Large language models and linguistic intentionality
2404.09576
0
0
💬
Abstract
Do large language models like Chat-GPT or LLaMa meaningfully use the words they produce? Or are they merely clever prediction machines, simulating language use by producing statistically plausible text? There have already been some initial attempts to answer this question by showing that these models meet the criteria for entering meaningful states according to metasemantic theories of mental content. In this paper, I will argue for a different approach - that we should instead consider whether language models meet the criteria given by our best metasemantic theories of linguistic content. In that vein, I will illustrate how this can be done by applying two such theories to the case of language models: Gareth Evans' (1982) account of naming practices and Ruth Millikan's (1984, 2004, 2005) teleosemantics. In doing so, I will argue that it is a mistake to think that the failure of LLMs to meet plausible conditions for mental intentionality thereby renders their outputs meaningless, and that a distinguishing feature of linguistic intentionality - dependency on a pre-existing linguistic system - allows for the plausible result LLM outputs are meaningful.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores whether large language models (LLMs) like ChatGPT and LLaMa truly understand the words they produce, or if they are simply clever prediction machines generating statistically plausible text.
- The author proposes a different approach, considering whether LLMs meet the criteria given by our best theories of linguistic content, rather than mental intentionality.
- The paper applies two such theories - Gareth Evans' account of naming practices and Ruth Millikan's teleosemantics - to assess the meaningfulness of LLM outputs.
Plain English Explanation
When you chat with large language models like ChatGPT or LLaMa, are they really understanding the words they're producing, or are they just very good at predicting what words should come next based on patterns in language? Some researchers have tried to show that these models meet the requirements for having genuine mental states, but the author of this paper argues for a different approach.
Instead of looking at whether LLMs have meaningful mental states, the author suggests we should consider whether their language outputs meet the criteria for being genuinely meaningful according to our best theories about how language gets its meaning. The paper applies two such theories - one by Gareth Evans about how naming practices work, and another by Ruth Millikan about how the purpose or "function" of language gives it meaning.
By looking at LLMs through the lens of these linguistic theories, the author argues that even if the models don't have the kind of mental intentionality we associate with human understanding, their language outputs can still be considered meaningful in an important sense. The key is that language gets its meaning from being part of a broader system, rather than just being about individuals' mental states.
Technical Explanation
The paper begins by noting that there have been some attempts to show that LLMs like ChatGPT and LLaMa meet the criteria for entering meaningful mental states, according to certain theories of mental content. However, the author proposes a different approach - considering whether these language models meet the conditions for linguistic meaning, as specified by our best theories of linguistic content.
To illustrate this approach, the paper applies two influential theories of linguistic meaning: Gareth Evans' (1982) account of naming practices and Ruth Millikan's (1984, 2004, 2005) teleosemantics. The author argues that even if LLMs fail to meet the requirements for genuine mental intentionality, their language outputs can still be considered meaningful if they satisfy the criteria given by these linguistic theories.
The key idea is that language meaning is fundamentally dependent on a pre-existing linguistic system, rather than just being a matter of individual mental states. By situating LLM outputs within this broader linguistic framework, the author suggests it is possible to provide a plausible account of their meaningfulness, despite the models' lack of human-like mental states.
Critical Analysis
The paper makes a compelling case for considering the meaningfulness of LLM outputs through the lens of linguistic theories, rather than solely focusing on mental intentionality. This approach is valuable, as it acknowledges the unique nature of language as a social and systemic phenomenon, rather than just an individual cognitive capability.
That said, the paper does not fully address the potential limitations or counterarguments to this view. For example, one could argue that while LLMs may satisfy certain criteria for linguistic meaning, there are still crucial differences between their language use and human language use that prevent a complete equivalence. Additionally, the paper does not explore the implications of this view for the broader philosophical debate around the nature of meaning and intentionality.
Further research could delve deeper into these issues, perhaps by examining case studies or edge cases that test the boundaries of the linguistic theories applied in the paper. Additionally, it would be helpful to see a more in-depth discussion of the potential challenges or criticisms that this approach might face, and how the author's arguments could be strengthened to address them.
Conclusion
This paper offers a novel perspective on the longstanding question of whether large language models truly "understand" the language they produce. By shifting the focus from mental intentionality to linguistic meaning, the author presents a compelling case for why LLM outputs can be considered meaningful, even if the models lack human-like mental states.
The application of Gareth Evans' and Ruth Millikan's theories of linguistic content provides a robust framework for evaluating the meaningfulness of LLM language, and the author's arguments suggest that the failure to meet criteria for mental intentionality does not necessarily render these outputs meaningless. This work has important implications for our understanding of language, cognition, and the nature of meaning, and it opens up new avenues for further research in this rapidly evolving field of language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Philosophical Introduction to Language Models - Part II: The Way Forward
Raphael Milli`ere, Cameron Buckner
0
0
In this paper, the second of two companion pieces, we explore novel philosophical questions raised by recent progress in large language models (LLMs) that go beyond the classical debates covered in the first part. We focus particularly on issues related to interpretability, examining evidence from causal intervention methods about the nature of LLMs' internal representations and computations. We also discuss the implications of multimodal and modular extensions of LLMs, recent debates about whether such systems may meet minimal criteria for consciousness, and concerns about secrecy and reproducibility in LLM research. Finally, we discuss whether LLM-like systems may be relevant to modeling aspects of human cognition, if their architectural characteristics and learning scenario are adequately constrained.
5/7/2024

Can large language models understand uncommon meanings of common words?
Jinyang Wu, Feihu Che, Xinxin Zheng, Shuai Zhang, Ruihan Jin, Shuai Nie, Pengpeng Shao, Jianhua Tao
0
0
Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
5/10/2024
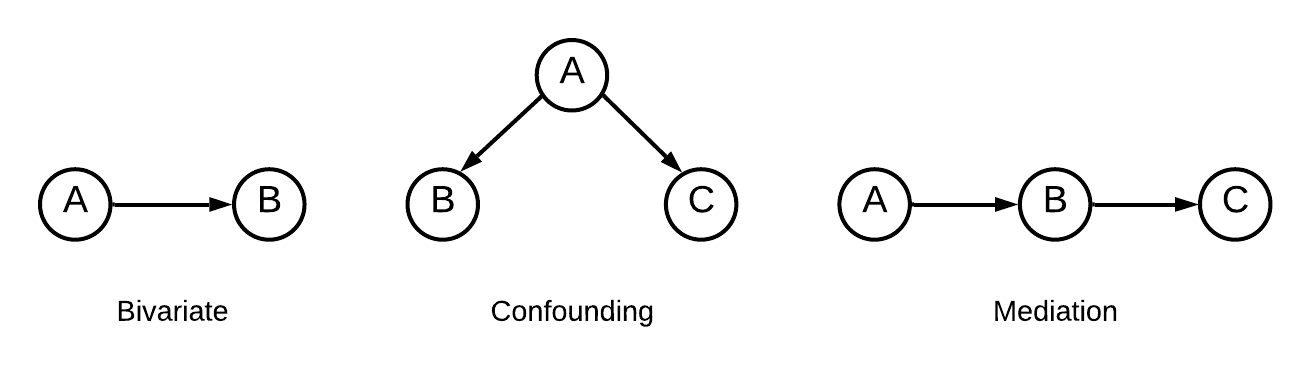
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024
💬
On the Computation of Meaning, Language Models and Incomprehensible Horrors
Michael Timothy Bennett
0
0
We integrate foundational theories of meaning with a mathematical formalism of artificial general intelligence (AGI) to offer a comprehensive mechanistic explanation of meaning, communication, and symbol emergence. This synthesis holds significance for both AGI and broader debates concerning the nature of language, as it unifies pragmatics, logical truth conditional semantics, Peircean semiotics, and a computable model of enactive cognition, addressing phenomena that have traditionally evaded mechanistic explanation. By examining the conditions under which a machine can generate meaningful utterances or comprehend human meaning, we establish that the current generation of language models do not possess the same understanding of meaning as humans nor intend any meaning that we might attribute to their responses. To address this, we propose simulating human feelings and optimising models to construct weak representations. Our findings shed light on the relationship between meaning and intelligence, and how we can build machines that comprehend and intend meaning.
4/12/2024