Latent Space Energy-based Neural ODEs

0

Sign in to get full access
Overview
- Introduces a new class of models called Latent Space Energy-based Neural ODEs (LS-eNODEs)
- Combines energy-based models and neural ordinary differential equations (ODEs) to learn low-dimensional latent dynamics
- Demonstrates improved performance on several tasks compared to existing methods
Plain English Explanation
Latent Space Energy-based Neural ODEs (LS-eNODEs) are a new type of machine learning model that combines two powerful concepts: energy-based models and neural ordinary differential equations (ODEs).
Energy-based models learn to represent complex data in a compact, low-dimensional "latent space" by assigning an "energy" value to each possible representation. The lower the energy, the more likely the representation is to be correct. Neural ODEs, on the other hand, are a way to model the continuous evolution of data over time using neural networks.
By bringing these two ideas together, LS-eNODEs can learn low-dimensional latent representations of data that also capture how those representations change over time. This allows the model to better understand and predict the dynamics of complex systems, which is useful for a variety of applications like robotics, weather forecasting, and disease modeling.
The researchers show that LS-eNODEs outperform existing methods on several benchmark tasks, demonstrating the power of this new approach.
Technical Explanation
The key insight behind Latent Space Energy-based Neural ODEs (LS-eNODEs) is to combine the representation learning capabilities of energy-based models with the temporal modeling power of neural ODEs. The model learns a low-dimensional latent representation of the input data, as well as a dynamical system that governs how that latent representation evolves over time.
Formally, the LS-eNODE model consists of three main components:
- Encoder: A neural network that maps the input data to a low-dimensional latent representation.
- Dynamics network: A neural network that models the evolution of the latent representation over time as a continuous-time dynamical system, described by a neural ODE.
- Energy function: An energy-based model that assigns an "energy" value to each latent representation, encouraging the model to learn low-energy, more likely representations.
The encoder and dynamics network are trained end-to-end to minimize the energy of the latent representations while accurately capturing the temporal evolution of the data. This allows the model to learn compact, interpretable latent representations that also capture the underlying dynamics of the system.
The researchers evaluate LS-eNODEs on several benchmark tasks, including latent dynamics learning, stable neural ODE learning, and continuous learned primal-dual optimization. They demonstrate that LS-eNODEs outperform existing methods, highlighting the benefits of combining energy-based and ODE-based approaches for learning latent dynamical systems.
Critical Analysis
The paper presents a novel and promising approach to learning low-dimensional latent representations of complex, time-varying data. By integrating energy-based models and neural ODEs, LS-eNODEs can capture both the structure of the data and its underlying dynamics in a compact, interpretable form.
One potential limitation of the approach is the reliance on the encoder and dynamics network being able to learn the necessary representations and dynamics, which may be challenging for highly complex or chaotic systems. The researchers acknowledge this and suggest that incorporating additional inductive biases or constraints may be necessary for such cases.
Additionally, the paper does not explore the interpretability of the learned latent representations and dynamics in depth. While the energy-based formulation provides a principled way to learn low-dimensional representations, more work may be needed to ensure the latent space is truly meaningful and interpretable to human users.
Finally, the paper focuses on benchmark tasks and does not investigate the real-world applicability of LS-eNODEs. It would be valuable to see how the method performs on more practical problems, such as in areas like robotics, climate modeling, or healthcare, where the ability to learn interpretable latent dynamics could have significant impact.
Conclusion
Latent Space Energy-based Neural ODEs (LS-eNODEs) represent an exciting new direction in machine learning, combining the representation learning capabilities of energy-based models with the temporal modeling power of neural ODEs. By learning low-dimensional latent representations that also capture the underlying dynamics of complex systems, LS-eNODEs have the potential to advance a wide range of applications that rely on understanding and predicting the evolution of data over time. While the method shows promising results on benchmark tasks, further research is needed to fully explore its real-world applicability and the interpretability of the learned representations and dynamics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent Space Energy-based Neural ODEs
Sheng Cheng, Deqian Kong, Jianwen Xie, Kookjin Lee, Ying Nian Wu, Yezhou Yang
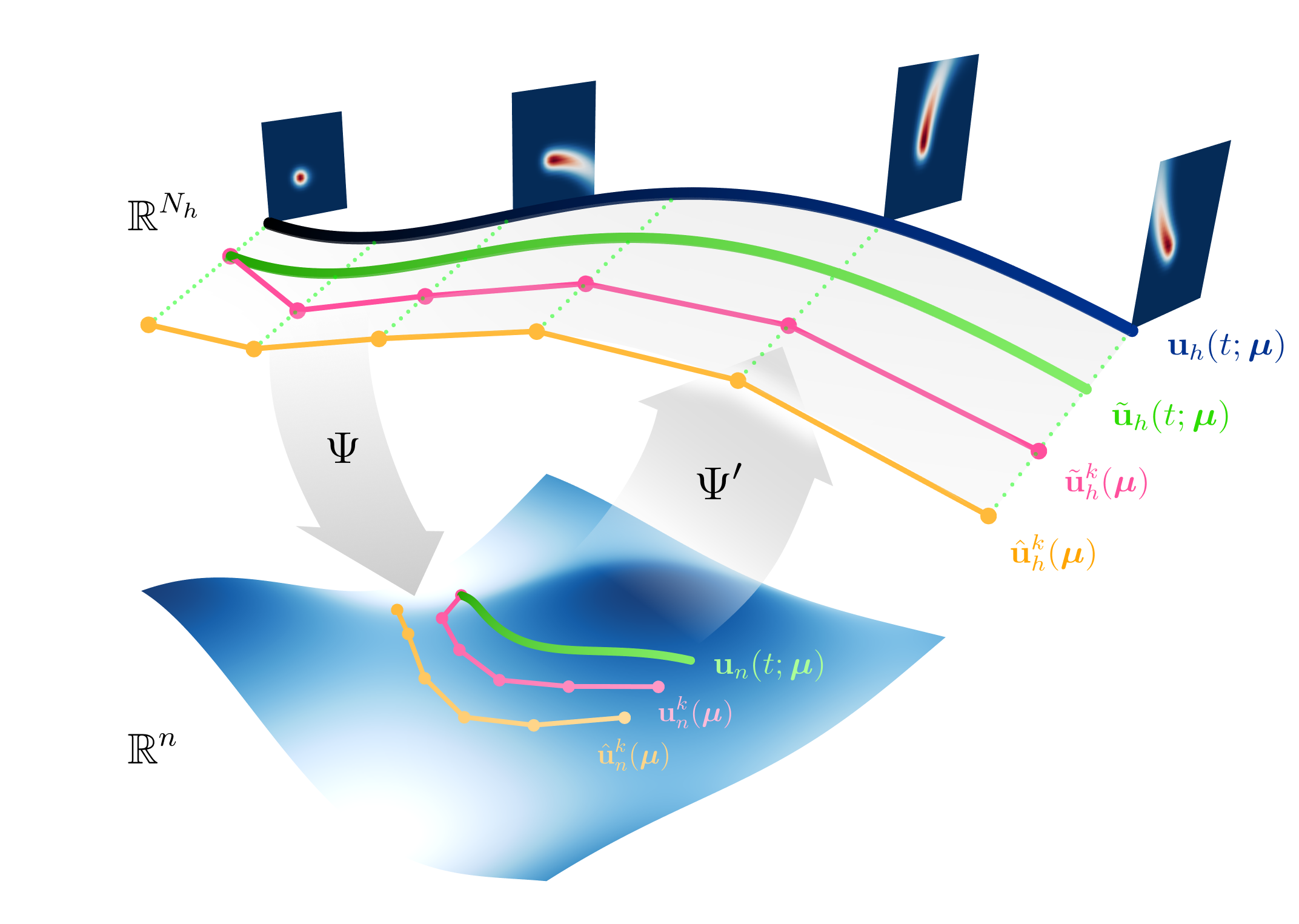
This paper introduces a novel family of deep dynamical models designed to represent continuous-time sequence data. This family of models generates each data point in the time series by a neural emission model, which is a non-linear transformation of a latent state vector. The trajectory of the latent states is implicitly described by a neural ordinary differential equation (ODE), with the initial state following an informative prior distribution parameterized by an energy-based model. Furthermore, we can extend this model to disentangle dynamic states from underlying static factors of variation, represented as time-invariant variables in the latent space. We train the model using maximum likelihood estimation with Markov chain Monte Carlo (MCMC) in an end-to-end manner, without requiring additional assisting components such as an inference network. Our experiments on oscillating systems, videos and real-world state sequences (MuJoCo) illustrate that ODEs with the learnable energy-based prior outperform existing counterparts, and can generalize to new dynamic parameterization, enabling long-horizon predictions.
Read more9/9/2024
0
On latent dynamics learning in nonlinear reduced order modeling
Nicola Farenga, Stefania Fresca, Simone Brivio, Andrea Manzoni
In this work, we present the novel mathematical framework of latent dynamics models (LDMs) for reduced order modeling of parameterized nonlinear time-dependent PDEs. Our framework casts this latter task as a nonlinear dimensionality reduction problem, while constraining the latent state to evolve accordingly to an (unknown) dynamical system. A time-continuous setting is employed to derive error and stability estimates for the LDM approximation of the full order model (FOM) solution. We analyze the impact of using an explicit Runge-Kutta scheme in the time-discrete setting, resulting in the $Deltatext{LDM}$ formulation, and further explore the learnable setting, $Deltatext{LDM}_theta$, where deep neural networks approximate the discrete LDM components, while providing a bounded approximation error with respect to the FOM. Moreover, we extend the concept of parameterized Neural ODE - recently proposed as a possible way to build data-driven dynamical systems with varying input parameters - to be a convolutional architecture, where the input parameters information is injected by means of an affine modulation mechanism, while designing a convolutional autoencoder neural network able to retain spatial-coherence, thus enhancing interpretability at the latent level. Numerical experiments, including the Burgers' and the advection-reaction-diffusion equations, demonstrate the framework's ability to obtain, in a multi-query context, a time-continuous approximation of the FOM solution, thus being able to query the LDM approximation at any given time instance while retaining a prescribed level of accuracy. Our findings highlight the remarkable potential of the proposed LDMs, representing a mathematically rigorous framework to enhance the accuracy and approximation capabilities of reduced order modeling for time-dependent parameterized PDEs.
Read more8/28/2024

0
Learning Deep Dynamical Systems using Stable Neural ODEs
Andreas Sochopoulos, Michael Gienger, Sethu Vijayakumar
Learning complex trajectories from demonstrations in robotic tasks has been effectively addressed through the utilization of Dynamical Systems (DS). State-of-the-art DS learning methods ensure stability of the generated trajectories; however, they have three shortcomings: a) the DS is assumed to have a single attractor, which limits the diversity of tasks it can achieve, b) state derivative information is assumed to be available in the learning process and c) the state of the DS is assumed to be measurable at inference time. We propose a class of provably stable latent DS with possibly multiple attractors, that inherit the training methods of Neural Ordinary Differential Equations, thus, dropping the dependency on state derivative information. A diffeomorphic mapping for the output and a loss that captures time-invariant trajectory similarity are proposed. We validate the efficacy of our approach through experiments conducted on a public dataset of handwritten shapes and within a simulated object manipulation task.
Read more4/17/2024

0
Continuous Learned Primal Dual
Christina Runkel, Ander Biguri, Carola-Bibiane Schonlieb
Neural ordinary differential equations (Neural ODEs) propose the idea that a sequence of layers in a neural network is just a discretisation of an ODE, and thus can instead be directly modelled by a parameterised ODE. This idea has had resounding success in the deep learning literature, with direct or indirect influence in many state of the art ideas, such as diffusion models or time dependant models. Recently, a continuous version of the U-net architecture has been proposed, showing increased performance over its discrete counterpart in many imaging applications and wrapped with theoretical guarantees around its performance and robustness. In this work, we explore the use of Neural ODEs for learned inverse problems, in particular with the well-known Learned Primal Dual algorithm, and apply it to computed tomography (CT) reconstruction.
Read more5/7/2024