Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach for large-vocabulary forensic pathological analyses using prototypical cross-modal contrastive learning.
- The method leverages the complementary nature of visual and textual data to enhance the performance of pathological analysis tasks.
- It introduces a prototypical cross-modal contrastive learning framework that learns robust visual and textual representations for improved performance on downstream tasks.
Plain English Explanation
The researchers developed a new technique for analyzing forensic pathological data using both visual and textual information. Pathological analysis is the study of diseases and injuries, which is important in forensics.
The approach takes advantage of the fact that pathological data often includes both images (e.g., microscopic tissue samples) and text (e.g., medical reports). By jointly learning from these two modalities, the model can build a more comprehensive understanding of the pathological data and perform analyses more effectively.
Specifically, the researchers used a prototypical learning approach, which involves identifying representative "prototypes" for each category of pathological data. These prototypes serve as reference points that the model can use to classify new data. Additionally, the cross-modal contrastive learning aspect of the framework ensures that the visual and textual representations learned by the model are well-aligned, further enhancing its performance.
Technical Explanation
The proposed framework consists of two main components: a visual encoder and a textual encoder. The visual encoder takes in pathological images and learns robust visual representations, while the textual encoder processes associated textual data (e.g., medical reports) and learns corresponding textual representations.
The key innovation of this work is the prototypical cross-modal contrastive learning approach. During training, the model learns to identify prototypical visual and textual representations for each class of pathological data. These prototypes serve as reference points that the model can use to classify new data.
Additionally, the cross-modal contrastive learning component ensures that the visual and textual representations learned by the model are well-aligned, allowing for effective multimodal reasoning and improved performance on downstream tasks.
Critical Analysis
The paper presents a promising approach for leveraging the complementary nature of visual and textual data in the context of forensic pathological analyses. By incorporating prototypical learning and cross-modal contrastive learning, the model is able to build robust and well-aligned representations, leading to improved performance on a range of pathological analysis tasks.
However, the paper does not address the potential challenges of working with large-vocabulary forensic data, such as the presence of rare or domain-specific terminology, or the difficulty of obtaining labeled training data. Additionally, the paper does not provide a comprehensive evaluation of the model's performance across a diverse set of pathological analysis tasks.
Further research could explore ways to enhance the model's robustness to handle the complexities of forensic pathological data, as well as investigate the model's generalizability to a wider range of applications.
Conclusion
This paper presents a novel approach for large-vocabulary forensic pathological analyses using prototypical cross-modal contrastive learning. By jointly learning from visual and textual data, the model is able to build robust and well-aligned representations that can be effectively used for a variety of pathological analysis tasks.
While the paper demonstrates promising results, further research is needed to address the challenges of working with large-vocabulary forensic data and to evaluate the model's performance across a more diverse set of applications. Overall, this work represents an important step forward in the field of computational pathology and has the potential to significantly enhance the capabilities of forensic analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning
Chen Shen, Chunfeng Lian, Wanqing Zhang, Fan Wang, Jianhua Zhang, Shuanliang Fan, Xin Wei, Gongji Wang, Kehan Li, Hongshu Mu, Hao Wu, Xinggong Liang, Jianhua Ma, Zhenyuan Wang
Forensic pathology is critical in determining the cause and manner of death through post-mortem examinations, both macroscopic and microscopic. The field, however, grapples with issues such as outcome variability, laborious processes, and a scarcity of trained professionals. This paper presents SongCi, an innovative visual-language model (VLM) designed specifically for forensic pathology. SongCi utilizes advanced prototypical cross-modal self-supervised contrastive learning to enhance the accuracy, efficiency, and generalizability of forensic analyses. It was pre-trained and evaluated on a comprehensive multi-center dataset, which includes over 16 million high-resolution image patches, 2,228 vision-language pairs of post-mortem whole slide images (WSIs), and corresponding gross key findings, along with 471 distinct diagnostic outcomes. Our findings indicate that SongCi surpasses existing multi-modal AI models in many forensic pathology tasks, performs comparably to experienced forensic pathologists and significantly better than less experienced ones, and provides detailed multi-modal explainability, offering critical assistance in forensic investigations. To the best of our knowledge, SongCi is the first VLM specifically developed for forensic pathological analysis and the first large-vocabulary computational pathology (CPath) model that directly processes gigapixel WSIs in forensic science.
Read more7/23/2024
0
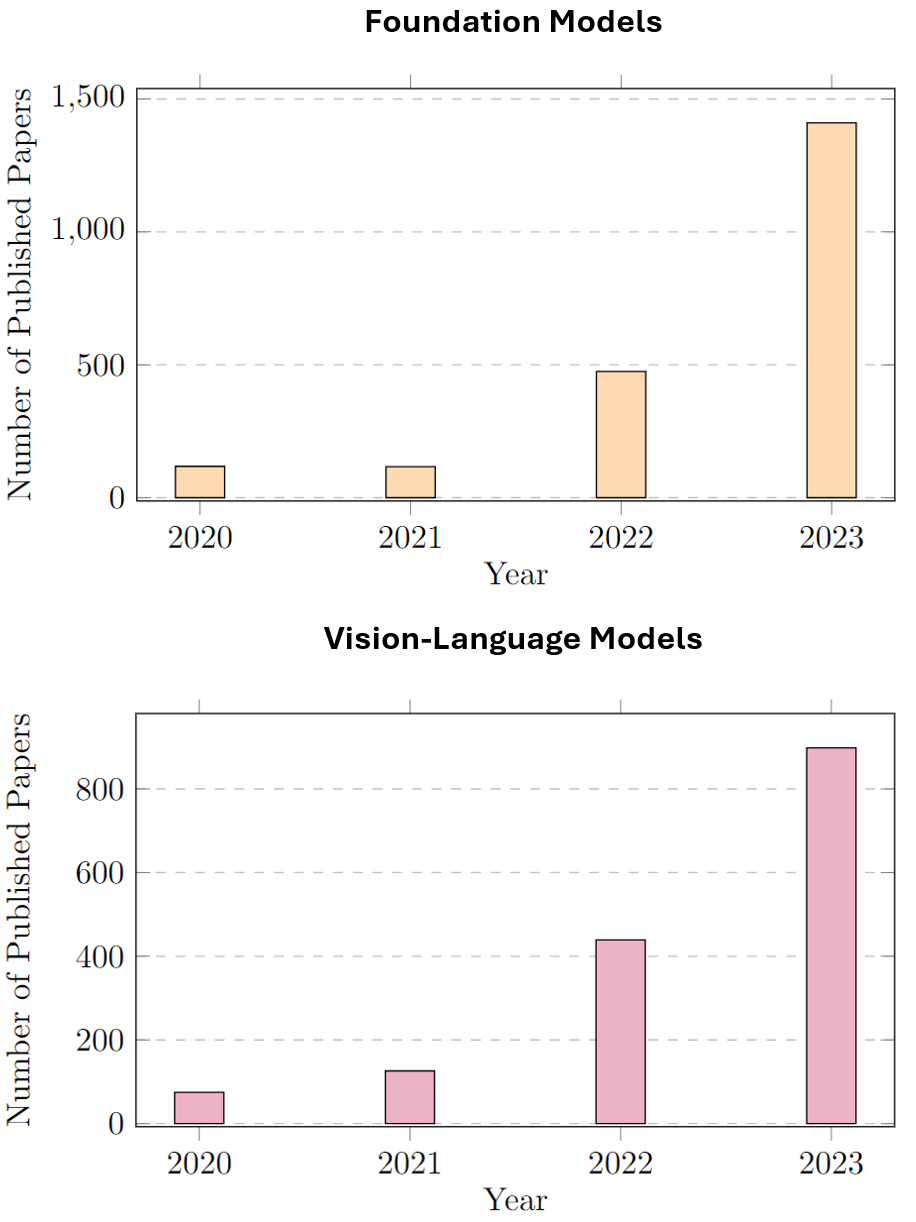
A New Era in Computational Pathology: A Survey on Foundation and Vision-Language Models
Dibaloke Chanda, Milan Aryal, Nasim Yahya Soltani, Masoud Ganji
Recent advances in deep learning have completely transformed the domain of computational pathology (CPath), which in turn altered the diagnostic workflow of pathologists by integrating foundation models (FMs) and vision-language models (VLMs) in their assessment and decision-making process. FMs overcome the limitations of existing deep learning approaches in CPath by learning a representation space that can be adapted to a wide variety of downstream tasks without explicit supervision. VLMs allow pathology reports written in natural language to be used as a rich semantic information source to improve existing models as well as generate predictions in natural language form. In this survey, a holistic and systematic overview of recent innovations in FMs and VLMs in CPath is presented. Furthermore, the tools, datasets and training schemes for these models are summarized in addition to categorizing them into distinct groups. This extensive survey highlights the current trends in CPath and the way it is going to be transformed through FMs and VLMs in the future.
Read more8/28/2024

0
PathInsight: Instruction Tuning of Multimodal Datasets and Models for Intelligence Assisted Diagnosis in Histopathology
Xiaomin Wu, Rui Xu, Pengchen Wei, Wenkang Qin, Peixiang Huang, Ziheng Li, Lin Luo
Pathological diagnosis remains the definitive standard for identifying tumors. The rise of multimodal large models has simplified the process of integrating image analysis with textual descriptions. Despite this advancement, the substantial costs associated with training and deploying these complex multimodal models, together with a scarcity of high-quality training datasets, create a significant divide between cutting-edge technology and its application in the clinical setting. We had meticulously compiled a dataset of approximately 45,000 cases, covering over 6 different tasks, including the classification of organ tissues, generating pathology report descriptions, and addressing pathology-related questions and answers. We have fine-tuned multimodal large models, specifically LLaVA, Qwen-VL, InternLM, with this dataset to enhance instruction-based performance. We conducted a qualitative assessment of the capabilities of the base model and the fine-tuned model in performing image captioning and classification tasks on the specific dataset. The evaluation results demonstrate that the fine-tuned model exhibits proficiency in addressing typical pathological questions. We hope that by making both our models and datasets publicly available, they can be valuable to the medical and research communities.
Read more8/14/2024

0
Knowledge-enhanced Visual-Language Pretraining for Computational Pathology
Xiao Zhou, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Weidi Xie, Yanfeng Wang
In this paper, we consider the problem of visual representation learning for computational pathology, by exploiting large-scale image-text pairs gathered from public resources, along with the domain specific knowledge in pathology. Specifically, we make the following contributions: (i) We curate a pathology knowledge tree that consists of 50,470 informative attributes for 4,718 diseases requiring pathology diagnosis from 32 human tissues. To our knowledge, this is the first comprehensive structured pathology knowledge base; (ii) We develop a knowledge-enhanced visual-language pretraining approach, where we first project pathology-specific knowledge into latent embedding space via language model, and use it to guide the visual representation learning; (iii) We conduct thorough experiments to validate the effectiveness of our proposed components, demonstrating significant performance improvement on various downstream tasks, including cross-modal retrieval, zero-shot classification on pathology patches, and zero-shot tumor subtyping on whole slide images (WSIs). All codes, models and the pathology knowledge tree will be released to the research community
Read more4/16/2024