypotheses. This involved having domain experts review the hypotheses, checking them against existing biomedical knowledge, and evaluating their potential impact. The team also explored methods for fine-tuning the LLMs on biomedical data to enhance their hypothesis generation abilities.
The results of the study indicate that LLMs can indeed be leveraged as effective biomedical hypothesis generators, producing novel and potentially impactful ideas across a range of biomedical domains. The researchers found that fine-tuning the models on domain-specific data further improved their performance in this task.
Critical Analysis
The researchers acknowledge several limitations and areas for further work. For example, they note that the evaluation of hypothesis quality and novelty is inherently subjective, and that more robust and automated methods for assessment may be needed. Additionally, the researchers highlight the importance of carefully validating any hypotheses generated by LLMs before acting upon them, as the models may occasionally produce false or misleading ideas.
Another potential concern is the lack of transparency and explainability in how LLMs arrive at their hypotheses. Without a clear understanding of the underlying reasoning, it may be difficult for domain experts to fully trust and build upon the model's outputs.
Overall, this study represents an important step forward in exploring the use of large language models as tools for accelerating biomedical research. However, further work is needed to address the challenges and limitations identified, and to fully realize the potential of these powerful AI systems in the scientific discovery process.
Conclusion
This research paper demonstrates the promising potential of large language models as biomedical hypothesis generators. By leveraging the broad knowledge and inference capabilities of LLMs, the researchers were able to show that these AI systems can produce novel and potentially impactful ideas across a range of biomedical domains.
While there are still challenges to overcome, such as ensuring the validity and transparency of the generated hypotheses, this study represents an important step forward in the integration of advanced AI techniques into the scientific discovery process. As these technologies continue to develop, they may one day become invaluable tools for accelerating breakthroughs in medicine and other fields of science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation
Biqing Qi, Kaiyan Zhang, Kai Tian, Haoxiang Li, Zhang-Ren Chen, Sihang Zeng, Ermo Hua, Hu Jinfang, Bowen Zhou
The rapid growth of biomedical knowledge has outpaced our ability to efficiently extract insights and generate novel hypotheses. Large language models (LLMs) have emerged as a promising tool to revolutionize knowledge interaction and potentially accelerate biomedical discovery. In this paper, we present a comprehensive evaluation of LLMs as biomedical hypothesis generators. We construct a dataset of background-hypothesis pairs from biomedical literature, carefully partitioned into training, seen, and unseen test sets based on publication date to mitigate data contamination. Using this dataset, we assess the hypothesis generation capabilities of top-tier instructed models in zero-shot, few-shot, and fine-tuning settings. To enhance the exploration of uncertainty, a crucial aspect of scientific discovery, we incorporate tool use and multi-agent interactions in our evaluation framework. Furthermore, we propose four novel metrics grounded in extensive literature review to evaluate the quality of generated hypotheses, considering both LLM-based and human assessments. Our experiments yield two key findings: 1) LLMs can generate novel and validated hypotheses, even when tested on literature unseen during training, and 2) Increasing uncertainty through multi-agent interactions and tool use can facilitate diverse candidate generation and improve zero-shot hypothesis generation performance. However, we also observe that the integration of additional knowledge through few-shot learning and tool use may not always lead to performance gains, highlighting the need for careful consideration of the type and scope of external knowledge incorporated. These findings underscore the potential of LLMs as powerful aids in biomedical hypothesis generation and provide valuable insights to guide further research in this area.
Read more7/16/2024
0
A Survey for Large Language Models in Biomedicine
Chong Wang, Mengyao Li, Junjun He, Zhongruo Wang, Erfan Darzi, Zan Chen, Jin Ye, Tianbin Li, Yanzhou Su, Jing Ke, Kaili Qu, Shuxin Li, Yi Yu, Pietro Li`o, Tianyun Wang, Yu Guang Wang, Yiqing Shen
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.
Read more9/4/2024
💬
0
Large Language Models in Biomedical and Health Informatics: A Review with Bibliometric Analysis
Huizi Yu, Lizhou Fan, Lingyao Li, Jiayan Zhou, Zihui Ma, Lu Xian, Wenyue Hua, Sijia He, Mingyu Jin, Yongfeng Zhang, Ashvin Gandhi, Xin Ma
Large Language Models (LLMs) have rapidly become important tools in Biomedical and Health Informatics (BHI), enabling new ways to analyze data, treat patients, and conduct research. This study aims to provide a comprehensive overview of LLM applications in BHI, highlighting their transformative potential and addressing the associated ethical and practical challenges. We reviewed 1,698 research articles from January 2022 to December 2023, categorizing them by research themes and diagnostic categories. Additionally, we conducted network analysis to map scholarly collaborations and research dynamics. Our findings reveal a substantial increase in the potential applications of LLMs to a variety of BHI tasks, including clinical decision support, patient interaction, and medical document analysis. Notably, LLMs are expected to be instrumental in enhancing the accuracy of diagnostic tools and patient care protocols. The network analysis highlights dense and dynamically evolving collaborations across institutions, underscoring the interdisciplinary nature of LLM research in BHI. A significant trend was the application of LLMs in managing specific disease categories such as mental health and neurological disorders, demonstrating their potential to influence personalized medicine and public health strategies. LLMs hold promising potential to further transform biomedical research and healthcare delivery. While promising, the ethical implications and challenges of model validation call for rigorous scrutiny to optimize their benefits in clinical settings. This survey serves as a resource for stakeholders in healthcare, including researchers, clinicians, and policymakers, to understand the current state and future potential of LLMs in BHI.
Read more7/30/2024
0
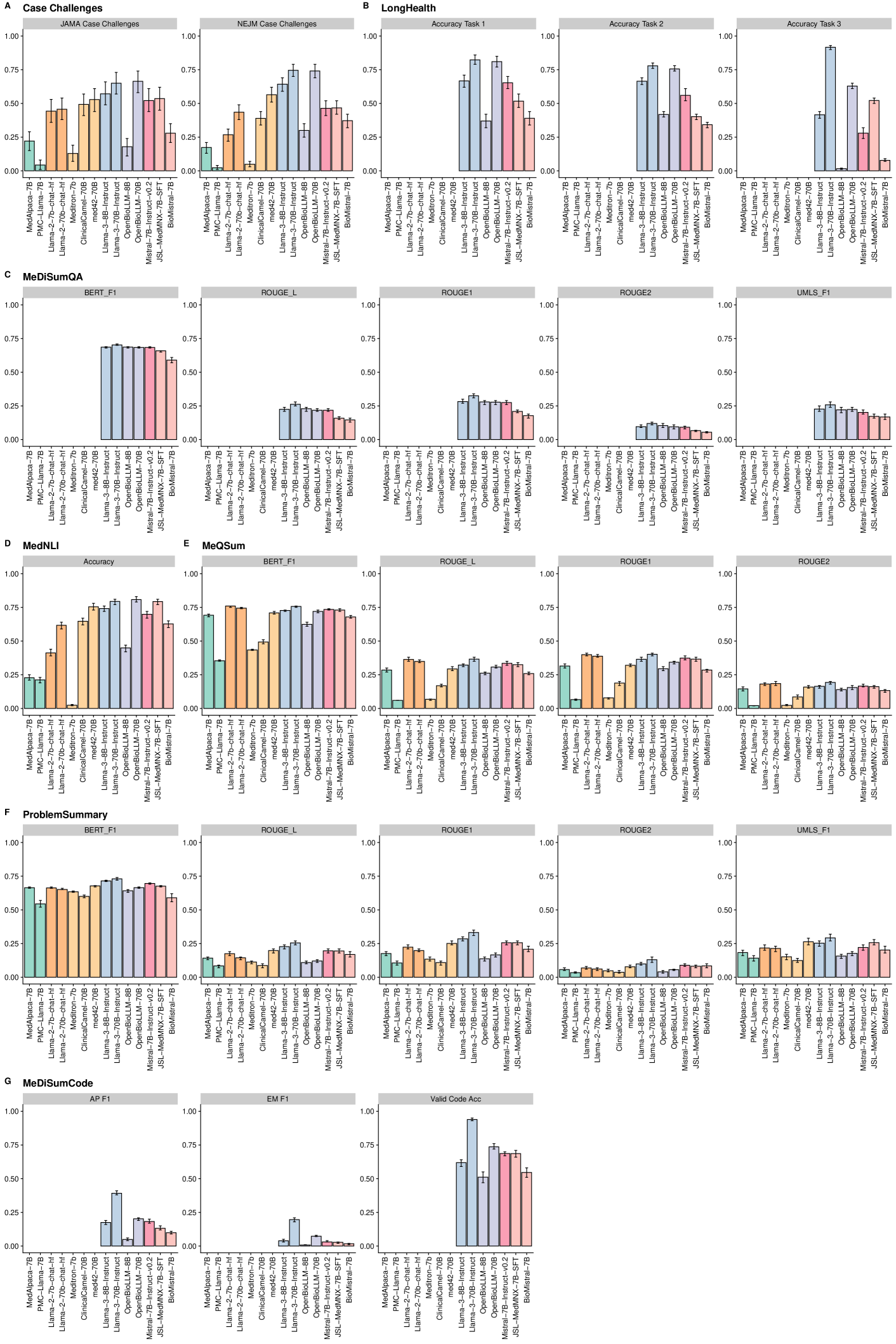
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024