On Layer-wise Representation Similarity: Application for Multi-Exit Models with a Single Classifier

0

Sign in to get full access
Overview
- This paper proposes a method for designing multi-exit models with a single classifier, using layer-wise representation similarity as the guiding principle.
- The key idea is to leverage the similarity between the representations learned by different layers of the model to determine appropriate exit points, without the need for multiple classifiers.
- The authors demonstrate the effectiveness of this approach on various computer vision tasks, showing that it can achieve comparable or better performance compared to traditional multi-exit models.
Plain English Explanation
In machine learning, there is often a trade-off between the accuracy of a model and the time it takes to make a prediction. Multi-exit models are a way to address this, where the model has multiple "exit points" that can provide predictions at different levels of accuracy and inference time.
Traditionally, multi-exit models require training multiple classifiers, one for each exit point. However, this can be computationally expensive and complex to implement.
The authors of this paper propose a new approach that uses a single classifier, but still allows for multiple exit points. The key idea is to look at the similarity between the representations learned by different layers of the model. By analyzing this layer-wise similarity, they can identify appropriate exit points without the need for multiple classifiers.
This approach has several benefits:
- It's simpler to implement, as you only need a single classifier.
- It can achieve comparable or even better performance than traditional multi-exit models.
- It provides more flexibility in terms of the trade-off between accuracy and inference time.
The authors demonstrate the effectiveness of their method on various computer vision tasks, showing that it can be a powerful tool for building efficient and accurate AI models.
Technical Explanation
The core idea of this paper is to leverage the layer-wise representation similarity in deep neural networks to design multi-exit models with a single classifier. The authors argue that as a model goes deeper, the representations learned by successive layers become increasingly similar. By identifying the appropriate layers where this similarity is high, they can determine suitable exit points without the need for multiple classifiers.
To do this, the authors first train a single deep neural network model on the task of interest. They then compute the cosine similarity between the representations of adjacent layers, and use this information to identify the layers where the similarity is above a certain threshold. These layers are then designated as the exit points for the multi-exit model.
During inference, the input is passed through the model, and the prediction is made at the first exit point where the confidence of the prediction is above a specified threshold. This allows the model to provide a result quickly for easy-to-classify inputs, while still maintaining high accuracy for more challenging inputs that require deeper processing.
The authors evaluate their approach on several computer vision tasks, including image classification and object detection. They show that the multi-exit models with a single classifier can achieve comparable or even better performance than traditional multi-exit models that use multiple classifiers. This highlights the potential of this approach for building efficient and accurate AI systems.
Critical Analysis
One of the key strengths of this paper is its simplicity and elegance. By leveraging the inherent structure of deep neural networks, the authors are able to design multi-exit models without the added complexity of training multiple classifiers. This can significantly reduce the computational resources and engineering effort required to deploy such models in real-world applications.
However, the paper does not explore the limitations of this approach in depth. For example, it's unclear how the method would perform on tasks with more complex feature hierarchies, or on models with skip connections or other architectural variations. Additionally, the authors do not discuss the sensitivity of the approach to the choice of similarity threshold, which could be an important hyperparameter in practice.
Another potential concern is the reliance on a single classifier. While this simplifies the model, it also means that the entire model must be kept in memory during inference, which could be a limiting factor for deployment on resource-constrained devices. Mixture-of-experts or other techniques for modularizing the model could be an interesting avenue for future research.
Overall, this paper presents a promising approach for designing efficient multi-exit models, and the authors have demonstrated its effectiveness on various computer vision tasks. However, further research is needed to fully understand the limitations and potential extensions of this method, especially in the context of more complex models and real-world deployment scenarios.
Conclusion
This paper introduces a novel approach for designing multi-exit models with a single classifier, using layer-wise representation similarity as the guiding principle. By leveraging the inherent structure of deep neural networks, the authors are able to identify appropriate exit points without the need for multiple classifiers, which can significantly simplify the implementation and deployment of such models.
The authors demonstrate the effectiveness of their method on various computer vision tasks, showing that it can achieve comparable or even better performance than traditional multi-exit models. This highlights the potential of this approach for building efficient and accurate AI systems that can adapt to different computational constraints and user requirements.
While the paper presents a promising solution, there are still opportunities for further research to address the potential limitations and explore extensions of this method. Nevertheless, this work represents an important contribution to the field of efficient and adaptive AI model design, and it is likely to inspire further developments in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On Layer-wise Representation Similarity: Application for Multi-Exit Models with a Single Classifier
Jiachen Jiang, Jinxin Zhou, Zhihui Zhu
Analyzing the similarity of internal representations within and across different models has been an important technique for understanding the behavior of deep neural networks. Most existing methods for analyzing the similarity between representations of high dimensions, such as those based on Canonical Correlation Analysis (CCA) and widely used Centered Kernel Alignment (CKA), rely on statistical properties of the representations for a set of data points. In this paper, we focus on transformer models and study the similarity of representations between the hidden layers of individual transformers. In this context, we show that a simple sample-wise cosine similarity metric is capable of capturing the similarity and aligns with the complicated CKA. Our experimental results on common transformers reveal that representations across layers are positively correlated, albeit the similarity decreases when layers are far apart. We then propose an aligned training approach to enhance the similarity between internal representations, with trained models that enjoy the following properties: (1) the last-layer classifier can be directly applied right after any hidden layers, yielding intermediate layer accuracies much higher than those under standard training, (2) the layer-wise accuracies monotonically increase and reveal the minimal depth needed for the given task, (3) when served as multi-exit models, they achieve on-par performance with standard multi-exit architectures which consist of additional classifiers designed for early exiting in shallow layers. To our knowledge, our work is the first to show that one common classifier is sufficient for multi-exit models. We conduct experiments on both vision and NLP tasks to demonstrate the performance of the proposed aligned training.
Read more6/21/2024

0
Effective Layer Pruning Through Similarity Metric Perspective
Ian Pons, Bruno Yamamoto, Anna H. Reali Costa, Artur Jordao
Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.
Read more5/28/2024
⛏️
0
Explaining Text Similarity in Transformer Models
Alexandros Vasileiou, Oliver Eberle
As Transformers have become state-of-the-art models for natural language processing (NLP) tasks, the need to understand and explain their predictions is increasingly apparent. Especially in unsupervised applications, such as information retrieval tasks, similarity models built on top of foundation model representations have been widely applied. However, their inner prediction mechanisms have mostly remained opaque. Recent advances in explainable AI have made it possible to mitigate these limitations by leveraging improved explanations for Transformers through layer-wise relevance propagation (LRP). Using BiLRP, an extension developed for computing second-order explanations in bilinear similarity models, we investigate which feature interactions drive similarity in NLP models. We validate the resulting explanations and demonstrate their utility in three corpus-level use cases, analyzing grammatical interactions, multilingual semantics, and biomedical text retrieval. Our findings contribute to a deeper understanding of different semantic similarity tasks and models, highlighting how novel explainable AI methods enable in-depth analyses and corpus-level insights.
Read more5/13/2024
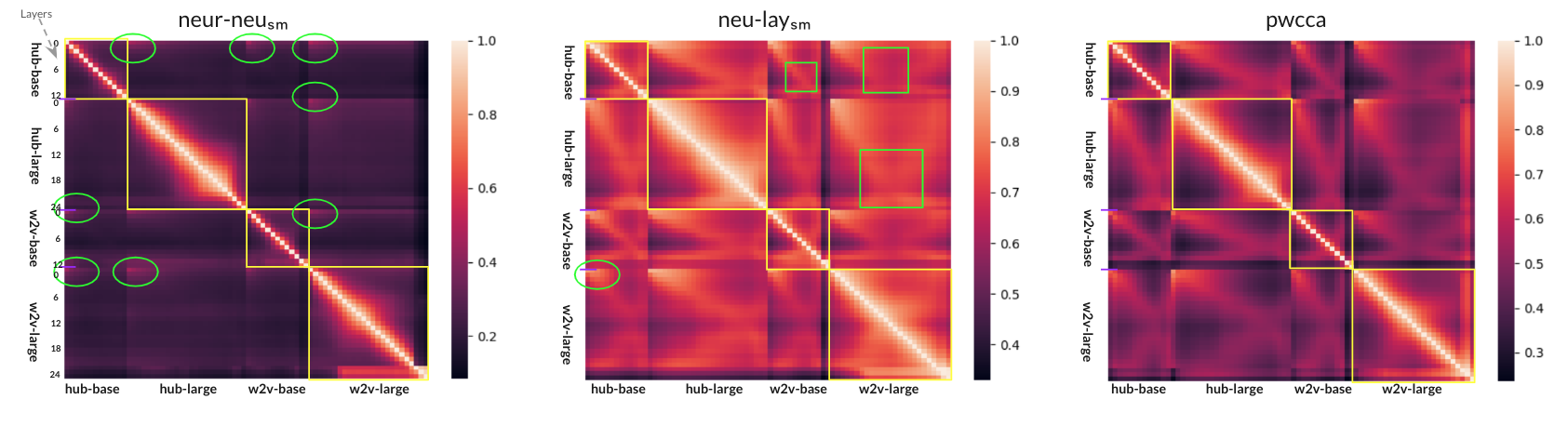
0
Speech Representation Analysis based on Inter- and Intra-Model Similarities
Yassine El Kheir, Ahmed Ali, Shammur Absar Chowdhury
Self-supervised models have revolutionized speech processing, achieving new levels of performance in a wide variety of tasks with limited resources. However, the inner workings of these models are still opaque. In this paper, we aim to analyze the encoded contextual representation of these foundation models based on their inter- and intra-model similarity, independent of any external annotation and task-specific constraint. We examine different SSL models varying their training paradigm -- Contrastive (Wav2Vec2.0) and Predictive models (HuBERT); and model sizes (base and large). We explore these models on different levels of localization/distributivity of information including (i) individual neurons; (ii) layer representation; (iii) attention weights and (iv) compare the representations with their finetuned counterparts.Our results highlight that these models converge to similar representation subspaces but not to similar neuron-localized conceptsfootnote{A concept represents a coherent fragment of knowledge, such as ``a class containing certain objects as elements, where the objects have certain properties. We made the code publicly available for facilitating further research, we publicly released our code.
Read more6/26/2024