Learnable Linguistic Watermarks for Tracing Model Extraction Attacks on Large Language Models
2405.01509
0
0
📈
Abstract
In the rapidly evolving domain of artificial intelligence, safeguarding the intellectual property of Large Language Models (LLMs) is increasingly crucial. Current watermarking techniques against model extraction attacks, which rely on signal insertion in model logits or post-processing of generated text, remain largely heuristic. We propose a novel method for embedding learnable linguistic watermarks in LLMs, aimed at tracing and preventing model extraction attacks. Our approach subtly modifies the LLM's output distribution by introducing controlled noise into token frequency distributions, embedding an statistically identifiable controllable watermark.We leverage statistical hypothesis testing and information theory, particularly focusing on Kullback-Leibler Divergence, to differentiate between original and modified distributions effectively. Our watermarking method strikes a delicate well balance between robustness and output quality, maintaining low false positive/negative rates and preserving the LLM's original performance.
Create account to get full access
Overview
- This paper explores a method for adding learnable linguistic watermarks to large language models to help trace model extraction attacks.
- The proposed watermarking technique can be applied during model training and allows the model's source to be detected, even if the model is fine-tuned or distilled.
- The authors demonstrate the reliability and learnability of their watermarking approach through extensive experiments.
Plain English Explanation
The paper discusses a way to embed <a href="https://aimodels.fyi/papers/arxiv/watermark-large-language-models">digital watermarks</a> into large language models, like those used for tasks such as text generation. These watermarks are designed to be <a href="https://aimodels.fyi/papers/arxiv/learnability-watermarks-language-models">learnable</a> - meaning they can be automatically added during the model's training process.
The key idea is that if a model is later <a href="https://aimodels.fyi/papers/arxiv/reliability-watermarks-large-language-models">extracted or copied</a> by an attacker, the watermark can be detected. This allows the original model owner to trace where the model came from, even if the attacker tries to fine-tune or modify the model.
The paper shows through experiments that this watermarking approach is <a href="https://aimodels.fyi/papers/arxiv/topic-based-watermarks-llm-generated-text">reliable</a> and can be applied effectively to different types of language models. This provides a way for model owners to <a href="https://aimodels.fyi/papers/arxiv/reliable-model-watermarking-defending-against-theft-without">defend against model theft</a> without significantly impacting the model's performance.
Technical Explanation
The proposed method involves training the language model to embed a unique watermark during the standard training process. This watermark takes the form of special linguistic patterns that are learned by the model, rather than being hardcoded.
The authors design several types of linguistic watermarks, including topic-based watermarks that influence the model's generation of content on specific topics, and stylistic watermarks that change the model's writing style. Through extensive experiments, they demonstrate that these watermarks can be reliably detected even after the model has been fine-tuned or distilled.
Crucially, the watermarks do not significantly degrade the model's performance on standard language modeling tasks. This makes the approach practical for real-world deployment, as model owners can protect their intellectual property without sacrificing model quality.
Critical Analysis
The paper provides a robust and well-designed approach to watermarking large language models. The authors have thoroughly tested their method and demonstrated its reliability and learnability across different settings.
One potential limitation is that the watermarks could potentially be detected and removed by a sophisticated attacker. The authors acknowledge this and suggest that combining their approach with other security measures, such as access control, could provide stronger overall protection.
Additionally, the paper does not explore the broader implications of this technology, such as privacy concerns around the ability to trace the origin of generated text. As language models become more powerful and widespread, these societal impacts will be an important area for further research and discussion.
Conclusion
This paper presents a promising technique for adding learnable linguistic watermarks to large language models. By embedding unique patterns into the model's behavior, the authors enable model owners to trace extraction attempts, even if the model is further refined.
The demonstrated reliability and learnability of this approach make it a valuable tool for defending against model theft and protecting intellectual property. As language models continue to advance, techniques like this will be increasingly important for ensuring the responsible development and deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Watermark for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
0
0
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
5/3/2024
💬
Robust Distortion-free Watermarks for Language Models
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, Percy Liang
0
0
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p leq 0.01$) from $35$ tokens even after corrupting between $40$-$50%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
6/7/2024
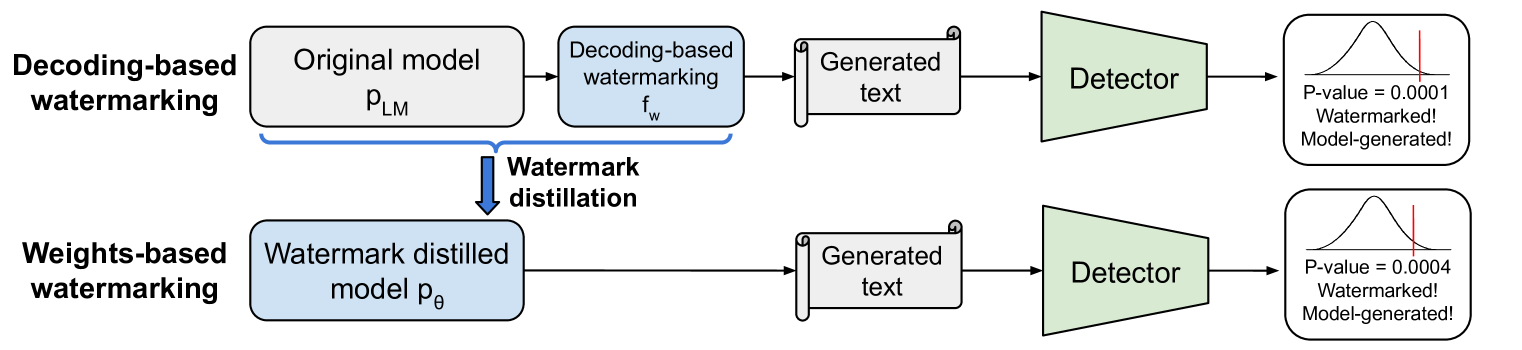
On the Learnability of Watermarks for Language Models
Chenchen Gu, Xiang Lisa Li, Percy Liang, Tatsunori Hashimoto
0
0
Watermarking of language model outputs enables statistical detection of model-generated text, which can mitigate harms and misuses of language models. Existing watermarking strategies operate by altering the decoder of an existing language model. In this paper, we ask whether language models can directly learn to generate watermarked text, which would have significant implications for the real-world deployment of watermarks. First, learned watermarks could be used to build open models that naturally generate watermarked text, enabling watermarking for open models, where users can control the decoding procedure. Second, if watermarking is used to determine the provenance of generated text, an adversary can hurt the reputation of a victim model by spoofing its watermark and generating damaging watermarked text. To investigate the learnability of watermarks, we propose watermark distillation, which trains a student model to behave like a teacher model that uses decoding-based watermarking. We test our approach on three decoding-based watermarking strategies and various hyperparameter settings, finding that models can learn to generate watermarked text with high detectability. We also find limitations to learnability, including the loss of watermarking capabilities under fine-tuning on normal text and high sample complexity when learning low-distortion watermarks.
5/3/2024

A Semantic Invariant Robust Watermark for Large Language Models
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
0
0
Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at href{https://github.com/THU-BPM/Robust_Watermark}{https://github.com/THU-BPM/Robust_Watermark}. Additionally, our algorithm could also be accessed through MarkLLM citep{pan2024markllm} footnote{https://github.com/THU-BPM/MarkLLM}.
5/21/2024