The last Dance : Robust backdoor attack via diffusion models and bayesian approach
2402.05967
0
0

Abstract
Diffusion models are state-of-the-art deep learning generative models that are trained on the principle of learning forward and backward diffusion processes via the progressive addition of noise and denoising. In this paper, we aim to fool audio-based DNN models, such as those from the Hugging Face framework, primarily those that focus on audio, in particular transformer-based artificial intelligence models, which are powerful machine learning models that save time and achieve results faster and more efficiently. We demonstrate the feasibility of backdoor attacks (called BacKBayDiffMod) on audio transformers derived from Hugging Face, a popular framework in the world of artificial intelligence research. The backdoor attack developed in this paper is based on poisoning model training data uniquely by incorporating backdoor diffusion sampling and a Bayesian approach to the distribution of poisoned data.
Create account to get full access
Overview
- This paper proposes a novel backdoor attack method using diffusion models and a Bayesian approach.
- The proposed attack can be applied to a wide range of machine learning models, including image classifiers and language models.
- The attack is designed to be robust and effective, even in the face of defense mechanisms.
Plain English Explanation
The paper describes a new way to secretly manipulate machine learning models, known as a "backdoor attack." The researchers developed a technique that uses diffusion models and Bayesian statistics to insert a backdoor into a model. This backdoor allows the attackers to control the model's behavior, even after it has been trained and deployed.
The key idea is to create a special "trigger" that, when present in the input, causes the model to produce an attacker-chosen output. For example, the model might correctly classify most images, but misclassify any image containing a particular pattern as a different class. The researchers show that their backdoor attack is effective against a variety of machine learning models, including image classifiers and language models.
Importantly, the proposed attack is designed to be robust, meaning it can still work even if the model's owner tries to defend against it. This is a significant advancement over previous backdoor attacks, which were often fragile and could be easily detected or prevented.
Technical Explanation
The paper introduces a novel backdoor attack method that leverages diffusion models and a Bayesian approach. Diffusion models are a type of generative model that can be used to create realistic-looking synthetic data. In this work, the researchers use diffusion models to generate poisoned training data that contains a backdoor trigger.
The key steps of the attack are as follows:
- The attacker trains a diffusion model to generate poisoned data samples that contain a specific trigger pattern.
- The attacker uses a Bayesian optimization approach to find the optimal trigger pattern that will reliably cause the target model to misclassify inputs.
- The attacker injects the poisoned data samples into the target model's training dataset, effectively introducing the backdoor.
The researchers evaluate their attack on various machine learning models, including image classifiers and language models. They demonstrate that the proposed attack is effective and can remain undetected even in the presence of defense mechanisms, such as input transformation and label flipping.
Critical Analysis
The paper presents a compelling and technically sophisticated backdoor attack method. The use of diffusion models to generate poisoned data is a novel approach that could be difficult to detect, as the generated samples may appear indistinguishable from legitimate training data.
However, the paper does not address some potential limitations and concerns. For example, the attack relies on the attacker's ability to find an optimal trigger pattern using Bayesian optimization. In practice, this optimization process may be computationally expensive and may not always converge to an effective trigger. Additionally, the paper does not discuss the potential for the attack to be discovered through careful analysis of the target model's behavior or training data.
Furthermore, the widespread adoption of such backdoor attacks could have significant societal implications, as they could be used to undermine the reliability and trustworthiness of critical machine learning systems. The research community should continue to explore robust defenses and mitigation strategies to address these emerging threats.
Conclusion
This paper presents a novel and concerning backdoor attack method using diffusion models and Bayesian optimization. The proposed attack is designed to be robust and effective against a wide range of machine learning models, posing a significant threat to the security and reliability of AI systems.
While the technical merits of the research are clear, the potential for abuse and the societal implications of such attacks warrant careful consideration and further study. As the field of adversarial machine learning continues to evolve, it is crucial that researchers, practitioners, and policymakers work together to develop comprehensive strategies to detect, mitigate, and prevent these types of attacks from causing harm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
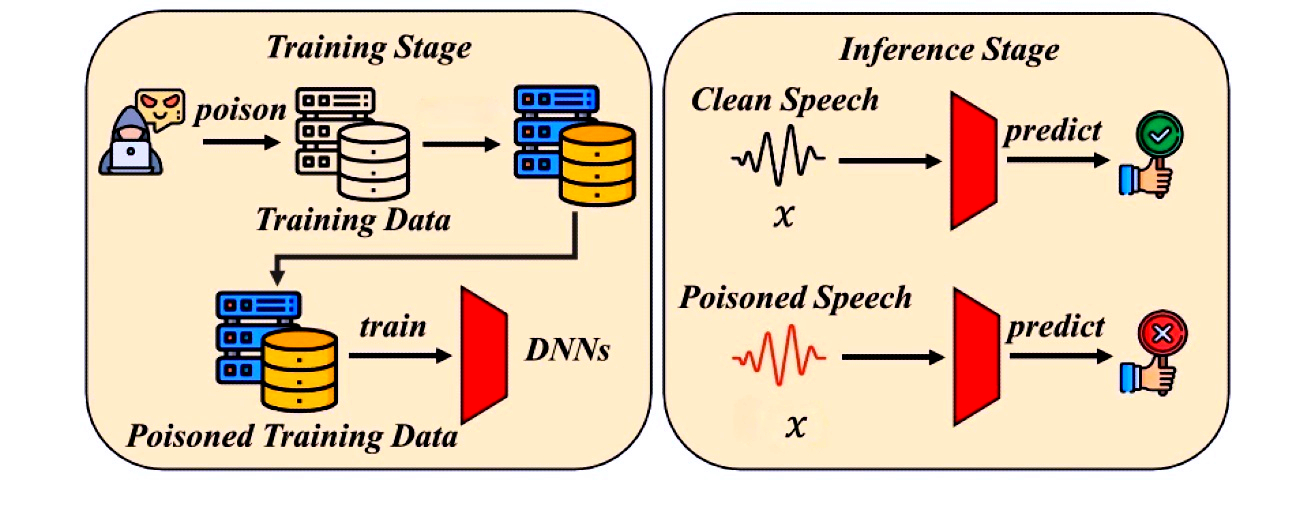
Trading Devil: Robust backdoor attack via Stochastic investment models and Bayesian approach
Orson Mengara
0
0
With the growing use of voice-activated systems and speech recognition technologies, the danger of backdoor attacks on audio data has grown significantly. This research looks at a specific type of attack, known as a Stochastic investment-based backdoor attack (MarketBack), in which adversaries strategically manipulate the stylistic properties of audio to fool speech recognition systems. The security and integrity of machine learning models are seriously threatened by backdoor attacks, in order to maintain the reliability of audio applications and systems, the identification of such attacks becomes crucial in the context of audio data. Experimental results demonstrated that MarketBack is feasible to achieve an average attack success rate close to 100% in seven victim models when poisoning less than 1% of the training data.
6/26/2024
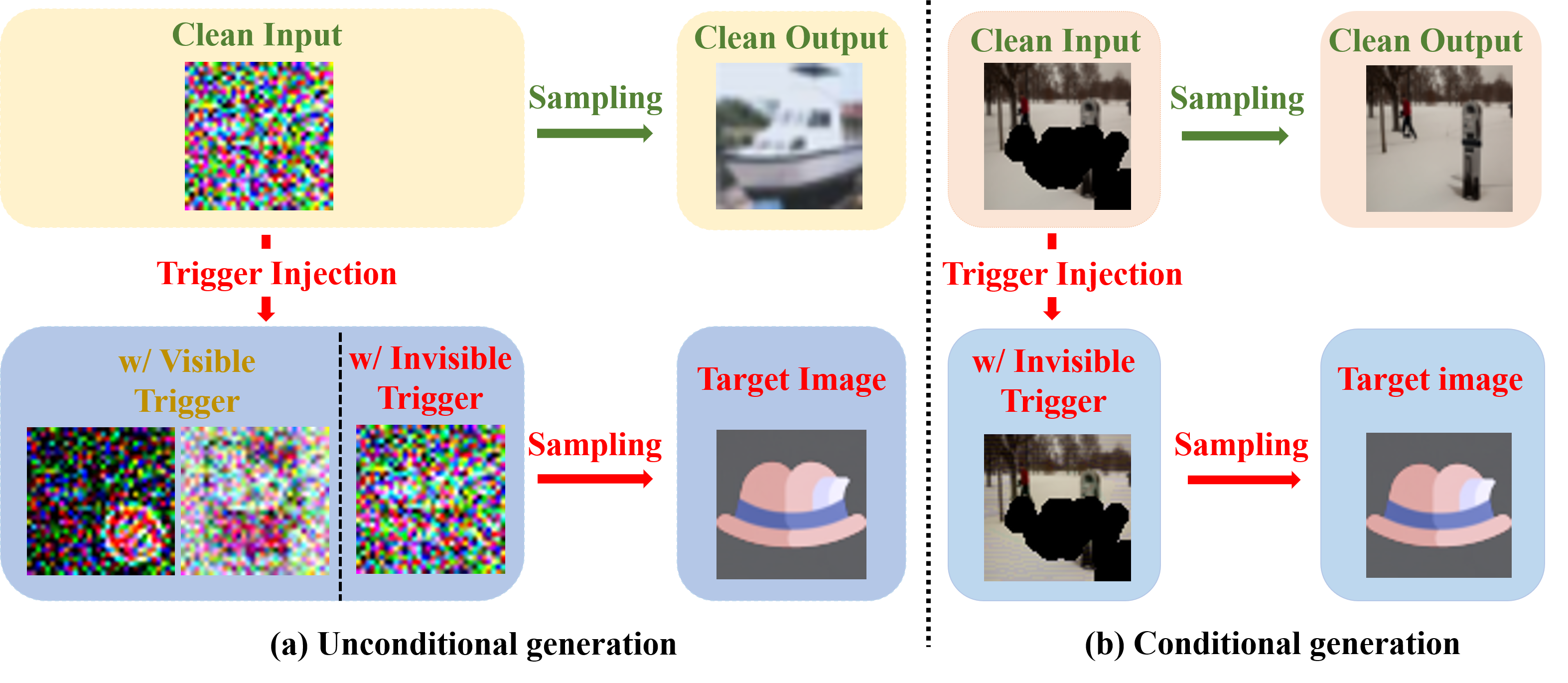
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
0
0
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
6/4/2024
📈
Backdoor for Debias: Mitigating Model Bias with Backdoor Attack-based Artificial Bias
Shangxi Wu, Qiuyang He, Dongyuan Lu, Jian Yu, Jitao Sang
0
0
With the swift advancement of deep learning, state-of-the-art algorithms have been utilized in various social situations. Nonetheless, some algorithms have been discovered to exhibit biases and provide unequal results. The current debiasing methods face challenges such as poor utilization of data or intricate training requirements. In this work, we found that the backdoor attack can construct an artificial bias similar to the model bias derived in standard training. Considering the strong adjustability of backdoor triggers, we are motivated to mitigate the model bias by carefully designing reverse artificial bias created from backdoor attack. Based on this, we propose a backdoor debiasing framework based on knowledge distillation, which effectively reduces the model bias from original data and minimizes security risks from the backdoor attack. The proposed solution is validated on both image and structured datasets, showing promising results. This work advances the understanding of backdoor attacks and highlights its potential for beneficial applications. The code for the study can be found at url{https://anonymous.4open.science/r/DwB-BC07/}.
6/18/2024

The Stronger the Diffusion Model, the Easier the Backdoor: Data Poisoning to Induce Copyright Breaches Without Adjusting Finetuning Pipeline
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, Kenji Kawaguchi
0
0
The commercialization of text-to-image diffusion models (DMs) brings forth potential copyright concerns. Despite numerous attempts to protect DMs from copyright issues, the vulnerabilities of these solutions are underexplored. In this study, we formalized the Copyright Infringement Attack on generative AI models and proposed a backdoor attack method, SilentBadDiffusion, to induce copyright infringement without requiring access to or control over training processes. Our method strategically embeds connections between pieces of copyrighted information and text references in poisoning data while carefully dispersing that information, making the poisoning data inconspicuous when integrated into a clean dataset. Our experiments show the stealth and efficacy of the poisoning data. When given specific text prompts, DMs trained with a poisoning ratio of 0.20% can produce copyrighted images. Additionally, the results reveal that the more sophisticated the DMs are, the easier the success of the attack becomes. These findings underline potential pitfalls in the prevailing copyright protection strategies and underscore the necessity for increased scrutiny to prevent the misuse of DMs.
5/28/2024