Latent Concept-based Explanation of NLP Models

0

Sign in to get full access
Overview
- This paper introduces a new technique called "ConceptDiscoverer" for explaining the inner workings of natural language processing (NLP) models.
- The method aims to identify the latent concepts that NLP models rely on to make predictions, providing more interpretable and transparent explanations.
- The authors demonstrate the application of ConceptDiscoverer on several popular NLP models and datasets, showing its effectiveness at surfacing meaningful conceptual insights.
Plain English Explanation
The paper focuses on making complex NLP models more understandable. NLP models, like those used for text classification or language generation, can be very powerful but also quite opaque - it's often unclear how they arrive at their predictions. The researchers developed a new technique called ConceptDiscoverer that tries to uncover the underlying "concepts" that these models are using to make their decisions.
The key idea is that NLP models don't just look at individual words, but instead learn to recognize more abstract patterns and concepts in the text. For example, a model tasked with detecting fake news might pick up on concepts like "factual reporting," "political bias," or "sensationalism." ConceptDiscoverer aims to identify these latent concepts and explain how the model is using them to make predictions.
By surfacing these conceptual building blocks, the researchers hope to provide more interpretable and transparent explanations of NLP model behavior. This could be useful for tasks like debugging model errors, auditing for biases, or simply helping human users understand how the models work. The paper demonstrates the approach on a variety of NLP tasks and shows that it can uncover meaningful conceptual insights.
Technical Explanation
The key innovation in this paper is the ConceptDiscoverer method, which the authors use to explain the inner workings of NLP models. The core idea is to identify a set of latent concepts that the model is implicitly relying on, and then quantify the model's "reliance" on each concept for making predictions.
The process starts by training a separate "concept discovery" model to identify the most salient concepts in the input data. This model is trained in an unsupervised way to find a set of latent concepts that can effectively reconstruct the original text. The authors then use this concept discovery model to obtain a "concept activation vector" for each input example, indicating the model's inferred reliance on each discovered concept.
Next, the researchers train the target NLP model as usual, but also compute the concept activation vectors for each training example. This allows them to quantify how much the NLP model's predictions depend on each of the discovered concepts. They do this by training a linear regression model to predict the NLP model's output based on the concept activation vectors.
The authors demonstrate this approach on several popular NLP tasks, including text classification, question answering, and natural language inference. They show that the discovered concepts align with intuitive notions of what the models are learning, and that the concept-based explanations provide useful insights beyond traditional feature importance or attention-based explanations.
Critical Analysis
The ConceptDiscoverer approach represents an important step forward in making NLP models more interpretable and transparent. By surfacing the latent conceptual building blocks that models are relying on, it provides a more meaningful and intuitive form of explanation compared to techniques like feature importance or attention visualization.
That said, the authors acknowledge several limitations and areas for further research. First, the concept discovery process itself is not trivial and requires careful tuning and validation. The resulting concepts may not always align perfectly with human intuitions, and the method could miss important nuances.
Additionally, while the concept-based explanations are more interpretable than raw model parameters, they still require some level of technical expertise to fully understand. There may be opportunities to further simplify and package the explanations for non-expert users.
Another key question is the extent to which the discovered concepts generalize beyond the specific training data and tasks. The paper demonstrates the approach on a limited set of benchmarks, so more research is needed to understand its broader applicability and limitations.
Finally, the authors do not delve into potential societal impacts or ethical considerations around model explainability. As these NLP systems become more widely deployed, it will be critical to carefully assess their explanations for issues like unwanted biases or harmful decision-making.
Overall, the ConceptDiscoverer technique represents an important advance in the field of interpretable machine learning. With further research and refinement, it could become a valuable tool for building more transparent and trustworthy NLP systems.
Conclusion
This paper introduces a new method called ConceptDiscoverer that aims to make NLP models more interpretable by identifying the latent conceptual building blocks they rely on. By surfacing these conceptual insights, the approach provides more meaningful and intuitive explanations of model behavior compared to traditional techniques.
The authors demonstrate the effectiveness of ConceptDiscoverer on several NLP tasks, showing that it can uncover conceptual patterns that align with human intuitions. While the method has some limitations and areas for further research, it represents an important step forward in making complex NLP models more transparent and accountable.
As AI systems become more pervasive in high-stakes domains, techniques like ConceptDiscoverer will be crucial for building trust, enabling oversight, and ensuring the responsible development of these technologies. The continued advancement of interpretable machine learning will be critical for realizing the full potential of NLP while mitigating potential risks and harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent Concept-based Explanation of NLP Models
Xuemin Yu, Fahim Dalvi, Nadir Durrani, Marzia Nouri, Hassan Sajjad
Interpreting and understanding the predictions made by deep learning models poses a formidable challenge due to their inherently opaque nature. Many previous efforts aimed at explaining these predictions rely on input features, specifically, the words within NLP models. However, such explanations are often less informative due to the discrete nature of these words and their lack of contextual verbosity. To address this limitation, we introduce the Latent Concept Attribution method (LACOAT), which generates explanations for predictions based on latent concepts. Our foundational intuition is that a word can exhibit multiple facets, contingent upon the context in which it is used. Therefore, given a word in context, the latent space derived from our training process reflects a specific facet of that word. LACOAT functions by mapping the representations of salient input words into the training latent space, allowing it to provide latent context-based explanations of the prediction.
Read more6/19/2024
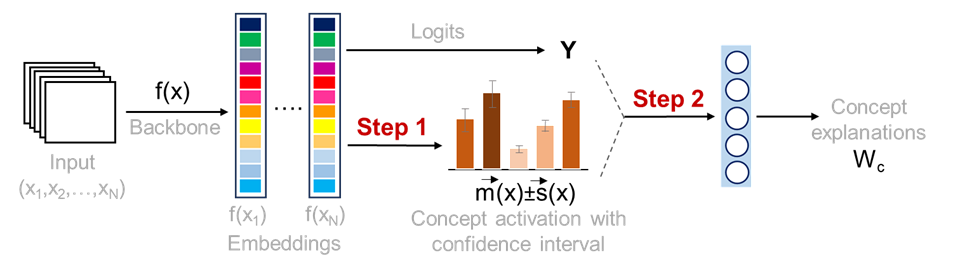
0
Estimation of Concept Explanations Should be Uncertainty Aware
Vihari Piratla, Juyeon Heo, Katherine M. Collins, Sukriti Singh, Adrian Weller
Model explanations can be valuable for interpreting and debugging predictive models. We study a specific kind called Concept Explanations, where the goal is to interpret a model using human-understandable concepts. Although popular for their easy interpretation, concept explanations are known to be noisy. We begin our work by identifying various sources of uncertainty in the estimation pipeline that lead to such noise. We then propose an uncertainty-aware Bayesian estimation method to address these issues, which readily improved the quality of explanations. We demonstrate with theoretical analysis and empirical evaluation that explanations computed by our method are robust to train-time choices while also being label-efficient. Further, our method proved capable of recovering relevant concepts amongst a bank of thousands, in an evaluation with real-datasets and off-the-shelf models, demonstrating its scalability. We believe the improved quality of uncertainty-aware concept explanations make them a strong candidate for more reliable model interpretation. We release our code at https://github.com/vps-anonconfs/uace.
Read more4/8/2024

0
Explainable Concept Generation through Vision-Language Preference Learning
Aditya Taparia, Som Sagar, Ransalu Senanayake
Concept-based explanations have become a popular choice for explaining deep neural networks post-hoc because, unlike most other explainable AI techniques, they can be used to test high-level visual concepts that are not directly related to feature attributes. For instance, the concept of stripes is important to classify an image as a zebra. Concept-based explanation methods, however, require practitioners to guess and collect multiple candidate concept image sets, which can often be imprecise and labor-intensive. Addressing this limitation, in this paper, we frame concept image set creation as an image generation problem. However, since naively using a generative model does not result in meaningful concepts, we devise a reinforcement learning-based preference optimization algorithm that fine-tunes the vision-language generative model from approximate textual descriptions of concepts. Through a series of experiments, we demonstrate the capability of our method to articulate complex, abstract concepts that are otherwise challenging to craft manually. In addition to showing the efficacy and reliability of our method, we show how our method can be used as a diagnostic tool for analyzing neural networks.
Read more8/27/2024

0
Concept-aware Data Construction Improves In-context Learning of Language Models
Michal v{S}tef'anik, Marek Kadlv{c}'ik, Petr Sojka
Many recent language models (LMs) are capable of in-context learning (ICL), manifested in the LMs' ability to perform a new task solely from natural-language instruction. Previous work curating in-context learners assumes that ICL emerges from a vast over-parametrization or the scale of multi-task training. However, recent theoretical work attributes the ICL ability to concept-dependent training data and creates functional in-context learners even in small-scale, synthetic settings. In this work, we practically explore this newly identified axis of ICL quality. We propose Concept-aware Training (CoAT), a framework for constructing training scenarios that make it beneficial for the LM to learn to utilize the analogical reasoning concepts from demonstrations. We find that by using CoAT, pre-trained transformers can learn to better utilise new latent concepts from demonstrations and that such ability makes ICL more robust to the functional deficiencies of the previous models. Finally, we show that concept-aware in-context learning is more effective for a majority of new tasks when compared to traditional instruction tuning, resulting in a performance comparable to the previous in-context learners using magnitudes of more training data.
Read more7/1/2024