A Backdoor Approach with Inverted Labels Using Dirty Label-Flipping Attacks
2404.00076
0
0

Abstract
Audio-based machine learning systems frequently use public or third-party data, which might be inaccurate. This exposes deep neural network (DNN) models trained on such data to potential data poisoning attacks. In this type of assault, attackers can train the DNN model using poisoned data, potentially degrading its performance. Another type of data poisoning attack that is extremely relevant to our investigation is label flipping, in which the attacker manipulates the labels for a subset of data. It has been demonstrated that these assaults may drastically reduce system performance, even for attackers with minimal abilities. In this study, we propose a backdoor attack named 'DirtyFlipping', which uses dirty label techniques, label-on-label, to input triggers (clapping) in the selected data patterns associated with the target class, thereby enabling a stealthy backdoor.
Create account to get full access
Overview
- This paper presents a novel backdoor attack approach called "dirty label-flipping attacks" that can be used to compromise the security of machine learning models.
- The attack exploits the use of inverted labels during the training process to create a backdoor in the model, allowing the attacker to trigger specific misclassifications on demand.
- The authors demonstrate the effectiveness of their approach on a variety of tasks and datasets, highlighting the potential risks of such backdoor vulnerabilities in real-world machine learning applications.
Plain English Explanation
The paper describes a new type of attack on machine learning models called a "backdoor attack." In a backdoor attack, the attacker tries to find a way to secretly manipulate the model to make it behave incorrectly in certain situations, even though the model appears to work correctly most of the time.
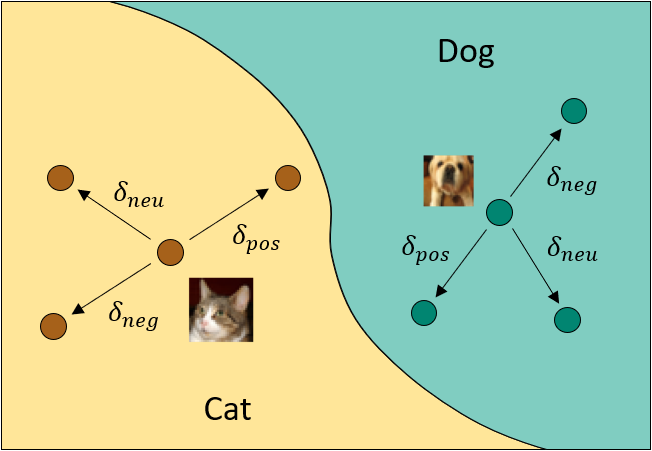
The specific attack technique presented in this paper involves "flipping" the labels of some training data during the model's learning process. For example, if the model is trying to learn to classify images of cats and dogs, the attacker might secretly tell the model that some dog images are actually cats, and vice versa.
This "dirty" label-flipping causes the model to learn an unintended association between certain input patterns (like a specific arrangement of pixels) and the wrong output label. The attacker can then trigger this backdoor by presenting the model with an input that contains that specific pattern, causing the model to output the wrong classification.
The authors show that this backdoor approach can be effective across various machine learning tasks and datasets, demonstrating the potential security risks of such vulnerabilities in real-world AI systems. The paper highlights the need for further research on backdoor defense and the importance of carefully scrutinizing the training process of machine learning models.
Technical Explanation
The paper presents a novel backdoor attack approach called "dirty label-flipping attacks" that can be used to compromise the security of machine learning models. The key idea is to exploit the use of inverted labels during the training process to create a backdoor in the model, allowing the attacker to trigger specific misclassifications on demand.
The authors first provide an overview of related work on backdoor attacks and defenses, including techniques like instruction-based backdoors, textual backdoor attacks, and backdoor attacks on multilingual models. They then describe their proposed "dirty label-flipping" approach in detail.
The attack works by systematically flipping the labels of a subset of the training data during the model's learning process. For example, in an image classification task, the attacker might secretly tell the model that some dog images are actually cats, and vice versa. This causes the model to learn an unintended association between certain input patterns and the wrong output label.
The authors demonstrate the effectiveness of their approach on various tasks and datasets, including image classification, sentiment analysis, and natural language inference. They show that their attack can achieve high trigger success rates while maintaining high clean accuracy on the original task, highlighting the potential risks of such backdoor vulnerabilities in real-world AI systems.
The authors also discuss potential defenses against their attack, such as backdoor defense techniques that aim to denoise the training data or detect backdoor triggers in the trained model. However, they note that these defenses may not be fully effective, and further research is needed to address the broader challenge of securing machine learning systems against various types of backdoor attacks.
Critical Analysis
The paper presents a compelling and technically sound approach to creating backdoor vulnerabilities in machine learning models. The authors have demonstrated the effectiveness of their "dirty label-flipping" attack across a range of tasks and datasets, underscoring the potential security risks of such vulnerabilities in real-world AI applications.
One potential limitation of the study is that it primarily focuses on the attacker's perspective, without delving deeply into the challenges and trade-offs faced by defenders. While the authors discuss some potential defense strategies, a more comprehensive analysis of the feasibility and limitations of these approaches would have strengthened the paper.
Additionally, the paper does not address the ethical implications of such backdoor attacks, nor does it consider the broader societal impact of such vulnerabilities. As machine learning systems become more pervasive in critical domains, it is crucial to carefully consider the security and safety implications of these technologies.
Overall, the paper makes a valuable contribution to the field of adversarial machine learning by introducing a novel attack technique and highlighting the need for continued research on robust and secure AI systems. However, future work should also address the ethical and societal considerations surrounding these types of attacks.
Conclusion
This paper presents a new type of backdoor attack called "dirty label-flipping" that can be used to compromise the security of machine learning models. The attack exploits the use of inverted labels during the training process to create a backdoor that allows the attacker to trigger specific misclassifications on demand.
The authors demonstrate the effectiveness of their approach across a variety of tasks and datasets, underscoring the potential risks of such backdoor vulnerabilities in real-world AI applications. The paper also discusses potential defense strategies, but notes that further research is needed to address the broader challenge of securing machine learning systems against various types of backdoor attacks.
As machine learning becomes more widely deployed in critical domains, the security and safety of these systems is of paramount importance. This paper highlights the need for continued vigilance and innovation in the field of adversarial machine learning, to ensure that these powerful technologies are developed and deployed in a responsible and trustworthy manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Poisoning-based Backdoor Attacks for Arbitrary Target Label with Positive Triggers
Binxiao Huang, Jason Chun Lok, Chang Liu, Ngai Wong
0
0
Poisoning-based backdoor attacks expose vulnerabilities in the data preparation stage of deep neural network (DNN) training. The DNNs trained on the poisoned dataset will be embedded with a backdoor, making them behave well on clean data while outputting malicious predictions whenever a trigger is applied. To exploit the abundant information contained in the input data to output label mapping, our scheme utilizes the network trained from the clean dataset as a trigger generator to produce poisons that significantly raise the success rate of backdoor attacks versus conventional approaches. Specifically, we provide a new categorization of triggers inspired by the adversarial technique and develop a multi-label and multi-payload Poisoning-based backdoor attack with Positive Triggers (PPT), which effectively moves the input closer to the target label on benign classifiers. After the classifier is trained on the poisoned dataset, we can generate an input-label-aware trigger to make the infected classifier predict any given input to any target label with a high possibility. Under both dirty- and clean-label settings, we show empirically that the proposed attack achieves a high attack success rate without sacrificing accuracy across various datasets, including SVHN, CIFAR10, GTSRB, and Tiny ImageNet. Furthermore, the PPT attack can elude a variety of classical backdoor defenses, proving its effectiveness.
5/10/2024
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Ziqiang Li, Hong Sun, Pengfei Xia, Heng Li, Beihao Xia, Yi Wu, Bin Li
0
0
Recent deep neural networks (DNNs) have came to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we introduce a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression and Poisoning Feature Augmentation.effective solution for data-constrained backdoor attacks. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Code is available at https://github.com/sunh1113/Efficient-backdoor-attacks-for-deep-neural-networks-in-real-world-scenarios
4/22/2024
🏋️
SEEP: Training Dynamics Grounds Latent Representation Search for Mitigating Backdoor Poisoning Attacks
Xuanli He, Qiongkai Xu, Jun Wang, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
Modern NLP models are often trained on public datasets drawn from diverse sources, rendering them vulnerable to data poisoning attacks. These attacks can manipulate the model's behavior in ways engineered by the attacker. One such tactic involves the implantation of backdoors, achieved by poisoning specific training instances with a textual trigger and a target class label. Several strategies have been proposed to mitigate the risks associated with backdoor attacks by identifying and removing suspected poisoned examples. However, we observe that these strategies fail to offer effective protection against several advanced backdoor attacks. To remedy this deficiency, we propose a novel defensive mechanism that first exploits training dynamics to identify poisoned samples with high precision, followed by a label propagation step to improve recall and thus remove the majority of poisoned instances. Compared with recent advanced defense methods, our method considerably reduces the success rates of several backdoor attacks while maintaining high classification accuracy on clean test sets.
5/21/2024

An Invisible Backdoor Attack Based On Semantic Feature
Yangming Chen
0
0
Backdoor attacks have severely threatened deep neural network (DNN) models in the past several years. These attacks can occur in almost every stage of the deep learning pipeline. Although the attacked model behaves normally on benign samples, it makes wrong predictions for samples containing triggers. However, most existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose a novel backdoor attack, making imperceptible changes. Concretely, our attack first utilizes the pre-trained victim model to extract low-level and high-level semantic features from clean images and generates trigger pattern associated with high-level features based on channel attention. Then, the encoder model generates poisoned images based on the trigger and extracted low-level semantic features without causing noticeable feature loss. We evaluate our attack on three prominent image classification DNN across three standard datasets. The results demonstrate that our attack achieves high attack success rates while maintaining robustness against backdoor defenses. Furthermore, we conduct extensive image similarity experiments to emphasize the stealthiness of our attack strategy.
5/21/2024