LASERS: LAtent Space Encoding for Representations with Sparsity for Generative Modeling

0

Sign in to get full access
Overview
- LASERS is a new latent space encoding method for generative modeling that encourages sparse representations.
- It aims to overcome limitations of existing approaches and produce more efficient and flexible generative models.
- The key ideas include a sparsity-inducing regularizer and a dynamic latent space that adapts during training.
Plain English Explanation
LASERS is a new technique for training generative models - models that can create new data like images or text. The main goal of LASERS is to find a more efficient and flexible way to represent the latent space, which is the internal representation the model learns.
Existing methods for representing the latent space often produce dense or redundant representations, which can make the models less effective. LASERS addresses this by encouraging the model to learn a sparse latent representation - one where only a few of the latent variables are used to represent each data point.
The key innovations in LASERS include:
- A sparsity-inducing regularizer that pushes the model to use as few latent variables as possible to represent the data.
- A dynamic latent space that can adapt and change in size during training, allowing the model to find the most efficient representation.
By using these techniques, LASERS aims to produce generative models that are more compact, efficient, and flexible than existing approaches. This could lead to benefits like faster inference, easier interpretability, and the ability to handle more complex data.
Technical Explanation
LASERS introduces a new approach for learning the latent space of generative models, with the goal of producing sparse and efficient representations.
The core technical ideas include:
-
Sparsity-Inducing Regularizer: LASERS adds a regularization term to the training objective that encourages the latent representations to be sparse - i.e. to use as few latent variables as possible to encode each data point. This is achieved through a combination of L1 and group sparsity regularization.
-
Dynamic Latent Space: Rather than fixing the size of the latent space a priori, LASERS allows the size to adapt and change dynamically during training. This is done by introducing "inactive" latent variables that can be pruned away if they are not needed to represent the data.
-
Amortized Inference: LASERS uses an amortized inference network to map data samples to their latent representations, allowing efficient inference at test time.
The authors evaluate LASERS on several generative modeling tasks, including image synthesis and text generation. They show that LASERS can produce models with sparser and more efficient latent representations compared to baselines, without sacrificing performance.
Critical Analysis
The LASERS paper presents a well-designed and technically sound approach for improving the efficiency of generative models through a novel latent space encoding technique. A few potential limitations and areas for further research include:
-
Applicability to More Complex Data: While the paper demonstrates the effectiveness of LASERS on relatively simple datasets like MNIST and text corpora, it remains to be seen how well the approach would scale to more complex, high-dimensional data like natural images or videos.
-
Interpretability of Sparse Representations: While the sparsity of the latent representations is presented as a feature, the authors do not deeply explore the interpretability or "disentanglement" of the learned latent variables. Further research could investigate the semantic meaningfulness of the sparse encodings.
-
Comparison to Other Sparsity-Inducing Methods: The paper compares LASERS to standard VAE baselines, but does not provide a detailed comparison to other techniques for encouraging sparsity in latent representations, such as Compressing Latent Spaces or Latent Space Imaging. A more extensive comparison could help situate LASERS within the broader landscape of latent space compression methods.
Overall, LASERS represents an interesting and promising approach for improving the efficiency of generative models, and the paper provides a solid technical foundation for further research in this area.
Conclusion
LASERS is a new latent space encoding method for generative modeling that aims to produce sparse and efficient representations. By introducing a sparsity-inducing regularizer and a dynamic latent space, LASERS overcomes limitations of existing approaches and demonstrates improved performance on several generative tasks.
The key innovations of LASERS, including its sparsity-promoting objective and adaptive latent space, could have significant implications for the development of more compact, interpretable, and flexible generative models. Further research exploring the scalability, interpretability, and broader applicability of the LASERS technique would be valuable contributions to the field of generative modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!LASERS: LAtent Space Encoding for Representations with Sparsity for Generative Modeling
Xin Li, Anand Sarwate
Learning compact and meaningful latent space representations has been shown to be very useful in generative modeling tasks for visual data. One particular example is applying Vector Quantization (VQ) in variational autoencoders (VQ-VAEs, VQ-GANs, etc.), which has demonstrated state-of-the-art performance in many modern generative modeling applications. Quantizing the latent space has been justified by the assumption that the data themselves are inherently discrete in the latent space (like pixel values). In this paper, we propose an alternative representation of the latent space by relaxing the structural assumption than the VQ formulation. Specifically, we assume that the latent space can be approximated by a union of subspaces model corresponding to a dictionary-based representation under a sparsity constraint. The dictionary is learned/updated during the training process. We apply this approach to look at two models: Dictionary Learning Variational Autoencoders (DL-VAEs) and DL-VAEs with Generative Adversarial Networks (DL-GANs). We show empirically that our more latent space is more expressive and has leads to better representations than the VQ approach in terms of reconstruction quality at the expense of a small computational overhead for the latent space computation. Our results thus suggest that the true benefit of the VQ approach might not be from discretization of the latent space, but rather the lossy compression of the latent space. We confirm this hypothesis by showing that our sparse representations also address the codebook collapse issue as found common in VQ-family models.
Read more9/18/2024

0
Robustly overfitting latents for flexible neural image compression
Yura Perugachi-Diaz, Arwin Gansekoele, Sandjai Bhulai
Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. We show how our method improves the overall compression performance in terms of the R-D trade-off, compared to its predecessors. Additionally, we show how refinement of the latents with our best-performing method improves the compression performance on both the Tecnick and CLIC dataset. Our method is deployed for a pre-trained hyperprior and for a more flexible model. Further, we give a detailed analysis of our proposed methods and show that they are less sensitive to hyperparameter choices. Finally, we show how each method can be extended to three- instead of two-class rounding.
Read more5/27/2024

0
Variational autoencoder-based neural network model compression
Liang Cheng, Peiyuan Guan, Amir Taherkordi, Lei Liu, Dapeng Lan
Variational Autoencoders (VAEs), as a form of deep generative model, have been widely used in recent years, and shown great great peformance in a number of different domains, including image generation and anomaly detection, etc.. This paper aims to explore neural network model compression method based on VAE. The experiment uses different neural network models for MNIST recognition as compression targets, including Feedforward Neural Network (FNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM). These models are the most basic models in deep learning, and other more complex and advanced models are based on them or inherit their features and evolve. In the experiment, the first step is to train the models mentioned above, each trained model will have different accuracy and number of total parameters. And then the variants of parameters for each model are processed as training data in VAEs separately, and the trained VAEs are tested by the true model parameters. The experimental results show that using the latent space as a representation of the model compression can improve the compression rate compared to some traditional methods such as pruning and quantization, meanwhile the accuracy is not greatly affected using the model parameters reconstructed based on the latent space. In the future, a variety of different large-scale deep learning models will be used more widely, so exploring different ways to save time and space on saving or transferring models will become necessary, and the use of VAE in this paper can provide a basis for these further explorations.
Read more8/28/2024
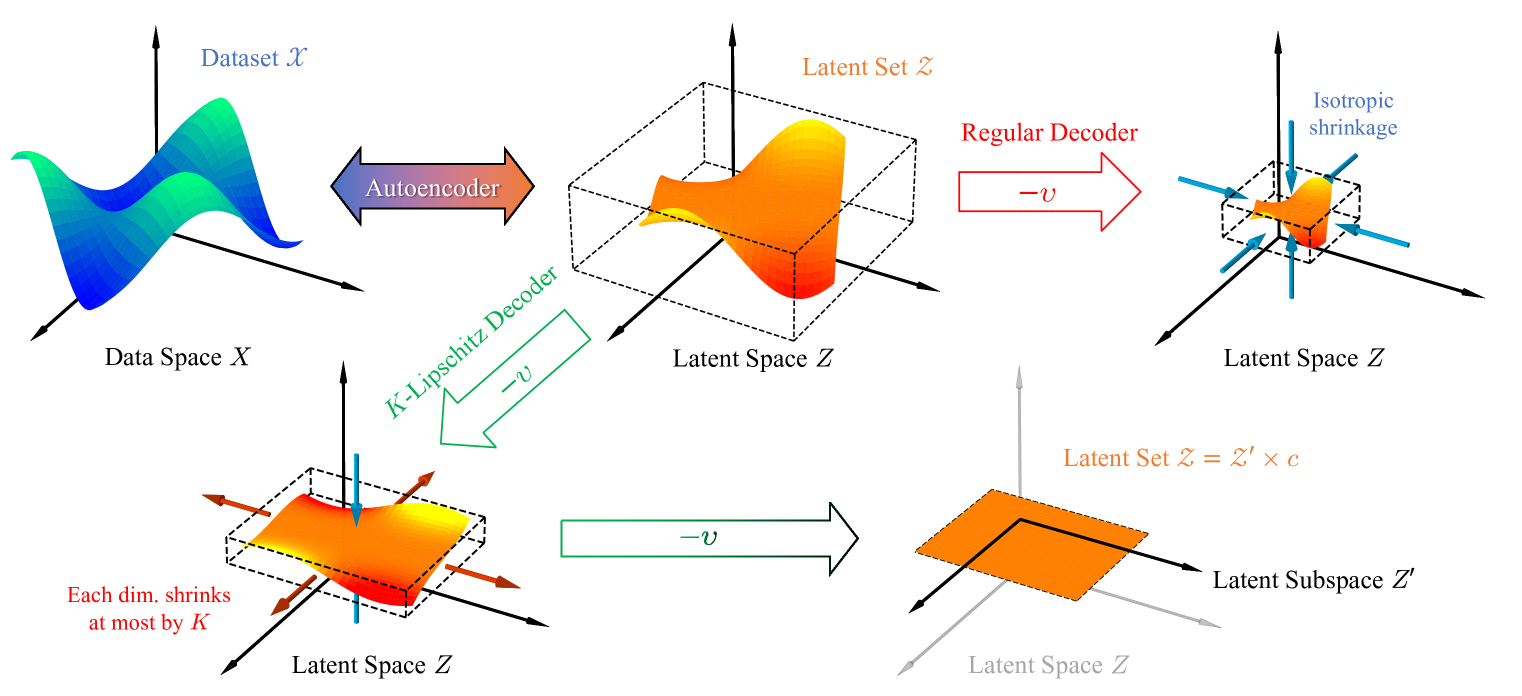
0
Compressing Latent Space via Least Volume
Qiuyi Chen, Mark Fuge
This paper introduces Least Volume-a simple yet effective regularization inspired by geometric intuition-that can reduce the necessary number of latent dimensions needed by an autoencoder without requiring any prior knowledge of the intrinsic dimensionality of the dataset. We show that the Lipschitz continuity of the decoder is the key to making it work, provide a proof that PCA is just a linear special case of it, and reveal that it has a similar PCA-like importance ordering effect when applied to nonlinear models. We demonstrate the intuition behind the regularization on some pedagogical toy problems, and its effectiveness on several benchmark problems, including MNIST, CIFAR-10 and CelebA.
Read more4/30/2024